上期讲到LoadRunner性能测试脚本编写检查函数,这期我们来讲讲Block(块)技术和参数化。
Block(块)技术
在使用LoadRunner时经常遇到这样一个问题,如果对不同的事务进行不同次数的循环该怎么处理?默认情况下LoadRunner对所有的事务都是统一执行的,即虽然有多个事务,但它们被执行的循环次数都是一样的,那么LoadRunner如何在一个脚本中实现不同事务不同次数的循环或不同百分比的循环呢?
案例:假设在一个脚本中,想实现注册执行3次,登录执行1次,查询执行2次,怎么办?录3个脚本?每个事务分别在脚本中复制N次?这样是可以解决问题,但不是最好的解决办法,LoadRunner提供了对业务流程的处理方法,即Block(块)技术。
首先,借用LoadRunner自带的订票系统,录制好这三个脚本,录制结束后,脚本如图所示,包含三个业务:注册,登录和查询。接着,对脚本中的三个业务的迭代次数进行设置,这里使用到的是Block(块)技术。
1.进入菜单Vuser→Run-timeSettings,弹出Run-timeSettings对话框,选择General→RunLogic选项卡.

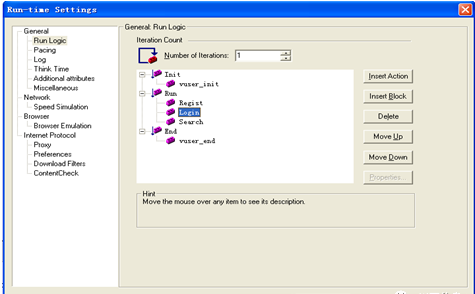
2.选择Run,插入一个Block块,如图所示。
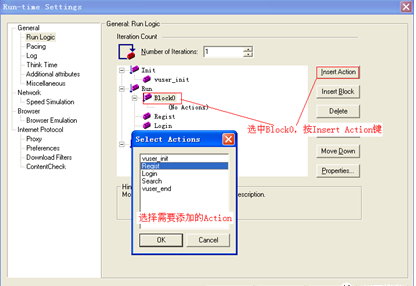
3.选择Block0,点击InsertAction按钮,弹出SelectActions对话框,如图所示,选中要添加的Action,点击OK按钮即可。
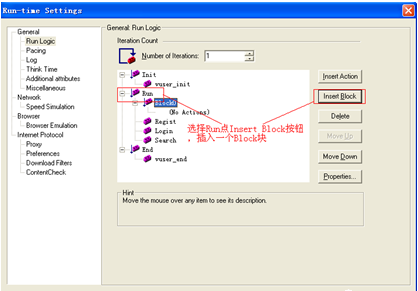
4.重复以上操作,再新建两个Block块,分别为Block1和Block2,并为这两个块插入对应的Action。
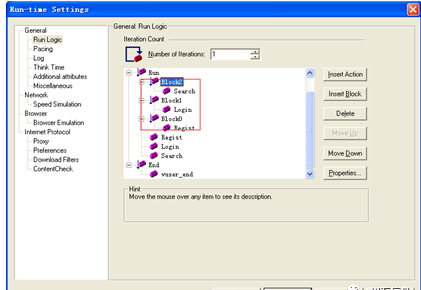
5.将Block外面的Action删除,最后得到如图所示的Block块。
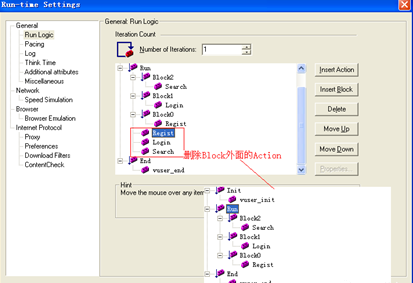
6.设置Block properties。这里有两种选择:Sequential和Random。如果选择Sequential,则可以在下面的Iterations中直接填入数值,那么Block中的Action都会按输入的次数执行。如果选择Random,下面还可以设置Block内各Action执行的百分比。
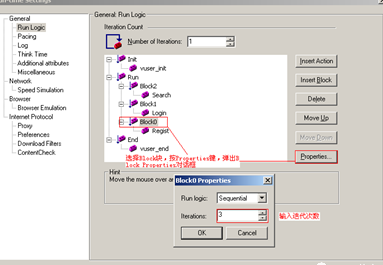
按照前面的案例,只需要设置3个Block,每个Block中分别插入一个Action,设置执行次数分别为3、1、2即可,设置完成后。
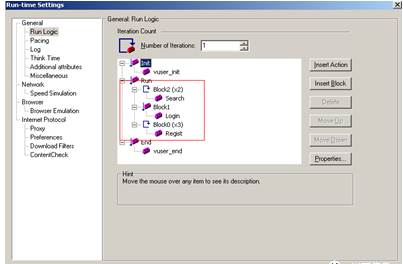
整修Block(块)的设置完成,脚本将按期望的业务模型运行。
值得注意的一点就是业务迭代的总次数=该Block迭代次数×Number of Iterations,如图中Block2中的Search迭代次数为2×1=2次,最终Search这个业务只迭代了2次。
参数化技术
所谓脚本参数化,就是针对脚本中的某些常量,使用参数来取代。参数中包含很多数据源,数据源可以是一个文本文件也可以是数据库。当不同的Vuser在执行相同的脚本时,分别调用参数文件中的数据代替这些常量,从而达到模拟多用户真实使用的目的。
参数化的过程体现了数据驱动的思想,即将测试脚本与测试数据进行分离的思想。脚本体现测试流程,数据体现测试案例。
哪些情况参数化
工作中为什么要进行参数化呢?
1.借助参数化可以减小脚本的数量,如果不进行参数化为了达到目标可能需要拷贝并修改很多个脚本。
2.使业务更接近真实的客户业务,每个虚拟用户使用不同参数值来模拟,这样可以更好地接近客户的实际情况。
在实际工作中一般以下情况需要进行参数化:
日期时间
如这类业务,需要订一张机票,那么订票的日期一定是当前日期之后,不可能是当前时间之前的日期,如当前系统时间为2012年8月20日,那么订票时一定需要使用20日后期的日期(如订25日的机票),但是如果到25日之后再来回放该脚本时,还是发现脚本无法正常使用,所以对于这类情况需要参数化。
唯一性约束
唯一性约束是指在数据库中对于主键必须是唯一的,如果一直使用相同数据提交业务,那么业务将无法完成。如注册业务,就不能使用相同的数据就行注册,因为数据库中会把注册用户的ID做为主键,这样在测试过程中就必须进行参数化,否则业务无法成功。
数据约束
数据约束是指在测试过程中要求提交的业务数据必须是每次都不同,如果提交业务中的数据一致,那么业务将失败。例如银行业务,一些银行业务是以报文的方式发送的,在发送报头时,后面一般会接一个6位的动态码,那么这个动态码就必须每次都不一样,如果写成一样,那么银行交易业务将会失败,所以对于这类数据必须进行参数化。
缓存数据约束
在谈缓存数据约束之前,必须先了解数据库查询的过程,数据库在查询时首先使用查询条件在数据库进行查询,查询结束后,系统需要将查询到的结果显示在页面中,那么显示时需要先将查询到的结果从硬盘中读取之出,读取后将数据从硬盘读到内存,再从内存读到缓存,最后将缓存中的数据发送到处理器中进行处理。
但是有一种特殊情况,如果每次使用的查询条件一致时,数据库中查询到的结果就是一致的,那么需要处理的数据直接已经存储在缓存中,这样系统就不需要从硬盘将数据读到缓存,而直接将缓存中的数据传输到处理器中进行处理,这样就节约了从硬盘读到数据到缓存中的时间,而整个查询过程中时间消耗最多的恰好是从硬盘到缓存的时间,所以这样测试出来的时间不是真实的时间,这些就出现缓存数据约束,所以这种情况也需要进行参数化。