TaskSchedulerImpl概述
TaskSchedulerlmpl是创建三大核心TaskSheduler的实现类,TaskScheduler是一个特征类,DAGScheduler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler,这符合面向对象中依赖抽象而不依赖具体的原则,带来底层资源调度器的可插拔性,导致Spark可以运行众多的资源调度器模式上,例如Standalone,Yarn,Mesos,Local,EC2,其他自定义的资源调度器。
TaskScheduler获取集群的资源。TaskScheduler从高层调度器DAGScheduler获得每个Task一系列任务的集合。负责把任务task发送给集群。如果失败重新尝试。返回具体的events事件给DAGScheduler汇报。
我们以Standalone模式为例,聚焦于TaskSchedulerImpl。
初始构造
构造流程如下:
1.通过读取sparkConf的配置信息,来初始化一些配置。
spark.task.maxFailures:默认最大task失败尝试是4次。
spark.speculation.interval :task任务检查频率 100ms。
speculationScheduler :推测调度。
spark.starvation.timeout: 饥饿超时时间,大于15s发出警告。
spark.task.cpus: 每个task请求的cpu数量,默认是1。

taskSets和stage的关系,task和TaskSetManger的关系,task和Executor的关系。
hasReceivedTask :已经接受的task false。
hasLaunchedTask :已经启动的task false。
nextTaskId :下一个taskid。
executorIdToTaskCount :每个执行者上总共的task数量。
protected val executorsByHost = new HashMap[String, HashSet[String]]。
protected val hostsByRack = new HashMap[String, HashSet[String]]。
protected val executorIdToHost = new HashMap[String, String]。
var dagScheduler: DAGScheduler = null :dag调度这初始化。
var backend: SchedulerBackend = null backend :初始化。
val mapOutputTracker = SparkEnv.get.mapOutputTracker : map输出追综者。
var schedulableBuilder: SchedulableBuilder = null :调度树建造者初始化。
var rootPool: Pool = null :根节点。
schedulingModeConf:调度方式 ,默认是 fifo。调度模式有FAIR和FIFO两种模式,任务的最终调度实际都是落实到接口SchedulerBackend的具体实现上的。
2.创建TaskResultGetter()
运行一个线程池,该线程池对任务结果进行反序列化和远程提取(如果需要)。
根据SchedulerBackend适配器初始创建

根据代码可以看出,TaskScheduler的创建需要依赖SchedulerBackend(Standalone)这个资源适配器的。
scheduler.initialize(backend)传入的参数backend。
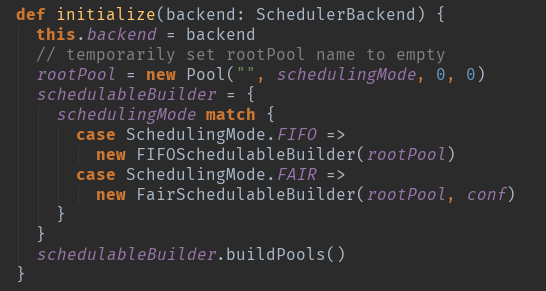
这个地方有两个重要的变量进行创建了,
一个是调度池配置创建roolPool:这个地方主要是初始化资源调度的模式,初始化调度算法。
一个是调度树的创建schedulableBuilder:这个地方主要是创建调度树,对taskSetManger进行调度管理。
TaskSchedulerImpl.submitTasks:主要的作用是将TaskSet加入到TaskSetManager
SchdulableBuilder.addTaskSetmanager:SchdulableBuilder会确定TaskSetManager的调度顺序,然后按照TaskSetManager来确定每个Task具体运行在哪个ExecutorBackend中。
rootpool创建
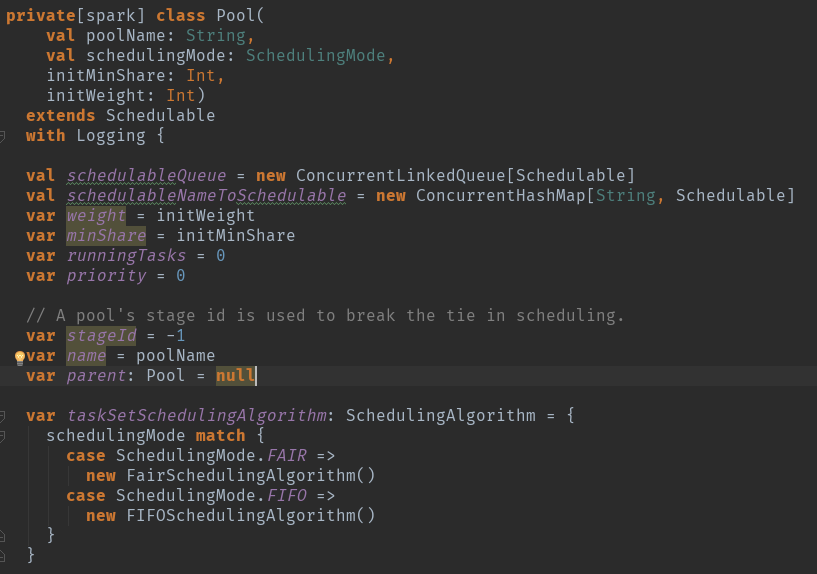
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable] 调度队列
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable] 调度对应关系
var weight = initWeight 调度池权重
var minShare = initMinShare 计算资源中的cpu核数
var runningTasks = 0 正在运行的task数量
var priority = 0 优先级
var stageId = -1 池的阶段id用于在调度中中断绑定
var name = poolName 调度池名字
var parent: Pool = null
调度算法,根据调度模式初始化算法。org.apache.spark.scheduler.SchedulingAlgorithm。
调度池则用于调度每个sparkContext运行时并存的多个互相独立无依赖关系的任务集。
调度池负责管理下一级的调度池和TaskSetManager对象。
用户可以通过配置文件定义调度池和TaskSetManager对象。
1.调度的模式Scheduling mode:用户可以设置FIFO或者FAIR调度方式。
2.weight,调度的权重,在获取集群资源上权重高的可以获取多个资源。
3.miniShare:代表计算资源中的cpu核数。
配置conf/faurscheduler.xml配置调度池的属性,同时要在sparkConf对象中配置属性。
SchedulableBuilder创建
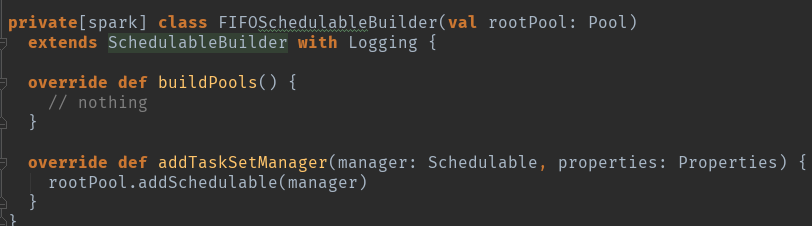
可以看到在FIFO的模式下buildPool基本上没干啥,主要是addTaskSetManager是连接TaskSetManager和资源调度池的桥梁。