一.什么是全文检索?
就是在检索数据,数据的分类:
在计算机当中,比如说存在磁盘的文本文档,HTML页面,Word文档等等......
1.结构化数据
格式固定,长度固定,数据类型固定等等,我们称之为结构化数据,比如说数据库中的数据
2.非结构化数据
word文档,HTML文件,pdf文档,文本文档等等,格式不固定,长度不固定,数据类型不固定,成为非结构化数据
3.半结构化数据
二.数据的查询
1.结构化数据查询
结构化数据查询语言:SQL语句 select * from user where userid=1
2.非结构化数据的查询
非结构化数据查询有一些难度,比如我们在一个文本文件当中找到spring关键字
1.目测 一个一个查找文件....
2.使用程序将文件读取到内存当中,然后匹配字符串spring,这种方式被称为顺序扫描
3.将我们非结构化数据转换为结构化数据
例如Spring.txt文件中,英文文件每一个单词都是以空格进行区分,那么我们可以采用空格进行分割
然后将分割结果保存到数据库,这样就形成了一张表,我们在列上创建索引,加快查询速度,根据单词和文档
的对应关系找到文档列表,这样的过程我们称之为全文检索
三.全文检索概念
创建索引,然后查询索引的过程我们称之为全文检索,索引一次创建可以多次使用,这样就不用了每一次都进行文件数据拆分,比较快
四.全文检索应用场景
1.搜索引擎
百度,360,谷歌等等
2.站内搜索
论坛搜索帖子,微博搜索热点,新闻网站搜索新闻
3.电商搜索
淘宝,京东
有搜索的地方都可以用到全文检索
五.全文检索框架Lucene
Lucene:apache Lucene基于Java开发开源全文检索项目工具包,http://lucene.apache.org/,除Lucene外,Solr,ES等都是全文检索框架,以及Lucene
Lucene全文检索流程:
1.创建索引
1.1 获取文档
获得原始文档,要基于那些数据进行搜索,这些数据就是原始文档
如何获取原始文档:
1.搜索引擎:根据爬虫获得原始文档
2.站内搜索:基本上都是从数据库当中获取的,JDBC获取
3.磁盘文件:利用IO流读取
1.2 构建文档对象
每一个原始文档都是一个文档对象,比如磁盘文件,每一个文件就是一个文档对象,京东搜索,每一个商品就是一个文档对象
每一个文档对象当中包含多个域,域中存储文档信息,存储文档名称,文档路径,文档大小,文档内容,域中有两大部分:
域的名称name,域的值spring.txt key=value,每一个文档都有一个文档编号ID
1.3 分析文档(分词)
1.3.1 根据空格进行字符串拆分,得到单词列表
1.3.2 单词统一转换为小写或者大写,用户查询时,将查询内容也统一转换为大写或者小写
1.3.3 去掉标点
1.3.4 去除停用词(文档数据当中无意义的词,比如 the a )
1.3.5 得到分词结果之后,每一个关键词都封装成一个term对象,term对象包含两大部分:
1.关键词所在的域
2.关键词本身
不同的域拆分出来相同的关键词是不同的term,比如从文件名和文件内容都拆分出来spring关键词,这两个spring是完全不同域的
1.4 创建索引
基于关键词列表创建一个索引,保存到索引库当中,一次创建多次使用
索引库:
1.索引
2.document对象
3.关键词和文档的对应关系,采用倒排索引结构
spring
2.查询索引
2.1 用户查询接口:用户输入查询条件的地方,比如百度搜索框,jd商品搜索框
2.2 获取到关键词,获取到关键词后封装成一个查询对象
要查询的域,和要搜索的关键词
2.3 执行查询,根据查询的关键词和对应的域去查询
2.4 根据关键词和文档的对应关系,利用倒排索引结构,找到文档id,找到id后就能定位到文档
2.5 渲染结果
六.Lucene入门程序案例
环境搭建,创建一个maven工程,导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.4.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>7.4.0</version> </dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.4</version> </dependency>
1. 创建索引
public static void main(String[] args) throws IOException { //步骤一:创建Directory对象,用于指定索引库的位置 RAMDirectory内存 Directory directory = FSDirectory.open(new File("E:\Y2学习\Lucene\索引库\Index").toPath()); //步骤二:创建一个IndexWriter对象,用于写索引 IndexWriter indexWriter=new IndexWriter(directory,new IndexWriterConfig()); //步骤三:读取磁盘中文件,对应每一个文件创建一个文档对象 File file=new File("E:\Y2学习\Lucene\资料\资料\资料\searchsource"); //步骤四:获取文件列表 File[] files = file.listFiles(); for (File item:files) { //步骤五:获取文件数据,封装域 参数三:是否存储 Field fieldName=new TextField("fieldName",item.getName(), Field.Store.YES); Field fieldPath=new TextField("fieldPath",item.getPath(), Field.Store.YES); Field fieldSize=new TextField("fieldSize", FileUtils.sizeOf(item)+"", Field.Store.YES); Field fieldContent=new TextField("fieldContent", FileUtils.readFileToString(item,"UTF-8"), Field.Store.YES); //步骤六:创建文档对象,向文档对象中添加域 Document document=new Document(); document.add(fieldName); document.add(fieldPath); document.add(fieldSize); document.add(fieldContent); //步骤七:创建索引,将文档对象写入到索引库 indexWriter.addDocument(document); } //步骤八:关闭资源 indexWriter.close(); }
启动main方法后,索引库多了如下二进制文件

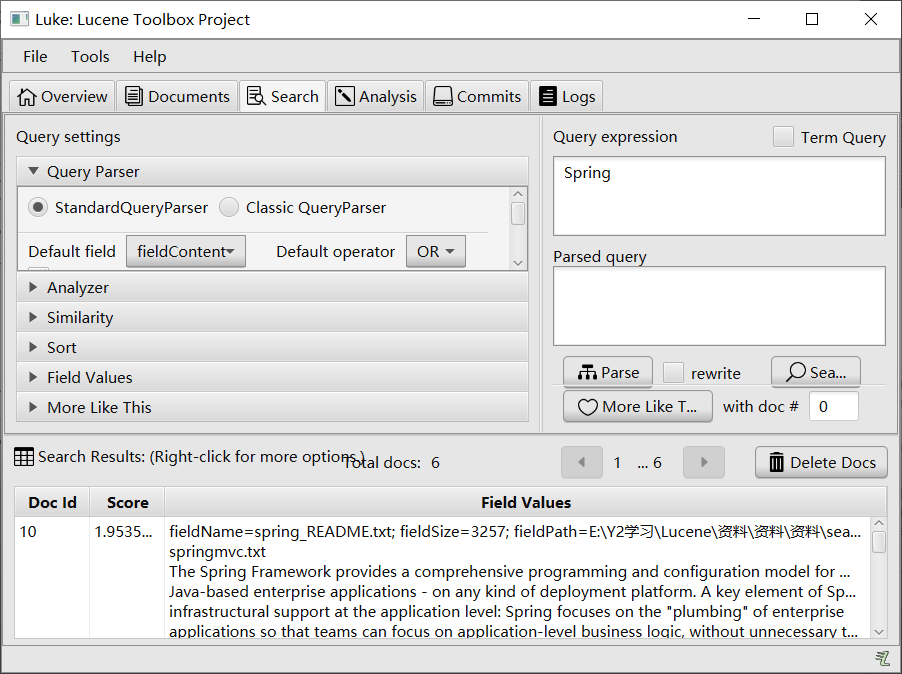
2. 利用Luke工具查看索引库内容
2.1 指定索引库位置

2.2 查看当前索引库内容
选择完路径点击OK,就可根据需求查找索引

3. 查看索引
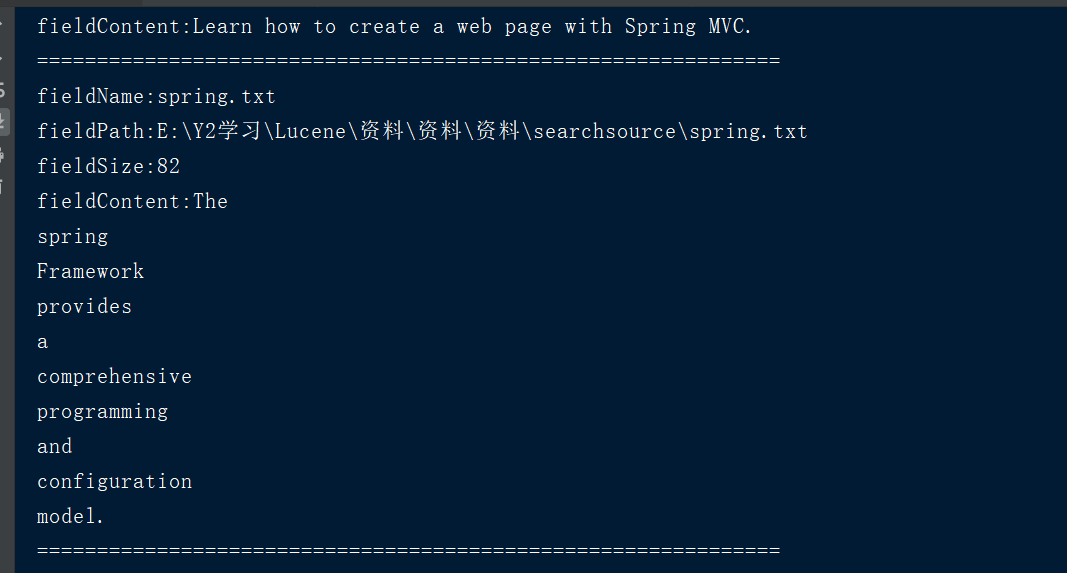
public static void main(String[] args) throws IOException { //1.创建Directory对象,指定索引库位置 Directory directory = FSDirectory.open(new File("E:\Y2学习\Lucene\索引库\Index").toPath()); //2.创建IndexReader对象,读取索引库内容 IndexReader indexReader= DirectoryReader.open(directory); //3.创建IndexSearcher对象 IndexSearcher indexSearcher=new IndexSearcher(indexReader); //4.创建Query查询对象 Query query=new TermQuery(new Term("fieldContent","spring")); //5.执行查询,获取到文档对象 TopDocs topDocs = indexSearcher.search(query, 10); System.out.println("共获取:"+topDocs.totalHits+"个文档~~~~~~~~~~~~~~~~~~~~~"); //6.获取文档列表 ScoreDoc[] scoreDocs=topDocs.scoreDocs; for (ScoreDoc item:scoreDocs) { //获取文档ID int docId=item.doc; //取出文档 Document doc = indexSearcher.doc(docId); //获取到文档域中数据 System.out.println("fieldName:"+doc.get("fieldName")); System.out.println("fieldPath:"+doc.get("fieldPath")); System.out.println("fieldSize:"+doc.get("fieldSize")); System.out.println("fieldContent:"+doc.get("fieldContent")); System.out.println("=============================================================="); } //7.关闭资源 indexReader.close(); }
执行效果: