1、开发环境
操作系统:win10 Python 版本:Python 3.5.2 MySQL:5.5.53
2、用到的模块
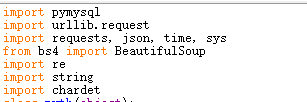
没有的话使用pip进行安装:pip install xxx xxx需要安装的模块
3、分析链接(博客官网:https://www.cnblogs.com/)
这里我们简单分析首页部分
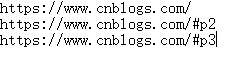
经分析首页的分页系统链接变量是最后一个数字,所以可将访问的链接写成如下模式,这样执行的时候加个循环就能访问需要访问的所有页面内容
![]()
4、分析页面内容
整个页面 咱们需要的信息是博主所发博客的信息,例如:

精确的的说是需要提取博客的标题,简介,发布时间以及博客链接
找到此页面按f12来审查元素
![]()
鼠标点下此箭头,然后放到页面内容上,找到咱们所查找的元素,在下面代码部分会出现相应的html:

鼠标右键,选择copy element,可将这块信息复制到文本,找个文本文档保存下来如下部分代码:

这个内容包含一个博客所有信息,接下来用正则提取我们需要的内容即可
5、正则表达式
title= re.compile('<a class="titlelnk.*?>(.*?)</a>',re.S)
title1= re.findall(title,html)
html是整个网页所有代码文档,这两行代码就将这个网页里面所有博客标题存入title1列表里面
其中<a class="titlelnk.*?>(.*?)</a>是匹配到所有class为titlelnk的a标签,(.*?)是咱们提取的内容
6、链接数据库
db = pymysql.connect("127.0.0.1","root","root","crawler",charset="utf8")#打开数据链接,
pymysql.connect()里面前四个参数我就不多说了,charset="utf8"这个参数可省只是确保编码正确,不然有些环境下无法插入数据
cursor cursor = db.cursor()# 使用 cursor() 方法创建一个游标对象
7、MYSQL插入语句

8、整理代码

原理、代码都在这个,想提取所要内容,分析网站即可,当然并不是所有网站都能爬,特殊网站具有反爬措施,需要学习更多知识(访问频率控制,代理IP池等等)