周一,晴,记录生活分享点滴
参考博客1:https://www.cnblogs.com/alex3714/articles/5717620.html
参考博客2:https://www.cnblogs.com/yuanchenqi/articles/5938733.html
Python版本:3.5
三级菜单
menu = { "河北省":{ "石家庄市":{ "正定县":{}, "桥西区":{}, }, "保定市":{ "莲池区":{}, "徐水区":{}, }, }, "吉林省":{ "长春市":{ "朝阳区":{}, "绿园区":{}, }, "吉林市":{ "丰满区":{}, "船营区":{}, }, } } current_layer = menu #实现动态循环 parent_layers = [] #保存所有父级,最后一个元素永远都是父亲级 while True: for key in current_layer: print(key) choice = input(">>>:").strip() if len(choice) == 0: continue if choice in current_layer: parent_layers.append(current_layer) #在进入下一层之前,把当前层(也就是下一层父级)追加到列表中。下一次loop,当用户选择b的选项,就可以直接取到列表的最后一个值出来就可以了 current_layer = current_layer[choice] #改成了子层 elif choice == "b": if parent_layers: #[] current_layer = parent_layers.pop() #取出列表的最后一个值,因为它就是当前层的父级 else: print("无此项")
小结:
- 标志位,即
- current_layer = menu
- parent_layers = []
- .strip()
- 用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
- 只能删除开头或是结尾的字符,不能删除中间部分的字符。
- len()
- 返回对象(字符、列表、元组等)长度或项目个数
- .append()
- 在列表末尾添加新的对象
- .pop()
- 删除字典给定键 key 及对应的值,返回值为被删除的值。key 值必须给出。 否则,返回 default 值
编码解码
in python2
默认是 ASCII
py2数据类型:str:bytes、unicode:unicode
- 打印结果是明文,一定是unicode
- 可以在ASCII表内拼接,在内部做了转换,把bytes转成了unicode
- str = bytes
py2中首行的 coding:utf8 ,告诉解释器说编码解码按utf8的形式去搞,前提是本身的文本是utf8的(GBK同理)
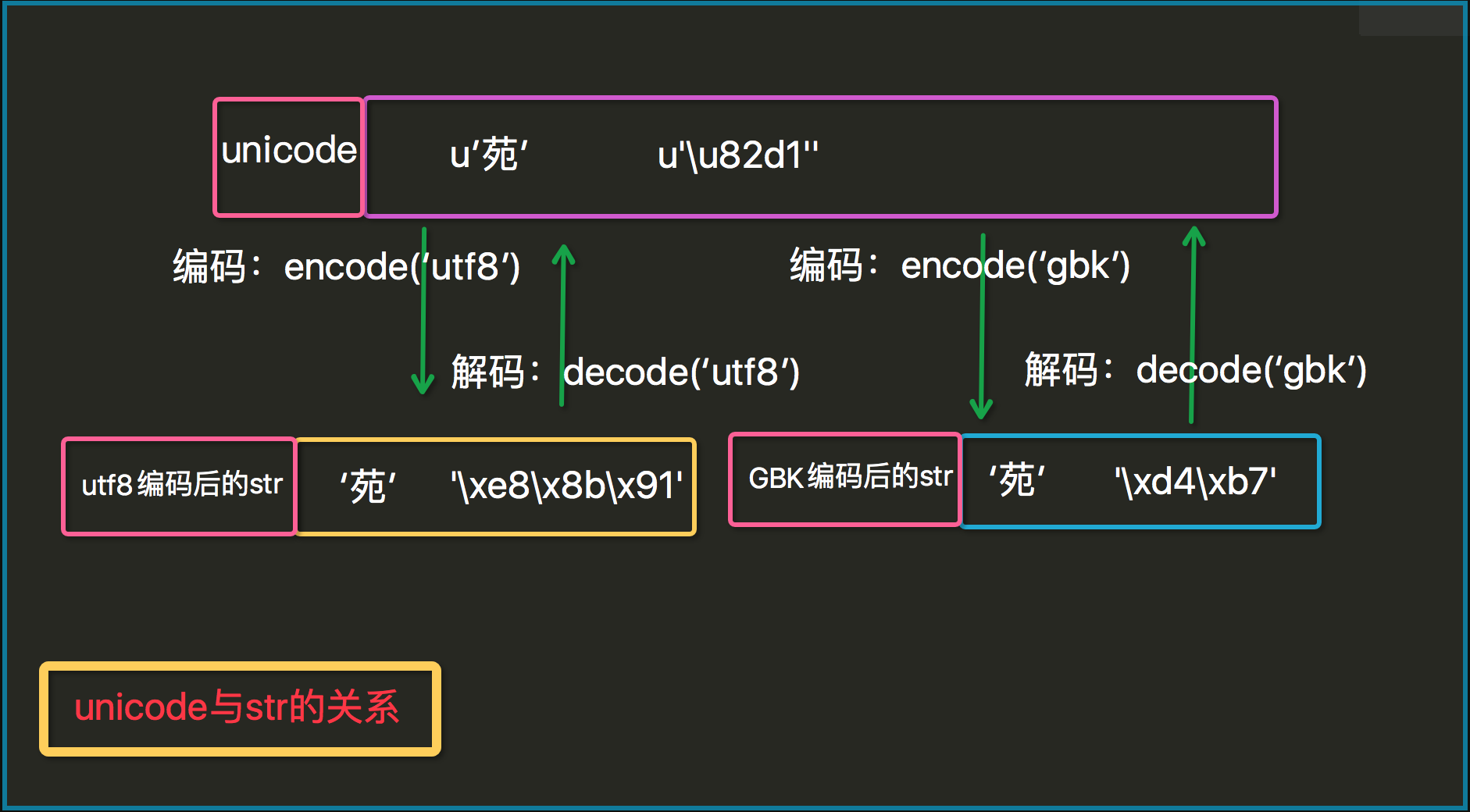
#python 2 s = "虫儿飞" s_to_unicode = s.decode("utf-8") unicode_to_gbk = s_to_unicode.encode("gbk") print(s) print("unicode:",s_to_unicode) print("gbk:",unicode_to_gbk) gbk_to_unicode =unicode_to_gbk.decode("gbk") #unicode_to_gbk.decode() unicode_to_utf8 = gbk_to_unicode.encode("utf-8") print(gbk_to_unicode) print(unicode_to_utf8)
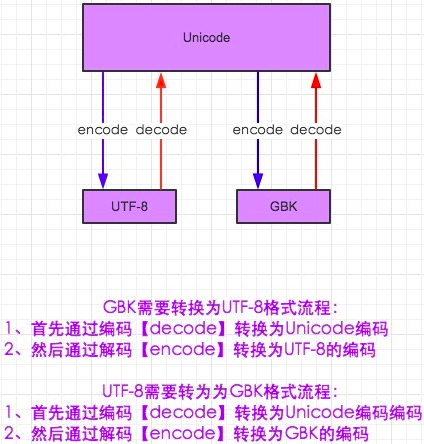
in python3
默认是 unicode
- encode 在编码的同时,会把数据从 string 转成 bytes 类型
- decode 在解码的同时,会把数据从 bytes 转成 string 类型,即字符串
- b = byte = 字节类型 = [ 0-255 ]
str = unicode
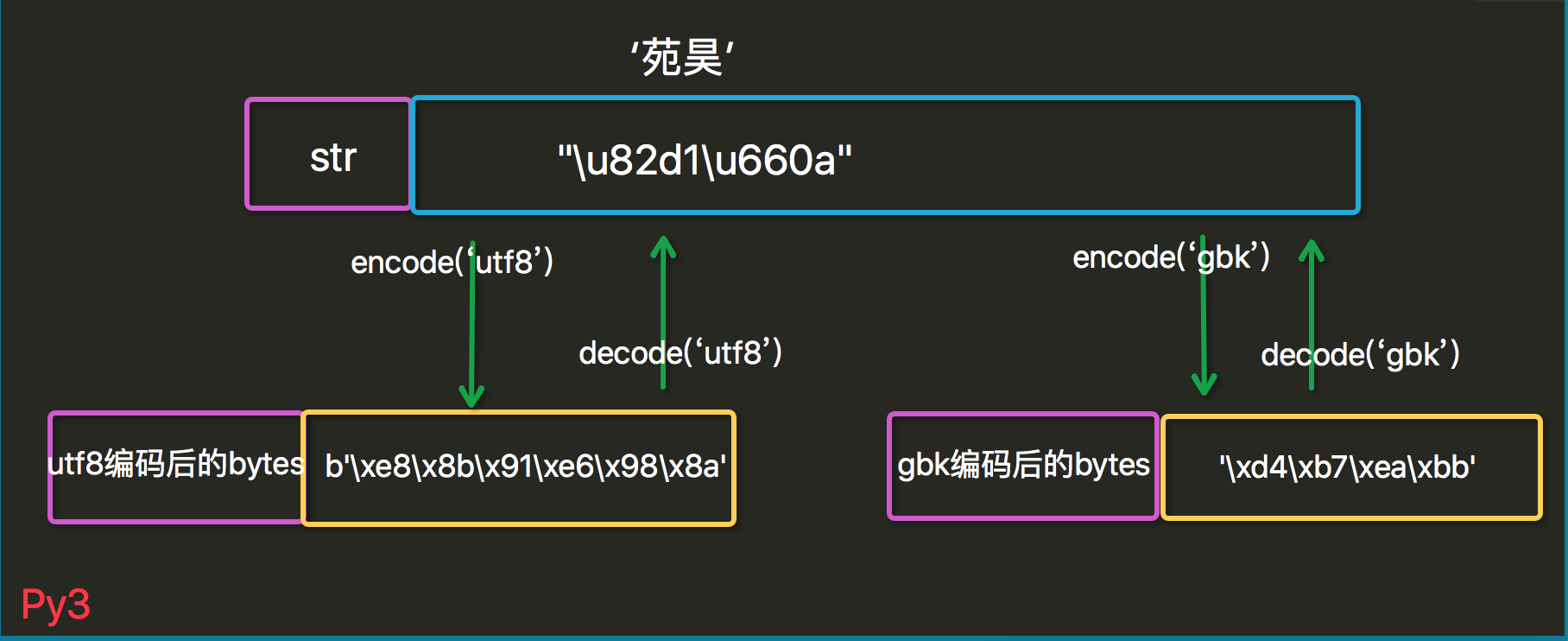
#python 3 s = "I am 虫儿飞ZZZZZC." s_to_gbk = s.encode("gbk") print(s) print(s_to_gbk) #在编码的同时,把数据转成bytes类型 print(s_to_gbk.decode("gbk")) #在解码的同时,会把bytes类型转成字符串
编码解码方式
s = '你好' b = bytes(s, 'utf8') # 编码,等同于 b = s.encode('utf8') ss = str(b, 'utf8') # 解码,等同于 ss = b.decode('utf8')
文件的编码方式与解释器的需一致