Navicat数据库远程管理软件使用说明
1:Navicat介绍
Navicat 是一套安装在PC上的 MySQL 数据库系统远程管理及开发工具。它不仅适合资深的专业研发者,也适合新手轻松的学习。由于Navicat友善的图形化使用接口, 用户可以快速且简易的建立、查询、组织、存取,并在安全及方便的环境下共享信息。
2:Navicat的使用方式
2.1:Navicat建立联机(Connection)的方式
1. 点选Connection按钮出现联机画面。
2. 输入欲命名之远程主机名(Connection Name)。
3. 输入主机名(Host name)或地址(IP address),以及端口(Port),端口预设是3306。
4. 输入用户名称(User name)与密码(Password),如希望储存密码,在下方的Save Password选项打勾。
5. 若想之前输入的资料是否能成功联机,可以按下测试按钮(Test connection)做确定。
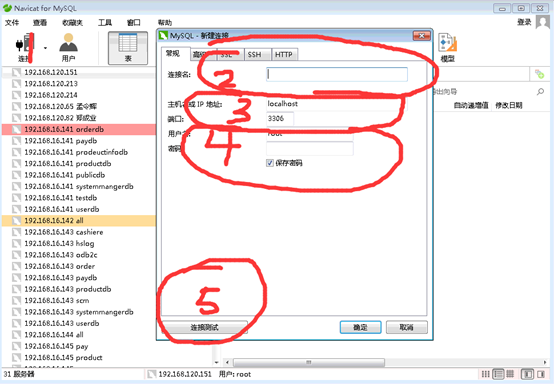
图1在Navicat上建立联机
若测试成功,会出现Connection Successful(测试成功)讯息窗口(如图2),之后按下“ok”钮即完成初步的联机设定。

图2联机成功
2.2:Navicat联机设定方式。
6. 切换到同一窗口的高级页面做进阶设定。
7. 勾选使用高级链接列出所有数据库的列表。
8. 当所有数据库名称出现之后,选取这个Connection联机时想要连接的数据库,如果之前输入的账号密码没有存取该数据库的权限,需在勾选该数据库后,在窗口右下角另外输入存取的账号密码。
9. 选取“OK”按钮表示设定完成。
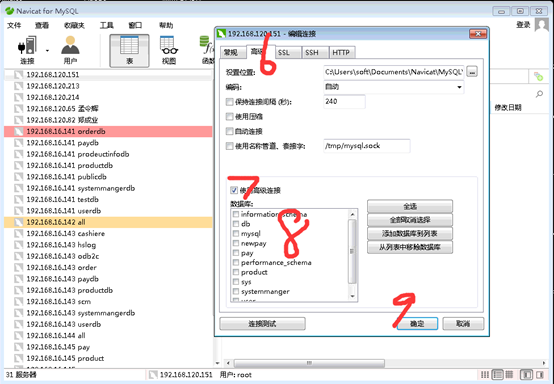
图3进阶设定
2.3:Navicat联机后的使用。
左边Connections区域会出现刚刚设定之联机名称,按鼠标右键出现选单,选择“Open Connection(打开联机)”,就会连接上设定之主机地址。
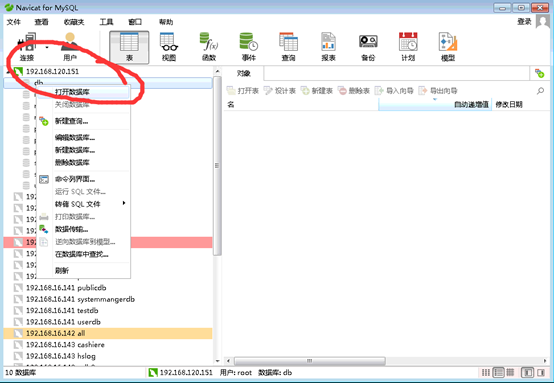
图4开始联机
接下来会出现所连接的数据库名称,其树形图下层分别是:Tables(数据表)、Views(检视)、Stored Procedure(存储过程)、Queries(查询)、Reports(报表)、Backups(备份)。(如图5)
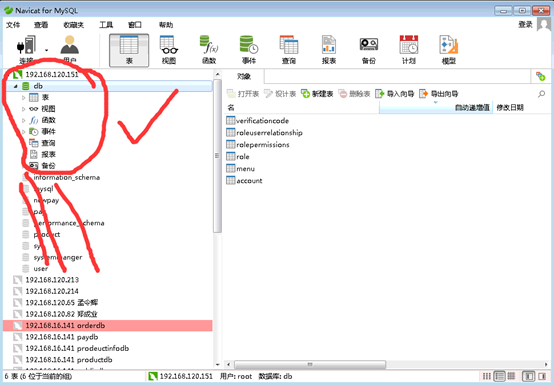
图5主机画面
若需新增数据表,可以在Connections区域之窗体中,选择“Tables”选项。点选“新建表”按钮新增数据表。(如图6)
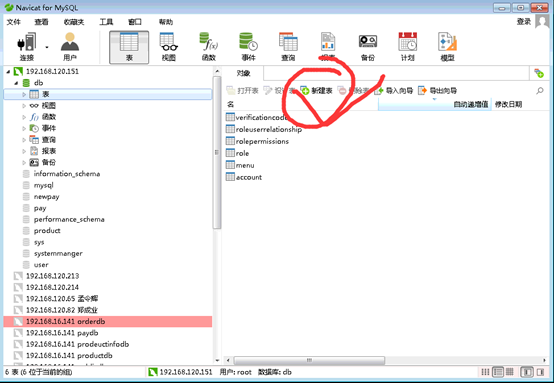
图6新增数据表
此时会出现“表设计”画面提供数据表设计功能,用户可以开始设计数据表的字段。名为列名,Type为字段类型(用下拉式选单选取),Length为字段长度,不是null勾选表示字段的内容可以空白。不是null右边的空格若按下,会出现一个黄色的钥匙,表示将该字段指定为主索引。当字段的类型为数字型态时,下方会出现一个自增长的选项,勾选表示域值为自动增加。设计完毕后点选“保存”可以储存,并为数据表命名(如图7)。

图7数据表设计
建立好数据表后,如图8,主画面会出现该数据表名称数据笔数(Rows)、更新时间(Update Time)等相关数据。
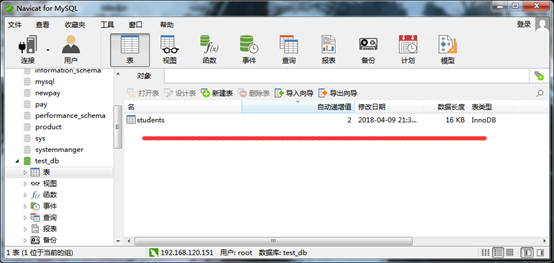
图8数据表画面
在数据表名称上右键单击会出现一个右键菜单,我们将其中各选项的意义简单列在图9中。例如,若选取“Open Table”,会开启该数据表,使用者可以输入数据表各字段的内容。(图10)
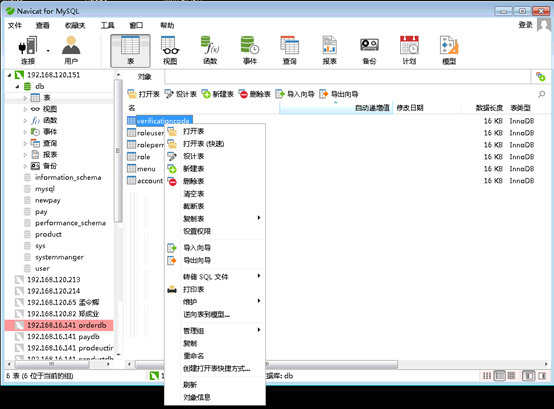
图9 开启数据表
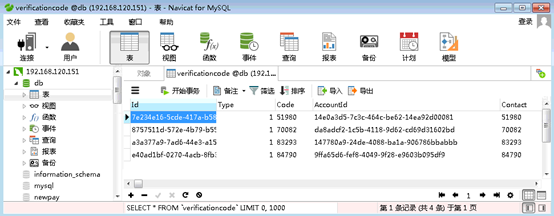
图10 建立数据表内容
数据库操作使用说明
3:创建数据库
使用 create database 语句可完成对数据库的创建, 创建命令的格式如下:
create database 数据库名 [其他选项];
例如我们需要创建一个名为 test_db 的数据库, 在命令行下执行以下命令:
create database test_db character set utf8;
为了便于在命令提示符下显示中文, 在创建时通过 character set utf8 将数据库字符编码指定为 utf8。创建成功时会得到
[SQL]create database test_db character set utf8;
受影响的行: 1
时间: 0.002s
注意: MySQL语句以分号(;)作为语句的结束, 若在语句结尾不添加分号时, 命令提示符会以 -> 提示你继续输入(有个别特例, 但加分号是一定不会错的);
提示: 可以使用 show databases; 命令查看已经创建了哪些数据库。
4:选择所要操作的数据库
要对一个数据库进行操作, 必须先选择该数据库, 否则会提示错误:
No database selected
两种方式对数据库进行使用的选择:
一: 在登录数据库时指定, 命令:
例如登录时选择刚刚创建的数据库:
二: 在登录后使用 use 语句指定, 命令: use 数据库名;
use 语句可以不加分号, 执行 use test_db 来选择刚刚创建的数据库, 选择成功后会提示:
[SQL]use test_db
受影响的行: 0
时间: 0.001s
5:创建数据库表
使用 create table 语句可完成对表的创建, create table 的常见形式:
create table 表名称(列声明);
以创建 students 表为例, 表中将存放 学号(id)、姓名(name)、性别(sex)、年龄(age)、联系电话(tel) 这些内容:
create table students
(
id int unsigned not null auto_increment primary key,
name char(8) not null,
sex char(4) not null,
age tinyint unsigned not null,
tel char(13) null default "-"
);
语句解说:
create table tablename(columns) 为创建数据库表的命令, 列的名称以及该列的数据类型将在括号内完成;
括号内声明了5列内容, id、name、sex、age、tel为每列的名称, 后面跟的是数据类型描述, 列与列的描述之间用逗号(,)隔开;
以 "id int unsigned not null auto_increment primary key" 行进行介绍:
- "id" 为列的名称;
- "int" 指定该列的类型为 int(取值范围为 -8388608到8388607), 在后面我们又用 "unsigned" 加以修饰, 表示该类型为无符号型, 此时该列的取值范围为 0到16777215;
- "not null" 说明该列的值不能为空, 必须要填, 如果不指定该属性, 默认可为空;
- "auto_increment" 需在整数列中使用, 其作用是在插入数据时若该列为 NULL, MySQL将自动产生一个比现存值更大的唯一标识符值。在每张表中仅能有一个这样的值且所在列必须为索引列。
- "primary key" 表示该列是表的主键, 本列的值必须唯一, MySQL将自动索引该列。
下面的 char(8) 表示存储的字符长度为8, tinyint的取值范围为 -127到128, default 属性指定当该列值为空时的默认值。
更多的数据类型请参阅 《MySQL数据类型》 : http://www.cnblogs.com/zbseoag/archive/2013/03/19/2970004.html
提示: 1. 使用 show tables; 命令可查看已创建了表的名称; 2. 使用 describe 表名; 命令可查看已创建的表的详细信息。
6:操作MySQL数据库
6.1:向表中插入数据 (增)
insert 语句可以用来将一行或多行数据插到数据库表中, 使用的一般形式如下:
insert into 表名 (列名1, 列名2, 列名3, ...) values (值1, 值2, 值3, ...); 字段和值一定要用括号括起来;
其中 [] 内的内容是可选的, 例如, 要给 test_db 数据库中的 students 表插入一条记录, 执行语句:
insert into students values(NULL, "王刚", "男", 20, "13811371377");
按执行键确认后若提示
[SQL]insert into students values(NULL, "王刚", "男", 20, "13811371377");
受影响的行: 1
时间: 0.046s
表示数据插入成功。 若插入失败请检查是否已选择需要操作的数据库。
有时我们只需要插入部分数据, 或者不按照列的顺序进行插入, 可以使用这样的形式进行插入:
insert into students (name, sex, age) values("孙丽华", "女", 21);
6.2:查询表中的数据 (查)
select 语句常用来根据一定的查询规则到数据库中获取数据, 其基本的用法为:
select 列名称 from 表名称 [查询条件];
例如要查询 students 表中所有学生的名字和年龄, 输入语句 select name, age from students; 执行结果如下:
也可以使用通配符 * 查询表中所有的内容, 语句: select * from students;
6.3:按特定条件查询:
where 关键词用于指定查询条件, 用法形式为: select 列名称 from 表名称 where 条件;
以查询所有性别为女的信息为例, 输入查询语句: select * from students where sex="女";
where 子句不仅仅支持 "where 列名 = 值" 这种名等于值的查询形式, 对一般的比较运算的运算符都是支持的, 例如 =、>、<、>=、<、!= 以及一些扩展运算符 is [not] null、in、like 等等。 还可以对查询条件使用 or 和 and 进行组合查询, 以后还会学到更加高级的条件查询方式, 这里不再多做介绍。
示例:
查询年龄在21岁以上的所有人信息: select * from students where age > 21;
查询名字中带有 "王" 字的所有人信息: select * from students where name like "%王%";
查询id小于5且年龄大于20的所有人信息: select * from students where id<5 and age>20;
6.4: 连接查询
连接查询的意义: 在用户查看数据的时候,需要显示的数据来自多张表.
连接查询: join, 使用方式: 左表 join 右表;左表: 在join关键字左边的表;右表: 在join关键字右边的表.
连接查询分类:SQL中将连接查询分成四类: 内连接,外连接,自然连接和交叉连接
6.4.1:内连接
[inner] join, 从左表中取出每一条记录,去右表中与所有的记录进行匹配: 匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留.
基本语法:左表 [inner] join 右表 on 左表.字段 = 右表.字段; on表示连接条件: 条件字段就是代表相同的业务含义(如student.id和class.id)
SELECT * from students s INNER JOIN students s1 on s.id=s1.id; 执行结果
如下:
6.4.2:外连接
以某张表为主,取出里面的所有记录, 然后每条与另外一张表进行连接: 不管能不能匹配上条件,最终都会保留: 能匹配,正确保留; 不能匹配,其他表的字段都置空NULL.
外连接分为两种: 是以某张表为主: 有主表
left join: 左外连接(左连接), 以左表为主表
right join: 右外连接(右连接), 以右表为主表
基本语法: 左表 left/right join 右表 on 左表.字段 = 右表.字段;
SELECT * from students s LEFT/RIGHT JOIN students s1 on s.id=s1.id;
行结果如下:
6.4.3:自然连接
略
6.4.4:交叉连接
略
6.5:联合查询
联合查询:将多次查询(多条select语句), 在记录上进行拼接(字段不会增加)
基本语法:多条select语句构成: 每一条select语句获取的字段数必须严格一致(但是字段类型无关)
SELECT * from students
UNION ALL/ DISTINCT
SELECT * from students;
结果如下:
7.5:更新表中的数据 (改)
update 语句可用来修改表中的数据,基本的使用形式为:
update 表名称 set 列名称=新值 where 更新条件;
使用示例:
将id为5的手机号改为默认的"-": update students set tel=default where id=5;
将所有人的年龄增加1: update students set age=age+1;
将手机号为 13288097888 的姓名改为 "张伟鹏", 年龄改为 19: update students set name="张伟鹏", age=19 where tel="13288097888";
6.6:删除表中的数据 (删)
delete 语句用于删除表中的数据, 基本用法为:
delete from 表名称 where 删除条件;
使用示例:
删除id为2的行: delete from students where id=2;
删除所有年龄小于21岁的数据: delete from students where age<20;
删除表中的所有数据: delete from students;
7:创建后表的修改
alter table 语句用于创建后对表的修改, 基础用法如下:
7.1:添加列
基本形式: alter table 表名 add 列名 列数据类型 [after 插入位置];
示例:
在表的最后追加列 address: alter table students add address char(60);
在名为 age 的列后插入列 birthday: alter table students add birthday date after age;
7.2:修改列
基本形式: alter table 表名 change 列名称 列新名称 新数据类型;
示例:
将表 tel 列改名为 telphone: alter table students change tel telphone char(13) default "-";
将 name 列的数据类型改为 char(16): alter table students change name name char(16) not null;
7.3:删除列
基本形式: alter table 表名 drop 列名称;
示例:
删除 birthday 列: alter table students drop birthday;
7.4:重命名表
基本形式: alter table 表名 rename 新表名;
示例:
重命名 students 表为 workmates: alter table students rename workmates;
7.5:删除整张表
基本形式: drop table 表名;
示例: 删除 workmates 表: drop table workmates;
7.6:删除整个数据库
略;
作者太难了给作者点辛苦费吧
