简介
-
Docker发布Docker Swarm,架构优秀,但是功能简单,不能完全符合市场需求
-
Google发布Go语言开发的开源Kubernetes项目,参考Borg系统开发,技术成熟,功能强大,使用简单
-
Kubernetes简称k8s,架构如下图所示:
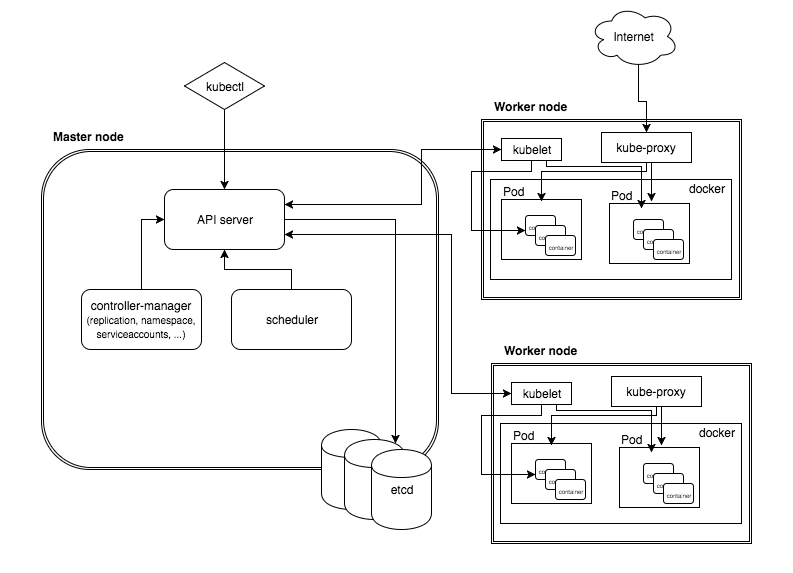
组件介绍
-
API-Server:整个集群的核心,基本上所有的组件都需要和API-Server进行交互,也是外界访问Kubernetes的唯一入口
-
Etcd:键值对分布式数据库,集群中所有的重要信息都存储在其中
-
Schedular:调度器,负责调度Pod到那个节点上运行
-
Controller:控制器,主要是对Pod进行控制
-
Kubelet:从节点上负责与主节点上的API-Server进行交互的组件,同时负责与本节点的容器进行通信
-
Kube-Proxy:用来转发service中定义的服务,实现外部可以访问集群内的服务
-
Flanner:一种覆盖网络,实现集群内Pod之间的通信
-
DNS:域名解析服务(高版本默认安装)
-
Dashboard:基于网页的Kubernetes用户界面,用于实时查看集群的内部状态
-
Helm:服务安装工具,类似Centos上的yum,python中的pip,方便高效
-
EFK:日志查看工具
控制器
-
Replication Controller:用于控制副本的个数,是的副本个数始终等于期望的个数。
-
Replication Set:是Replication Controller的升级版本,包含Replication Controller的全部功能,新增基于Label selector的集合操作。
-
Deployment:新增组件,通过控制Replication Set的方式控制副本数,主要是新增升级和回滚功能。升级的大概流程:创建一个新的RS,控制老的RS杀死一个副本,控制新的RS创建一个副本,依次循环,直到所有的老副本都变成新副本,然后杀死老的RS。回滚也是相同的流程,可以把回滚理解成升级的目标版本是老版本。
-
StatefulSet:主要是处理有状态服务,目前是Kubernetes的短板。无状态:如流水线上的工人可以随时离开一段时间,回来后可以继续无缝连接工作;有状态:部门开发经理离开一段之后,再回来工作可能就不能跟上节奏了,因为项目的状态在实时更新,对比服务,最明显的例子就是数据库服务。
-
Daemon Set:保证每个节点上都运行一个Pod,主要适用于日志采集和性能监控服务
-
Job:保证任务执行一次且成功结束,相比于手动执行任务,Job的优势是如果任务异常结束,会被重新执行,直到成功结束
-
Corn Job:周期性定时运行任务
Flanner网络
Flannel实质上是一种“覆盖网络(overlay network)”,在现有的网络上实现另外一层网络,主要是将需要发送的报文通过UDP的方式封装,然后通过真实的网卡传输,在目的端解封得到传输的报文,最后根据传输的报文将报文发送给指定IP的Pod。需要注意的是:这里传输的数据是TCP/TCMP/UDP等格式的报文。宏观上理解是:在应用层上定义一种私有协议,实现多主机上的点对点传输,只不过这种私有协议是TCP/TCMP/UDP等。
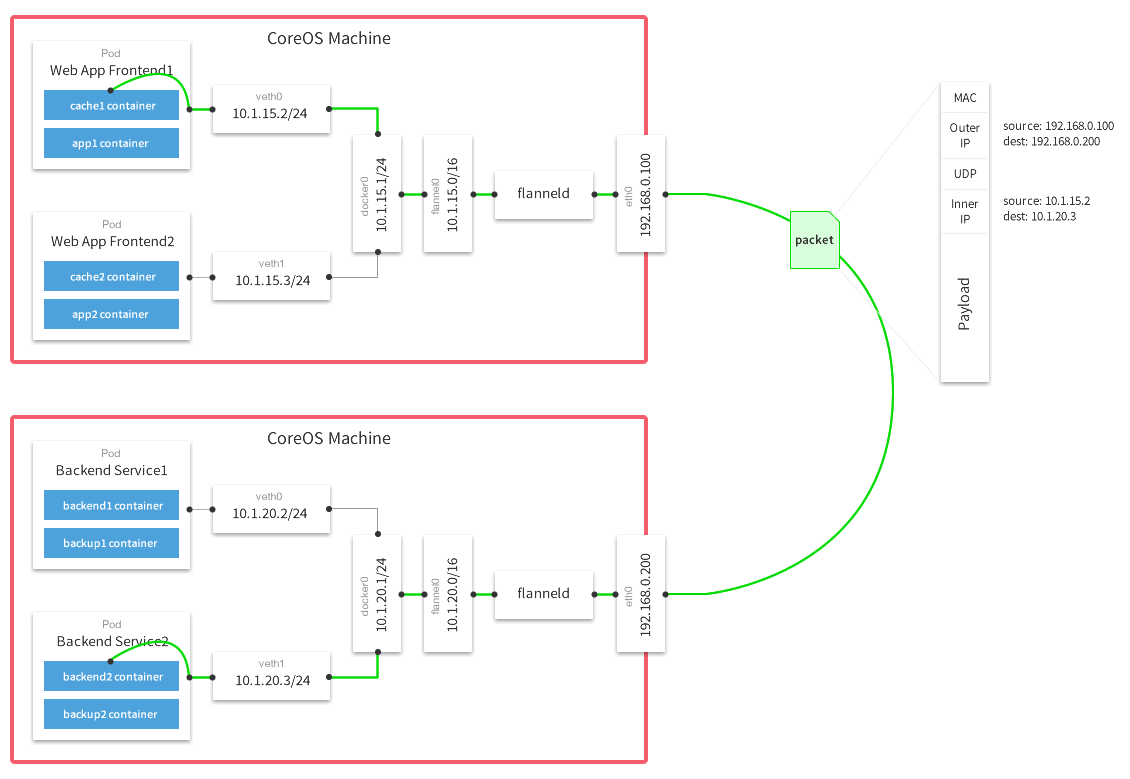
处理流程:数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡(桥接方式),这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。Flannel通过Etcd服务维护了一张节点间的路由表,详细记录了各节点子网网段。源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容器。flannel0虚拟网卡的作用就是UDP封装和解封,在容器层面感知不到,就像直接Socket通信一样。控制容器的的IP地址,是通过设置容器的启动参数--bip实现。
Pod
-
Pod是Kubernetes中能够创建和部署的最小单元,一个Pod中可能包含一个或多个容器,属于同一个Pod的所有容器共享一个IP,且数据卷也是共享,彼此之间通过localhost就可以通信。Pod可以分为两种:自主式Pod和控制器管理的Pod。
-
所有的Pod在启动时会默认创建一个pasue的容器,然后里面的其他容器共享pause的网络协议栈,达到IP相同的目的
-
Kubernetes为什么不将容器当做调度的最小单元?
-
Pod需要和ApiServer进行通信,包括交互探测到的容器健康状态,如果直接将具体的容器当做调度单元管理,那么需要针对具体的容器类型进行开发,非常麻烦。启用pod之后,直接在Pod里面进行差异化开发,对ApiServer统一接口。基本思想就是增加一层,解决差异化。
-
大多数时候,一个业务的建立需要多个容器联合完成,将彼此管理的多个容器一起调度更加合适
-
-
Pod的状态
-
Pending:Pod已被Kubernetes系统接受,但尚未创建一个或多个Container
-
Running:Pod已绑定到节点,并且已创建所有Container
-
Succeeded:Pod中的所有容器都已成功终止,并且不会重新启动
-
Failed:Pod中的所有容器都已终止,并且至少有一个Container已终止失败
-
Unknown:由于某种原因,无法获得Pod的状态

资源
-
空间名称级别
-
工作负载型:Pod,RC,RS,Deployment,StatefulSet,DaemonSet,Job,CronJob
-
服务发现型:Service,Ingress
-
存储型:Volume,CSI(容器存储统一接口,标准)
-
特殊型存储卷:ConfigMap(当配置中心使用的资源类型),Secret(保存敏感数据),DownwardAPI(外部信息输入给容器)
-
-
集群级别
-
Namespace,Node,Role,ClusterRole,RoleBinding,ClusterRoleBinding
-
-
元数据型
-
HPA,PodTemplate,LimitRange
-
理解成有一定指标的东西
-
- Kubernetes中所有的内容都可以抽象为资源,资源实例化之后(理解为被执行),叫做对象
yaml格式
YAML语言的设计目标是方便人类读写。它实质上是一种通用的数据串行化格式。它的基本语法规则如下:
-
大小写敏感
-
使用缩进表示层级关系
-
缩进时不允许使用Tab键,只允许使用空格
-
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
-
#表示注释,从这个字符一直到行尾,都会被解析器忽略
YAML支持的数据结构有三种:
-
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
-
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
-
纯量(scalars):单个的、不可再分的值
对象:对象的一组键值对,使用冒号结构表示
animal: pets
hash: { name: Steve, foo: bar }
数组:一组连词线开头的行,构成一个数组
animal: - Cat - Dog - Goldfish animal: [Cat, Dog]
纯量:纯量是最基本的、不可再分的值。以下数据类型都属于 JavaScript 的纯量:
-
字符串
-
布尔值
-
整数
-
浮点数
-
Null
-
时间
-
日期
number: 12.30 isSet: true iso8601: 2001-12-14t21:59:43.10-05:00 date: 1976-07-31
字符串:字符串是最常见,也是最复杂的一种数据类型。
-
字符串默认不使用引号表示
-
如果字符串之中包含空格或特殊字符,需要放在引号之中
-
单引号和双引号都可以使用,双引号不会对特殊字符转义
-
单引号之中如果还有单引号,必须连续使用两个单引号转义
-
字符串可以写成多行,从第二行开始,必须有一个单空格缩进。换行符会被转为空格
-
多行字符串可以使用
|保留换行符,也可以使用>折叠换行 -
+表示保留文字块末尾的换行,-表示删除字符串末尾的换行
str: 这是一行字符串
str: '内容: 字符串'
str: 'labor''s day'
this: |
Foo
Bar
that: >
Foo
Bar
#{ this: 'Foo
Bar
', that: 'Foo Bar
' }
str: 这是一段
多行
字符串
#{ str: '这是一段 多行 字符串' }
s1: |
Foo
s2: |+
Foo
s3: |-
Foo
#{ s1: 'Foo
', s2: 'Foo
', s3: 'Foo' }
yaml常用字段
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略
#Alawys表示总是下载镜像
#IfnotPresent表示优先使用本地镜像,本地没有就下载镜像
#Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录,进入容器的起始目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器
#检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略
#Always表示一旦不管以何种方式终止运行,kubelet都将重启
#OnFailure表示只有Pod以非0退出码退出才重启
#Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上
#以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
# 一个简单的Pod定义
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
name: my-pod
version: v1
spec:
containers:
- name: one
image: nginx
ports:
- containerPort: 80
- name: two
image: jcdemo/flaskapp
ports:
- containerPort: 5000
Pod生命周期
-
启动pause容器,每个Pod默认具有,主要是初始化网络和数据卷
-
pause串行启动初始化容器(initC),只到所有的初始化容器都成功执行
-
pause并行启动主容器(mainC),启动开始钩子(post start),启动探针(liveness probe,readness probe)
-
在主容器结束之前,调用结束钩子(pre stop)

为什么分离出初始化容器,而不将所有的功能都封装在主容器中?
-
容器功能越单一越好,越适合调度
-
权限管理,更加安全。容器只具备需要访问的安全,其他都不应该具有
-
执行共性操作,如果一个Pod里面包含多个容器,都需要使用同一份代码,那么可以在初始容器里面将代码下载好,然后主容器共用
探针和钩子
-
livenessProbe:探测容器是否活着
-
httpGet:http请求方式,如果返回的HTTP状态码在200和399之间,则认为程序正常,否则异常
-
exec:命令方式,在用户容器内执行一次命令,如果命令执行的退出码为0,则认为程序正常,否则异常
-
tcpSocket:访问端口方式,如果能够建立成功则认为程序正常,否则异常
-
-
readnessProbe:探测容器是否准备就绪
-
httpGet:http请求方式,如果返回的HTTP状态码在200和399之间,则认为程序正常,否则异常
-
exec:命令方式,在用户容器内执行一次命令,如果命令执行的退出码为0,则认为程序正常,否则异常
-
tcpSocket:访问端口方式,如果能够建立成功则认为程序正常,否则异常
-
-
lifecycle
-
postStart 启动后执行
-
preStop 终止前执行
-
执行方式和探针相同
-
-
例子
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
labels:
name: myapp
spec:
containers:
- name: readiness-httpget
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
imagePullPolicy: IfNotPresent
readinessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
---
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
labels:
name: myapp
spec:
containers:
- name: livess-httpget
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
---
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-poststart
namespace: default
labels:
name: myapp
tier: appfront
spec:
containers:
- name: lifecycle-poststart-pod
image: nginx
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command: ["/bin/sh","-c","echo Home+Page >> /usr/share/message"]
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
最简单的Pod例子
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
name: my-pod
spec:
containers:
- name: busybox
image: busybox:latest
Deployment的升级和回退
-
升级:如更新image:
kubectl set image mydeploy mynginx=docker.io/nginx:1.15 -
--record=true:记录每次操作的命令,并与history查看
-
回退:
kubectl rollout history deployment mydeploy
apiVersion: v1
kind: Deployment
metadata:
name: my-deploy
namespace: default
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: busybox
image: busybox:latest
DaemonSet升级策略
-
通过
.spec.updateStrategy.type指定 -
OnDelete: 该策略表示当更新了DaemonSet的模板后,只有手动删除旧的DaemonSet Pod才会创建新的DaemonSet Pod
-
RollingUpdate: 该策略表示当更新DaemonSet模板后会自动删除旧的DaemonSet Pod并创建新的DaemonSetPod
-
要使用DaemonSet的滚动升级,需要
.spec.updateStrategy.type设置为RollingUpdate
apiVersion: v1
kind: DaemonSet
metadata:
name: my-DaemonSet
spec:
selector:
matchLabels:
name: myapp
template:
metadata:
labels:
name: myappt
spec:
containers:
- name: busybox
image: busybox:latest
Job
-
spec.template格式同Pod
-
RestartPolicy仅支持Never或OnFailure
-
单个Pod时,默认Pod成功运行后Job即结束
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
backoffLimit: 6 # 最多失败6次
completions: 1 # 有一个Job成功运行
parallelism: 1 # 一次性运行pod的个数
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
CornJob
-
CornJob通过控制JJob实现功能
-
schedule格式:(与crontab格式相同)
-
*****:从左到右依次是分钟,小时,每个月的第几天,月,星期几 -
每15分钟:
0,15,30,45**** -
每隔30分钟运行一次,但仅在每月的第一天运行:
0,30*1** -
每天3-5,17-20每隔30分钟:
*/30 [3-5],[17-20] * * *
-
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: busybox
image: busybox:latest
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
注意:Job和CornJob没有selector,deployment,DaemonSet有selector
Service
Service类型
-
ClusterIP:默认方式,仅集群内部可以访问
-
NodePort:service的port映射到集群内每个节点的一个相同端口,外部使用节点IP和端口就可以访问
-
LoadBalancer:使用外部云服务上的负载均衡服务,要交钱。也可以自己搭建一个负载均衡,如下如
-
ExternalName:将service接收到的请求转发到另外的域名(有可能是在集群内部,有可能是在集群外部)
-
无头服务:也是一种service,只有service名称,没有ClusterIP,可以通过访问名称的方式访问后端Pod,但是没有负载均衡的功能。名称类似:
my-service.default.svc.cluster.local.
-
一个简单的service例子
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
app: nginx
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 80
selector:
app: my-pod
Proxy模式
-
userspace模式,缺点kube-proxy的压力很大,已经放弃
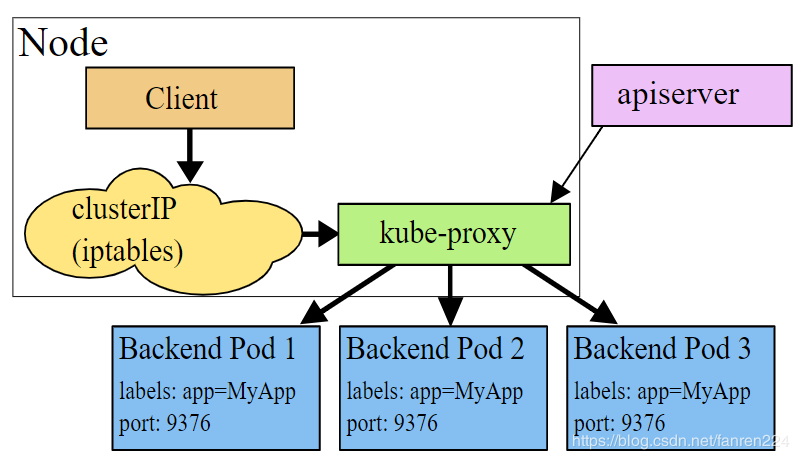
-
iptables模式:使用iptables进行路由转发
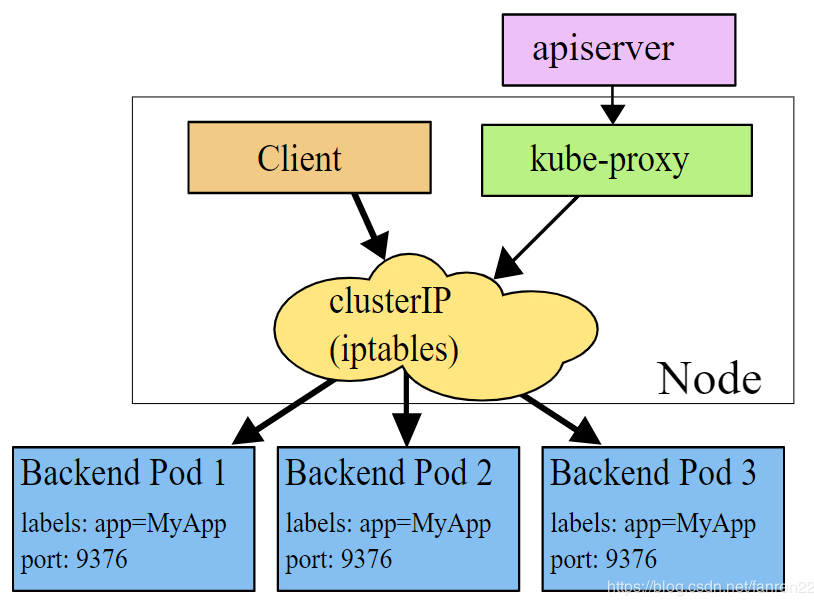
-
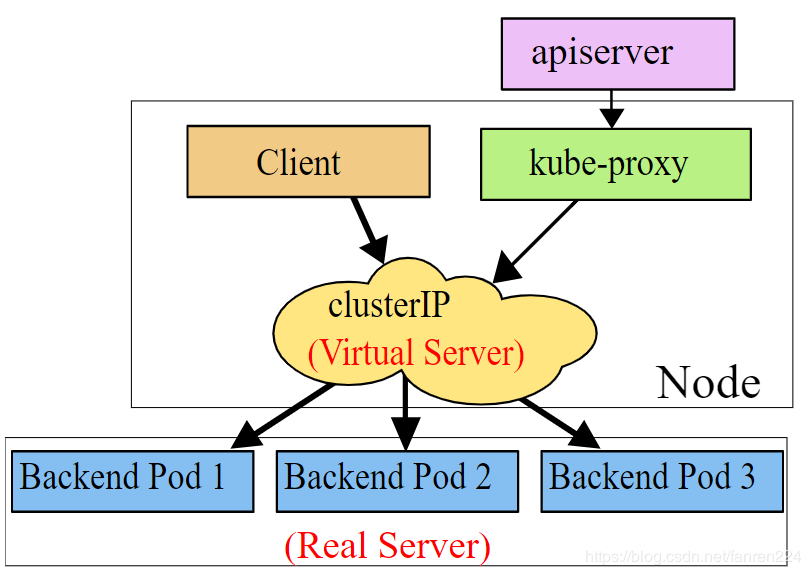
ipvs模式:架构和iptables一样,不同的是ipvs的转发效率更高。需要注意的是:使用ipvs要事先进行配置。否则默认使用iptables模式
StatefulSet
-
StatefulSet是deployment的变种,具有deployment的基本属性,如保存Pod的数量
-
StatefulSet是Kubernetes提供的管理有状态应用的负载管理控制器API。在Pods管理的基础上,保证Pods的顺序和一致性。与Deployment一样,StatefulSet也是使用容器的Spec来创建Pod,与之不同StatefulSet创建的Pods在生命周期中会保持持久的标记
-
特点:
-
具有固定的网络标记(主机名),是不是通过Pod的IP,使用的是无头服务
-
具有持久化存储,使用pvc实现
-
需要按顺序部署和扩展,第一个Pod启动完成后,才能启动第二个;如果序号为2的Pod死亡,会重新起一个Pod,名称和原来一样(无头服务通过名称解析IP,保证新起的Pod是第二个Pod)
-
需要按顺序终止及删除,,删除的顺序和创建时相反,删除时也是上一个Pod删除成功后,才会删除下一个Pod
-
需要按顺序滚动更新,更新时也是上一个Pod更新成功后,才会更新下一个Pod
-
-
demo
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None # 无头服务
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/nginx
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
volumeMode: Filesystem
resources:
requests:
storage: 50Mi
storageClassName: local-storage
Ingress
Ingress的优势
-
service提供的是4层代理,Ingress提供的是7层代理(根据域名代理)
-
Ingress对外提供统一的IP和端口,减少对外暴露的端口
-
Ingess提供负载均衡
Ingress的大致流程
-
创建一个Ingress控制器,可以使用nginx搭建
-
创建Ingress
-
Ingress控制器会实时监测Ingrss,将Ingress的配置自动添加到Ingress控制器(nginx的配置文件)
Ingress流程图

demo(http)
-
搭建nginx-ingress
# 直接到官网查看https://kubernetes.github.io/ingress-nginx/ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-0.31.1/deploy/static/provider/baremetal/deploy.yaml
-
搭建私有service
apiVersion: v1
kind: Service
metadata:
name: test-ingress
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: test-ingress
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: test-ingress
spec:
replicas: 1
template:
metadata:
labels:
app: test-ingress
spec:
containers:
- image: nginx:latest
imagePullPolicy: IfNotPresent
name: test-nginx
ports:
- containerPort: 80
-
创建ingress,关联nginx-ingress与service
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: feiutest.cn
http:
paths:
- path:
backend:
serviceName: test-ingress
servicePort: 80
-
测试:使用本地的host文件进行域名解析,然后通过域名访问
demo(https)
-
制作自签证书,生成tls.crt ,tls.key文件
openssl genrsa -out tls.key 2048 openssl req -new -x509 -key tls.key -out tls.crt -subj /C=CN/ST=Guangdong/L=Guangzhou/O=devops/CN=feiutest.cn
-
创建secret
#创建 kubectl create secret tls nginx-test --cert=tls.crt --key=tls.key #查看 kubectl get secret
-
修改ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: feiutest.cn
http:
paths:
- path:
backend:
serviceName: test-ingress
servicePort: 80
tls:
- hosts:
- feiutest.cn
secretName: nginx-test
-
测试:使用https访问,注意端口号
ConfigMap
创建ConfigMap的方式:
-
在命令行中指定configmap参数创建,
--from-literal -
在命令行中将一个配置文件创建为一个ConfigMap
--from-file=<文件> -
在命令行中将一个目录下的所有配置文件创建为一个ConfigMap,
--from-file=<目录>,和指定文件的创建方式相同 -
写好标准的configmap的yaml文件,然后
kubectl create -f创建 -
demo
kubectl create configmap test-config1 --from-literal = db.host = 10.5.10.116 --from-listeral = db.port = '3306' # key: db.host Value: 10.5.10.116 # key: db.port value: 3306 cat app.properties property.1 = value-1 property.2 = value-2 property.3 = value-3 kubectl create configmap test-config2 --from-file = ./app.properties # key: property.1 Value: value-1 # key: property.2 value: value-2 # key: property.3 Value: value-3 # configs 目录下的config-1和config-2内容如下 # key1 =value1 ############### # key2 =value2 kubectl create configmap test-config3 --from-file = ./configs # key: key1 value: value1 # key: key2 value: value2 cat my-configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: my-configmap namespace: default data: special.how: very special.type: charm kubectl create -f my-configmap.yaml # key: special.how Value: very # key: special.type value: charm
使用ConfigMap的方式
-
通过环境变量的方式,直接传递给pod
-
通过环境变量的方式,在yaml文件中通过命令使用环境变量,本质上就是通过环境变量的方式
-
作为volume的方式挂载到pod内,key就是文件名,value就是文件里面的内容,一个key一个文件
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
type: INFO
---
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "env" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: my-configmap
key: type
restartPolicy: Never
# 环境变量中会有SPECIAL_LEVEL_KEY=INFO
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
type: INFO
---
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "echo ${SPECIAL_LEVEL_KEY}" ]
env:
- name: SPECIAL_LEVEL_KEY
valueFrom:
configMapKeyRef:
name: my-configmap
key: type
restartPolicy: Never
# 打印 INFO
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
type: INFO
---
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: busybox
image: busybox:latest
command: [ "/bin/sh", "-c", "cat /etc/config/type" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: my-configmap
restartPolicy: Never
# 容器的/etc/config/type文件里面的内容是INFO
Secret
Secret和ConfigMap的对比
-
Secret和ConfigMap的总体思想类似,都是存储信息到Etcd,不同的是Secret存储的是密文。
-
Secret和ConfigMap都可以通过环境变量和Volume的方式使用
-
Secret的特点
-
Secret可以被ServerAccount关联(使用)
-
Secret可以存储register的鉴权信息,用在ImagePullSecret参数中,用于拉取私有仓库的镜像
-
Secret支持Base64加密
-
Secret分为kubernetes.io/Service Account,kubernetes.io/dockerconfigjson,Opaque三种类型,Configmap不区分类型
-
Secret的类型
-
Opaque:base64编码格式的Secret,用来存储密码、密钥等。注意:value必须是base64加密
# 环境变量方式引用
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: wordpress-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: wordpress
spec:
containers:
- name: "wordpress"
image: "wordpress"
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_USER
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
# volume的方式引用
apiVersion: v1
kind: Pod
metadata:
labels:
name: db
name: db
spec:
volumes:
- name: secrets
secret:
secretName: mysecret
containers:
- image: gcr.io/my_project_id/pg:v1
name: db
volumeMounts:
- name: secrets
mountPath: "/etc/secrets"
readOnly: true
ports:
- name: cp
containerPort: 5432
hostPort: 5432
-
kubernetes.io/dockerconfigjson:创建用于docker registry认证的secret,主要是用于从私有仓库拉取镜像
kubectl create secret docker-registry myregistrykey
--docker-server = DOCKER_REGISTRY_SERVER
--docker-username = DOCKER_USER
--docker-password = DOCKER_PASSWORD
--docker-email = DOCKER_EMAIL
# pod中是使用registry信息
apiVersion: v1
kind: Pod
metadata:
name: foo
spec:
containers:
- name: foo
image: app:v1
imagePullSecrets:
- name: myregistrykey
-
kubernetes.io/service-account-token:被serviceaccount引用,serviceaccout创建时Kubernetes会默认创建对应的secret。Pod如果使用了serviceaccount,对应的secret会自动挂载到Pod的
/run/secrets/kubernetes.io/serviceaccount目录中
Volume
-
Vloume是Pod中能够被多个容器共享的磁盘目录
-
主要用于持久化和同一个pod里面多个容器之间的目录文件共享
-
分类很多:
-
emptydir:在Pod创建时被创建,初始化为空,同一个Pod里面的同期都可以读写这个路径,当Pod死亡时,emptyDir也被删除,且永久消失
-
hostPath:将node上的路径挂载到Pod中,Pod死亡后,路径里面的文件不会消失
-
-
demo
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
# directory location on conainer
- mountPath: /test-pd
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data
# this field is optional
type: Directory
PV/PVC
-
PV(PersistentVolume):是集群中由管理员配置的一段网络存储。 它是集群中的资源,就像节点是集群资源一样。PV的生命周期不受Pod影响,独立存在。主要的作用是适配后端所有的网络存储,对外提供统一接口。
-
PVC(PersistentVolumeClaim):是由用户进行存储的请求,类似 Pod消耗节点资源,PVC消耗PV资源。
-
PV和PVC一一绑定,PVC匹配满足条件的最小容量PV
-
PV状态:
-
Available – 资源尚未被claim使用
-
Bound – 卷已经被绑定到claim了
-
Released – claim被删除,卷处于释放状态,但未被集群回收。
-
Failed – 卷自动回收失败
-
-
demo(nfs服务以安装且正常运行)
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv001
labels:
name: pv001
spec:
nfs:
path: /data/volumes/v1
server: nfs
accessModes: ["ReadWriteMany"]
capacity:
storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv002
labels:
name: pv002
spec:
nfs:
path: /data/volumes/v2
server: nfs
accessModes: ["ReadWriteMany"]
capacity:
storage: 5Gi
# 后端存储是nfs类型
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc
namespace: default
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 4Gi
# mypvc会绑定到pv002
apiVersion: v1
kind: Pod
metadata:
name: test-pod-pv-pvc
namespace: default
spec:
volumes:
- name: html
persistentVolumeClaim:
claimName: mypvc
containers:
- name: myapp
image: ikubernetes/myapp:v1
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html/
# 最后/data/volumes/v2会被挂在到容器mapp中的/usr/share/nginx/html/目录
节点调度
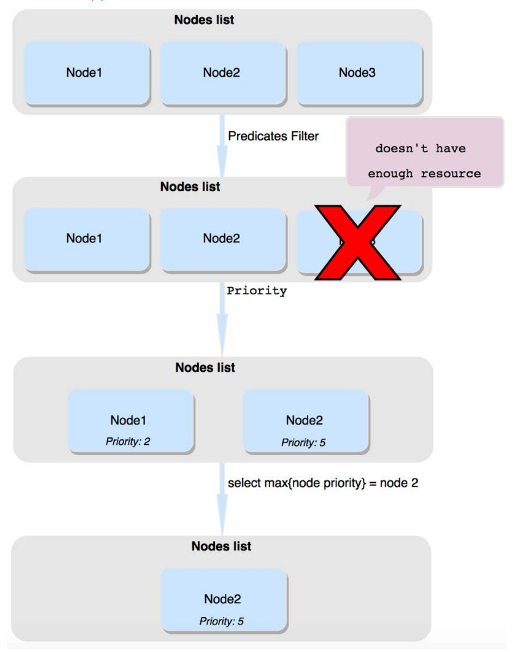
-
scheduler进行调度主要分为两步:节点筛选和节点打分优先
-
节点筛选:遍历所有节点,选择满足条件的节点,解决的是“能不能”的问题
-
节点打分优先:遍历筛选后的节点,按照优先级打分,选择分数最高的节点。解决的是“那个更合适”的问题
-
调度的简单过程如下所示
-
节点筛选的规则
-
NoVolumeZoneConflict:检查给定的zone限制前提下,检查如果在此主机上部署Pod是否存在卷冲突
-
PodFitsResources:检查节点是否有足够资源(例如 CPU、内存与GPU等)满足一个Pod的运行需求
-
PodFitsHostPorts:检查Pod容器所需的HostPort是否已被节点上其它容器或服务占用
-
HostName:检查节点是否满足PodSpec的NodeName字段中指定节点主机名,不满足节点的全部会被过滤掉
-
MatchNodeSelector:检查节点标签(label)是否匹配Pod的nodeSelector属性要求
-
PodToleratesNodeTaints : 根据 taints 和 toleration 的关系判断Pod是否可以调度到节点上,Pod是否满足节点容忍的一些条件
-
MatchInterPodAffinity : 节点亲和性筛选
-
GeneralPredicates:包含一些基本的筛选规则
-
-
节点打分优先
-
LeastRequestedPriority:节点的优先级由节点空闲资源与节点总容量的比值,即由(总容量-节点上Pod的容量总和-新Pod的容量)/总容量)来决定
-
BalancedResourceAllocation:CPU和内存使用率越接近的节点权重越高,该策略不能单独使用,必须和LeastRequestedPriority组合使用,尽量选择在部署Pod后各项资源更均衡的机器
-
InterPodAffinityPriority:通过迭代 weightedPodAffinityTerm 的元素计算和,并且如果对该节点满足相应的PodAffinityTerm,则将 “weight” 加到和中,具有最高和的节点是最优选的
-
SelectorSpreadPriority:为了更好的容灾,对同属于一个service、replication controller或者replica的多个Pod副本,尽量调度到多个不同的节点上
-
NodeAffinityPriority:节点亲和性机制
-
NodePreferAvoidPodsPriority(权重1W)
-
TaintTolerationPriority : 使用 Pod 中 tolerationList 与 节点 Taint 进行匹配,配对成功的项越多,则得分越低
-
亲和性
-
亲和性是Pod靠近节点
-
节点亲和性:Pod优先调度到具有亲和性的节点上运行
-
nodeSelector:节点满足label要求才能得到调度,简单粗暴
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector: # 选择具有disktype: ssd标签的节点
disktype: ssd
# 给节点添加label
# kubectl node label <node-name> <label-key>=<label-value>
# 查看节点label
# kubectl get nodes --show-labels
# 删除节点label
# kubectl label node <node-name> label-key-
-
亲和性支持的operator:
In,NotIn,Exists,DoesNotExist,Gt,Lt -
requiredDuringSchedulingIgnoredDuringExecution:硬条件,节点满足条件就可以得到调度,不满足条件就调度
-
preferredDuringSchedulingIgnoredDuringExecution:软条件,尽量在满足条件的节点上调度,如果没有满足条件的节点也可以得到调度
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
# 硬条件:节点必须包含kubernetes.io/e2e-az-name=e2e-az1的label才符合条件
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
# 软条件:节点尽量包含another-node-label-key=another-node-label-value的label,
# 不包含也可以调度
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
-
Pod亲和性:Pod之间的相互靠近和排斥
-
具有亲和性的Pod被调度到同一节点域上运行,一个节点域包含多个节点,通过节点标签和topologyKey指定
-
具有反亲和性的Pod会被调度到不同的节点域上运行
-
Pod的亲和性和反亲和性都具有硬条件和软条件
-
preferredDuringSchedulingIgnoredDuringExecution:硬条件
-
requiredDuringSchedulingIgnoredDuringExecution:软条件
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: affinity
labels:
app: affinity
spec:
replicas: 3
revisionHistoryLimit: 15
template:
metadata:
labels:
app: affinity
role: test
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
name: nginxweb
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- busybox-pod
topologyKey: kubernetes.io/hostname
# 上面这个例子中的pod需要调度到某个指定的主机上,且这个节点上运行了这样的pod:这个pod有一个
# app=busybox-pod的label
污点和容忍
-
污点和容忍是将Pod驱离节点,与亲和性相反
-
打上污点的节点,如果Pod没有容忍这个污点的能力,那么Pod就不会被调度到这个节点上;只有具备容忍这个污点能力的Pod才会被调度到这个节点上
-
master节点上默认具有node-role.kubernetes.io/master:NoSchedule污点,所以Pod默认不会调度到master上
-
增加污点,删除污点,查看污点
# 查看节点具有的污点 kubectl describe node nodeName # 删除节点的污点 kubectl taint nodes nodeName key=value:NoSchedule # 删除节点的污点 kubectl taint nodes nodeName key-
-
污点驱离Pod的方式
-
NoSchedule:不要调度到这个节点上
-
PreferNoSchedule:尽量不调度到污点节点上
-
NoExecute:不要调度到这个节点上,且会立即驱离已经运行在这个节点上的Pod
-
-
污点和容忍的匹配规则
-
对tolerations属性的写法,其中pod的 key、value、effect 与Nod 的Taint设置需保持一致
-
如果operator的值是Exists则value属性可省略
-
如果operator的值是Equa,则表示其key与value之间的关系是equal(等于)
-
如果不指定 operator 属性,则默认值为 Equal
-
-
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: taint
labels:
app: taint
spec:
replicas: 3
revisionHistoryLimit: 10
template:
metadata:
labels:
app: taint
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- name: http
containerPort: 80
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
# 该Pod可以被调度到matser上
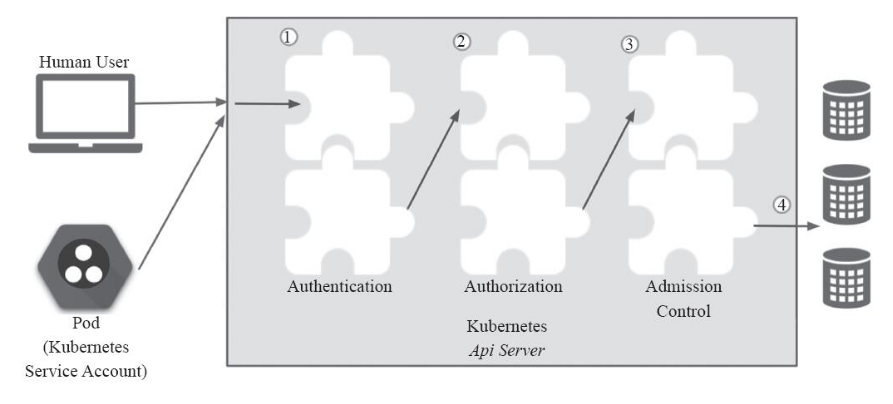
接入管理---前言
API Server作为Kubernetes网关,是访问和管理资源对象的唯一入口,其各种集群组件访问资源都需要经过网关才能进行正常访问和管理。每一次的访问请求都需要进行合法性的检验,其中包括认证,授权以及准入等,需要通过一系列验证之后,才能访问或者存储数据到etcd当中。如下图所示。
接入管理---认证
-
认证的主要作用是识别需要接入的对端身份,也就是解决“你是谁”的问题
-
ControllerManager、Scheduler与ApiServer进行通信,直接走127.0.0.1进行通信,因为都在同一台服务器上
-
kubelet和kube-peoxy与ApiServer进行通信,需要双向验证
-
Pod与ApiServer进行通信,通过ServiceAccount进行通信。 当创建Pod的时候,如果没有指定一个service account,系统会自动在与该Pod相同的namespace下为其指派一个default service account。
接入管理---鉴权
-
鉴权的主要作用是识别接入对端的权限,也就是解决“你能干什么”的问题
-
kubernetes中鉴权使用的是RBAC(Role-Based Access Control),基于角色的访问控制,通过自定义角色并将角色和特定的 user,group,serviceaccounts 关联起来已达到权限控制的目的。
-
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限
-
Subject:被作用者,包括 user,group,serviceaccounts,通俗来讲就是认证机制中所识别的用户
-
RoleBinding:定义了“被作用者”和“角色”的绑定关系,也就是将用户以及操作权限进行绑定
-
ClusterRole:集群角色,可以包含多个namespace
-
ClusterRoleBinding:一次绑定多个namespace
-
ClusterRole既可以被ClusterRoleBinding绑定,也可以被RoleBinding绑定,灵活处理即可
接入管理---准入控制
准入控制是请求的最后一个步骤,准入控制有许多内置的模块,可以作用于对象的 “CREATE”、“UPDATE”、“DELETE”、“CONNECT” 四个阶段。在这一过程中,如果任一准入控制模块拒绝,那么请求立刻被拒绝。一旦请求通过所有的准入控制器后就会写入对象存储中。准入控制的配置是有序的,不同的顺序会影响 Kubernetes 的性能,建议使用官方的配置。
Helm3安装和使用
-
安装
# 1. 下载 wget https://github.com/helm/helm/releases # 2. 解压 tar -zxvf helm-v3.0.0-linux-amd64.tgz # 3. 解压后的目录中找到二进制文件,然后将其移至所需的目标位置 mv linux-amd64/helm /usr/local/bin/helm # 4. 验证 helm help
-
自定义chart
# 创建文件和目录
# test/Chart.yaml test/values.yaml /test/templates/nginx.yaml
# cat test/Chart.yaml
apiVersion: v1 # 当前helm api版本,不需要修改
appVersion: 1.0.0 # 此处为你应用程序的版本号 [*]
description: Chart for the nginx server # 介绍此chart是干嘛的,按需求修改
name: example-chart # 模板名,对应目录名 [*]
version: 1.0.0 # 此chart版本号 [*]
maintainers: # 维护人员列表 [*]
- email: xxx
name: yyy
# cat test/values.yaml
version: "1.0"
# cat /test/templates/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
name: myapp
spec:
containers:
- name: nginx
image: nginx:{{.Values.version}} # 引用value中的配置
ports:
- name: http
containerPort: 80
imagePullPolicy: IfNotPresent
资源限制
-
资源限制主要是限制CPU和内存
-
pod级别:在Pod级别对资源进行限制
-
名称空间级别:在名称空间级别对资源进行限制
日志查看EFK
-
kubernetes中日志管理系统,主要是收集、存储、查看kubernetes中所有节点的所有日志
-
ELK也是日志管理系统,但是ELK很“重”,EFK是ELK的变种,但是很“轻”
-
EFK不是一个软件,而是一套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统。EFK是三个开源软件的缩写,分别表示:Elasticsearch , FileBeat, Kibana , 其中ELasticsearch负责日志保存和搜索,FileBeat负责收集日志,Kibana 负责界面,当然EFK和大名鼎鼎的ELK只有一个区别,那就是EFK把ELK的Logstash替换成了FileBeat,因为Filebeat相对于Logstash来说有2个好处:
-
侵入低,无需修改程序目前任何代码和配置
-
相对于Logstash来说性能高,Logstash对于IO占用很大
-
-
EFK的架构如下所示

修改证书时间
-
原因:以kubeadmin安装的kubernetes集群,证书的有效时间是1年,超过一年就无法使用
-
查看有效时间
cd /etc/kubernetes/pki
openssl x509 -in apiserver.crt -text -noout
---
Validity
Not Before: Apr 2 02:42:39 2020 GMT
Not After : Apr 2 02:42:39 2021 GMT
---
apiserver 只有一年的默认时间使用期限
-------------
-
go环境部署
wget https://dl.google.com/go/go1.12.7.linux-amd64.tar.gz tar -zxvf go1.12.1.linux-amd64.tar.gz -C /usr/local vim /etc/profile --- export PATH=$PATH:/usr/local/go/bin --- source /etc/profile
-
下载源码
git clone https://github.com/kubernetes/kubernetes.git git checkout -b remotes/origin/release-1.15.1 v1.15.1
-
修改kubeadmin源码
vim staging/src/k8s.io/client-go/util/cert/cert.go # kubeadm 1.14 版本之前 vim cmd/kubeadm/app/util/pkiutil/pki_helpers.go # kubeadm 1.14 至今 ---- const duration3650d = time.Hour * 24 * 365 * 10 NotAfter: time.Now().Add(duration365d).UTC(), ---- make WHAT=cmd/kubeadm GOFLAGS=-v cp _output/bin/kubeadm /root/kubeadm-new ---- cp -p /usr/bin/kubeadmn /usr/bin/kubeadmn.old cp -p /root/kubeadm-new /usr/bin/kubeadm chmod +x /usr/bin/kubeadmn ---- cd /etc/kubernetes/ cp -ap pki pki.old ---- cd /root/k8s-install/core kubeadm alpha certs renew all --config=./kubeadm-config.yaml
-
验证是否修改成功
openssl x509 -in apiserver.crt -text -noout