表示图的一种方法,用哈希链存储每一个顶点到其子节点的边信息。对于每一条边,我们存储两个顶点u,v及边的权值w。
拿图论基本图举例:
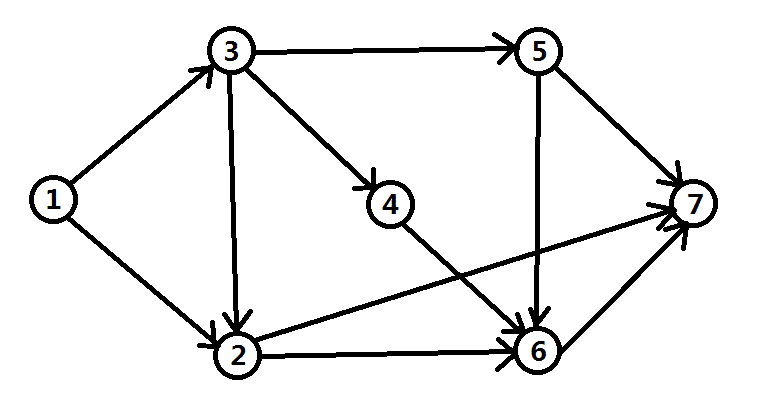
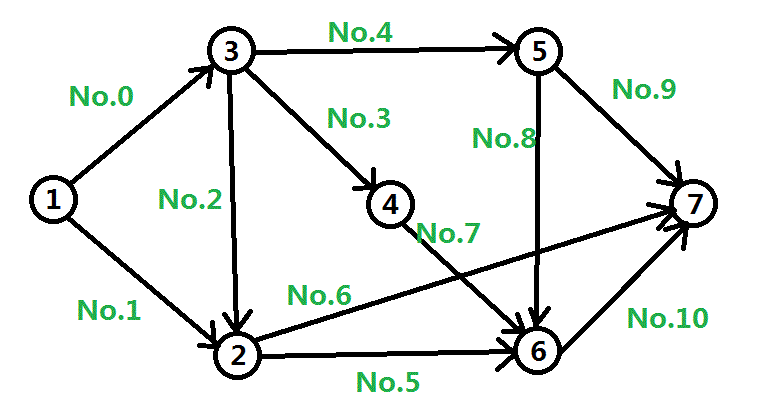
上图有11条边。我们从0开始为这些边标号:
先给出数组的存储方法(可能错误):用first[i]表示第编号为i的节点的第一个子节点的编号,这个子节点的选取是任意的。用next[i]表示编号为i的节点在这条哈希链中的下一个结点的编号。
对于节点3,一共有3个子节点:2,4,5,比如我们让first[3]=2。那么我们这么组织这条链:
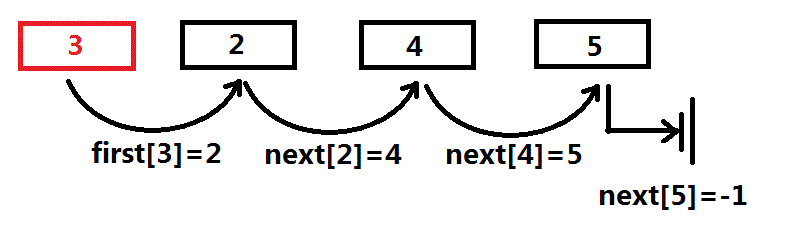
用一个for遍历这条链:for(int i = first[3]; i != -1; i = next[i]) ...
这张图的表就是:
1 -> 2 -> 3 -> (-1)
2 -> 6 -> 7 -> (-1)
3 -> 2 -> 4 -> 5 -> (-1)
4 -> 6 -> (-1)
5 -> 6 -> 7 -> (-1)
6 -> 7 -> (-1)
7 -> (-1)
于是我们发现了一个奇怪的现象,next[6]有两个值,一个是链5中的next[6]=7,一个是链4中的next[6]=(-1),发生了冲突,看来我们需要改变next[i]的定义来避免这样的冲突。怎么办呢?还记得我们为每一条边的设置的编号吗?它是唯一的,我们可以借助每一条边的编号来重新定义first[i],next[i]。
新的数组的存储方法(正确):用first[i]表示编号为i的节点的第一条边的编号(此编号唯一确定),这条边的选取同样是任意的。用next[i]表示第i条边在这条哈希链中的下一条边的编号。
再发一遍边的编号的图:
还是对于节点3有:
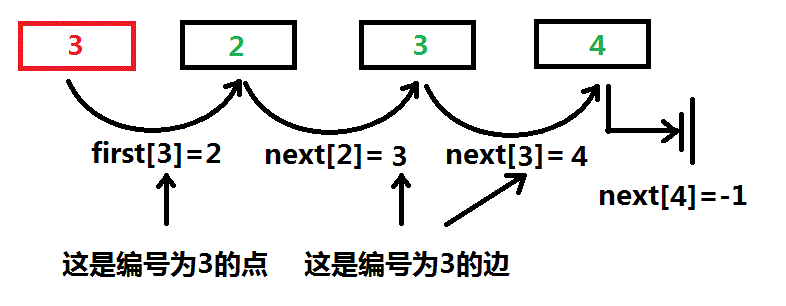
注意,上面有好多个“3”,它们表示的意义是不同的,希望读者好好体会。
也就是说,红色的框框表示的是节点,而后面的框框表示的都是边,由于每一条边的编号唯一确定,所以我们的first[], next[]唯一确定。
给出完整邻接表(正确):
1 -> 0 -> 1 -> (-1)
2 -> 5 -> 6 -> (-1)
3 -> 2 -> 3 -> 4 -> (-1)
4 -> 7 -> (-1)
5 -> 8 -> 9 -> (-1)
6 -> 10 -> (-1)
7 -> (-1)
可以看到无论是next[]还是first[]都没有重复的编号,至此,我们构造出了这个图的邻接表。
如果不能理解,有个易懂的理解:你看节点3一共射出三条边:2,3,4。随便选一条边(比如就3吧),我们把它定为第一条边,就是说,节点3的哈希链后面紧跟着是它,它算是一个小队长,它有二个队员:2,4,所以小队长后面放一大堆队员,那么一条哈希链可以表示为:节点 -> 小队长 -> 队员1 -> 队员2……
一开始是可怜的头节点3 -> (-1)
上来你选了小队长:3 -> 3 -> (-1)
然后添加队员1,编号为2:3 -> 3 -> 2 -> (-1)
然后添加队员2,编号为4:3 -> 3 -> 2 -> 4 -> (-1)
没有队员了,这条哈希链结束,开始下一条……
我们可以用 w[i]表示边i的权值, to[i]表示第i条边的儿子节点编号,from[i]表示第i条边的父亲节点编号。
那么我们将上述过程写出生成邻接表并打印的代码,添加边的操作与添加一个哈希结点操作完全相同,都是插在头部。
1 #include <cstdio> 2 #include <cstring> 3 using namespace std; 4 const int maxn = 500 + 10; //最多有多少个点 5 const int maxm = 10000 + 10; //最多有多少条边 6 int n, m, ms = 0; //ms存的是下一条要加入的边的编号 7 int next[maxm], first[maxn], W[maxn], from[maxm], to[maxm]; 8 int main(){ 9 memset(first, -1, sizeof(first)); //别忘了初始化 10 int u, v, w; 11 scanf("%d%d", &n, &m); 12 for(int i = 0; i < m; i ++){ 13 scanf("%d%d%d", &u, &v, &w); 14 ///// 15 next[ms] = first[u]; 16 first[u] = ms ; 17 from[ms] = u; 18 to[ms] = v; 19 ms ++; 20 W[i] = w; 21 ///// 22 } 23 for(int x = 1; x <= n; x++){ 24 printf("%d", x); 25 for(int i = first[x]; i != -1; i = next[i]){ 26 printf(" -> %d", i); 27 } 28 printf(" -> (-1) "); 29 } 30 return 0; 31 } 32 /* 附上那张图的信息以便调试 33 7 11 34 1 2 100 35 1 3 200 36 4 6 600 37 3 5 500 38 5 6 100 39 2 7 400 40 2 6 900 41 3 2 700 42 3 4 1000 43 5 7 500 44 6 7 300 45 */
打印结果是:
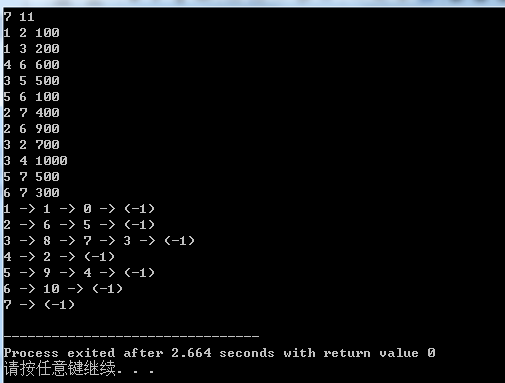
为什么与我们手算的临接表不同呢?一个原因是对于边的编号是不同的,还有一个原因是每一条哈希链中的所有边是平等的,本身不存在先后关系。
至此,邻接表保存一张图告一段落。