论文地址:https://arxiv.org/abs/1704.05548
项目地址:http://www.cs.toronto.edu/polyrnn
概述
Polygon-RNN是一篇收录于CVPR2017的论文,文中作者基于CNN+RNN提出了一种半自动目标实例标注的算法。当前大多方法都将目标分割视为像素级分类问题,而本文则将其看做多边形预测任务,以裁剪的目标图像作为输入,预测目标的多边形轮廓的顶点(假定使用者已提供目标的bounding box)。如下图所示:

其半自动过程体现在,人工标注可以在任何时间干预系统的自动标注过程,并在需要修正的时间进行顶点修正。
由于需要生成闭合的多边形,而闭合多边形呈环状,作者假定顶点序列中任意一点都可以作为起点,并按照顺时针方向生成顶点。
模型结构
Polygon-RNN通过CNN(基于修正的VGG-16)进行图像的特征提取,然后通过RNN预测多边形的顶点。对CNN+RNN模型进行端到端的训练,有助于CNN对目标边界进行微调、RNN遵循目标边界学习目标的形状。RNN的输入包括:CNN提取到的图像块的特征、前两个时间序列下生成的顶点(比如需要生成顶点Vi,则需要输入Vi-1和Vi-2)以及起始顶点。前两个顶点用于遵循特定的方向,初始顶点用于判断多边形是否闭合。模型如Figure 2所示。

CNN
使用VGG-16的基本框架,移除了全连接层及最后的max-pooling层,增加了一系列卷积层和max-pooling层、upscaling层来调整VGG各层(pool2、pool3、conv4_3和conv5_3)输出的feature map大小,然后将这几层的feature map进行拼接(文中称为skip-connections),最后通过卷积层和ReLU层传递给RNN。对不同层的feature map拼接能够获得低层的边角信息以及高层的语义信息。
RNN
作者设计了一个两层的卷积LSTM(ConvLSTM,卷积核3*3,16 channels),有效地减少了参数。单层的计算如下:

每一步预测一个顶点,产生D*D+1的grid,顶点采用one-hot编码,D*D即顶点可能的位置,最后一维表示顶点序列是否结束。在每一步上取概率最大的顶点作为该步的预测结果,因此用户可以在任何时间对标注过程进行干预和修正。在量化网格中使用zero error进行多边形简化来消除位于一条线上的顶点,并删除由于量化过程而落在同一网格的多个顶点。
此外,对于第一个顶点的预测,显然不能使用前文的方法。为了预测第一个顶点,文中使用之前的CNN,并添加了两层,每层维度是D*D,一个分支用于预测目标的边界,另一个分支以边界预测层的输出和图像的特征为输入,进行多边形的顶点预测。
文中使用多边形的边作为目标边界的gt,使用多边形的顶点作为顶点层的gt;评估标准采用IOU。
实验结果
下表是在Cityscapes数据集上的自动标注结果: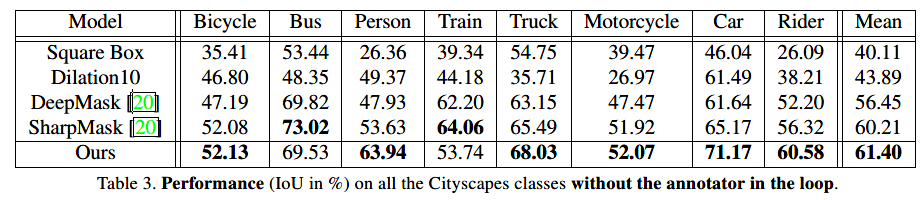
IOU优于其他方法。

一些自动标注、半自动标注和Ground truth的对比结果:

总结
Polygon-RNN在自动标注上和其他像素标注方法DeepMask、SharpMask等的精度不相上下,在人工干预的情况下则会明显优于后两者,标注速度也大大提升。但是由于模型的分辨率较小,进行大尺寸目标标注时误差会急剧增大。