1. 概述
Apache Cassandra将数据存储在表中,每个表都由行和列组成。CQL(Cassandra查询语言)用于查询存储在表中的数据。Apache Cassandra数据模型基于查询并针对查询进行了优化。Cassandra不支持用于关系数据库的关系数据建模。Cassandra数据建模专注于查询。
Cassandra中的数据建模使用查询驱动(query-driven)的方法,其中特定查询是组织数据的关键。查询(Query)是从表中选择数据的结果,模式(Schema)是对表中数据的排列方式的定义。Cassandra的数据库设计基于对快速读写的需求,因此架构设计越好,数据写入和检索的速度就越快。
相反,关系型数据库根据设计的表和关系对数据进行规范化,然后编写将要进行的查询。关系数据库中的数据建模是表驱动(table-driven)的,表之间的任何关系都表示为查询中的表连接。
1.1. 什么是数据建模
数据建模是识别实体及其关系的过程。在关系数据库中,数据放在具有外键的规范化表中,外键用于引用其他表中的相关数据。应用程序将进行的查询由表的结构驱动,相关数据作为表连接进行查询。
在Cassandra中,数据建模是查询驱动(query-driven)的。 数据访问模式和应用程序查询确定数据的结构和组织,然后将其用于设计数据库表。
数据围绕特定查询建模。查询的最佳设计是访问单个表,这意味着查询中涉及的所有实体必须位于同一表中,以使数据访问(读取)变得非常快。 数据被建模为最适合一个查询或一组查询。一个表可能具有一个或多个最适合查询的实体。由于实体之间通常确实具有关系,并且查询可能涉及实体之间具有关系的实体,因此单个实体可以包含在多个表中。
1.2. 查询驱动的建模
在关系数据库模型中,查询使用表连接从多个表获取数据,而在Cassandra中不支持连接,因此所有必需字段(列)必须组合在一个表中。由于每个查询都由一个表支持,因此在称为非规范化的过程中,数据会在多个表之间冗余。 数据冗余和高写入吞吐量用于实现高读取性能。
1.3. 目标
主键(primary key)和分区键(partition key)的选择对于在整个集群中均匀分布数据很重要。使查询读取的分区数量保持最少也很重要,因为不同的分区可能位于不同的节点上,并且协调器将需要向每个节点发送请求,从而增加了请求的开销和延迟。即使查询中涉及的不同分区位于同一节点上,较少的分区也可以提高查询效率。
1.4. 分区
分区键(partition key)是从主键(primary key)的第一个字段生成的。使用分区键分区到哈希表的数据可以提供更快的查询。用于查询的分区越少,查询的响应时间就越快。
下面是一个分区的例子,假设表t有一个主机id
CREATE TABLE t (
id int,
k int,
v text,
PRIMARY KEY (id)
);
分区键是从主键id生成的,用于在群集中的各个节点之间进行数据分配。
下面这个例子,是一个复合主键
CREATE TABLE t (
id int,
c text,
k int,
v text,
PRIMARY KEY (id,c)
);
对于具有复合主键的表t,第一个字段id用于生成分区键,第二个字段c是用于在分区内排序的聚类键。使用聚类键对数据进行排序可以提高检索相邻数据的效率。
通常,对主键的第一个字段进行哈希处理以生成分区键,而其余字段则是用于对分区内的数据进行排序的聚类关键字。对数据进行分区可以提高读写效率。不是主键字段的其他字段可以单独建立索引,以进一步提高查询性能。
接下来这个例子,id1和id2用户生成分区键,c1和c2用于在分区内排序的聚类关键字。
CREATE TABLE t (
id1 int,
id2 int,
c1 text,
c2 text
k int,
v text,
PRIMARY KEY ((id1,id2),c1,c2)
);
1.5. 与关系数据模型比较
关系数据库使用外键将数据存储在与其他表有关系的表中。关系数据库的数据建模方法是以表为中心的。查询必须使用表连接从多个表中获取数据,这些表之间存在关系。Apache Cassandra没有外键或关系完整性的概念。Cassandra的数据模型是基于设计高效的查询,不涉及多个表的查询。关系数据库对数据进行规范化以避免重复。相反,Cassandra通过在以查询为中心的数据模型的多个表中冗余数据来对数据进行非规范化。如果Cassandra数据模型不能完全整合用于特定查询的不同实体之间关系的复杂性,则可以使用应用程序代码中的客户端连接(client-side joins)。
1.6. 数据建模示例
假设有一组杂志数据,属性有杂志id、杂志名称、出版频率、出版日期和出版商。
查询一:列出所有杂志名称,包括其发布频率。
由于不需要查询所有属性,因此数据模型将仅由ID(用于分区键),杂志名称和发布频率组成,如下图所示:

查询二:按出版商列出所有杂志名称
输出列增加出版商,同时用出版商作分区键,如下图所示:
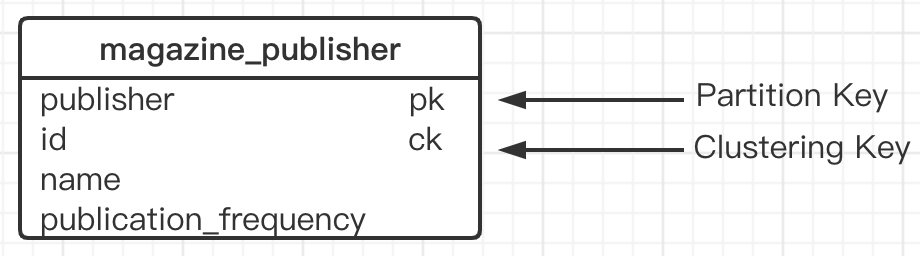
1.7. 定义Schema
对于查询一,定义如下:
CREATE TABLE magazine_name (
id int PRIMARY KEY,
name text,
publication_requency text
)
对于查询二,定义如下:
CREATE TABLE magazine_publisher (
publisher text,
id int,
name text,
publication_requency text,
PRIMARY KEY (publisher, id)
) WITH CLUSTERING ORDER BY (id DESC)
2. 概念数据建模
首先,创建一个简单的域模型,它在关系型世界中很容易理解,然后看看如何在Cassandra中将它从关系型映射到分布式哈希表模型。
以酒店预订为例,概念性领域包括酒店、入住酒店的客人、每个酒店的房间集合、这些房间的价格和空房情况以及为客人预订的预订记录。酒店通常还会维护“景点”的集合,这些景点包括公园,博物馆,购物画廊,古迹或客人在住宿期间可能要参观的酒店附近的其他地方。旅馆和兴趣点都需要维护地理位置数据,以便可以在地图上找到它们进行混搭,并计算距离。ER图如下:
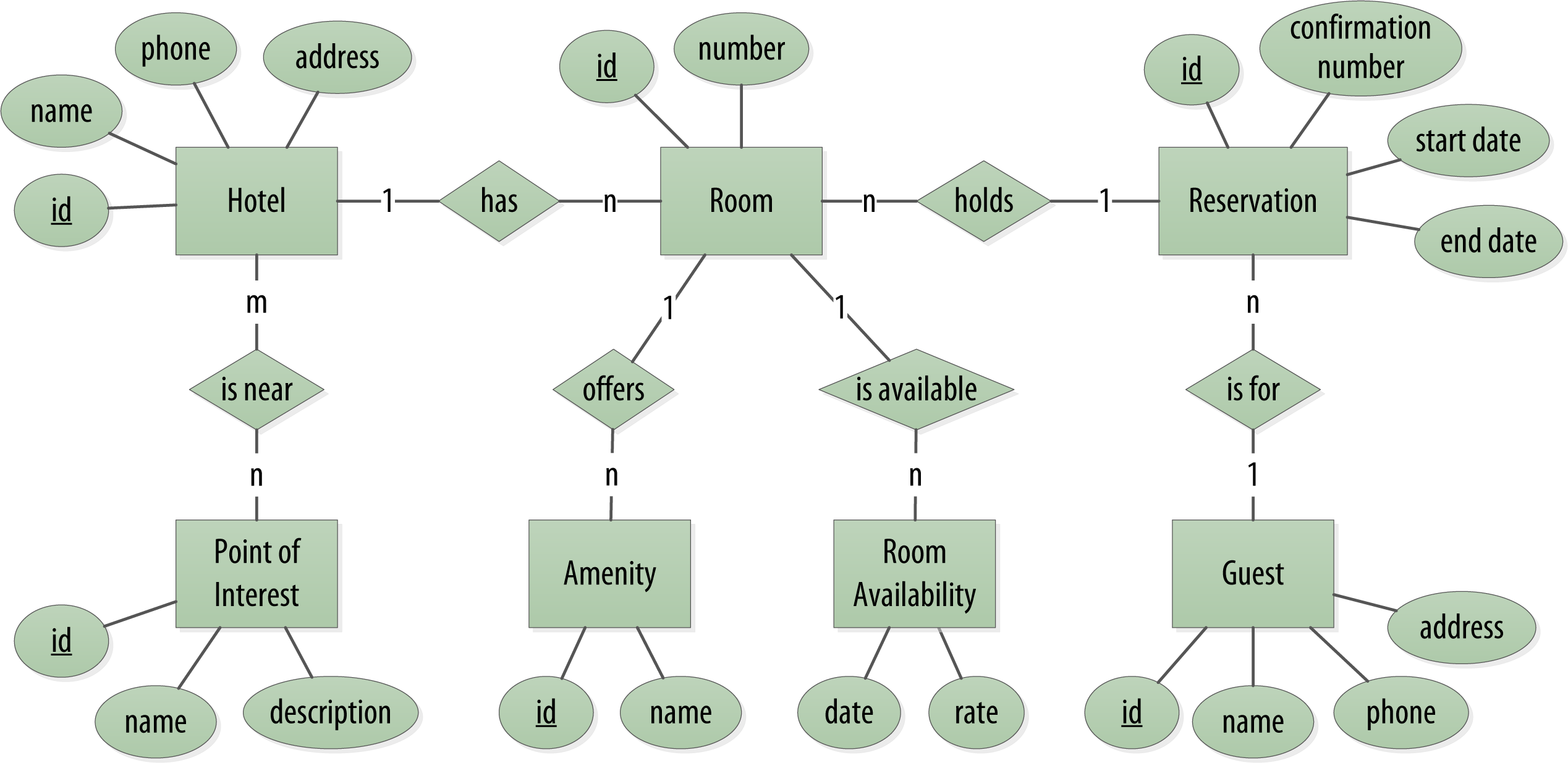
一目了然,一个酒店有多个房间,一个房间里面有多个休闲设施,房间的空闲情况也是分时段的,酒店附近有多个景点,一位顾客可以订多个房间,每一个预订记录对应多个房间。
3. 关系型数据库设计
当我们构建一个新的数据驱动应用程序时,将使用关系型数据库。首先,将领域对象转化为一组规范化的表,并使用外键引用其他表中的相关数据。
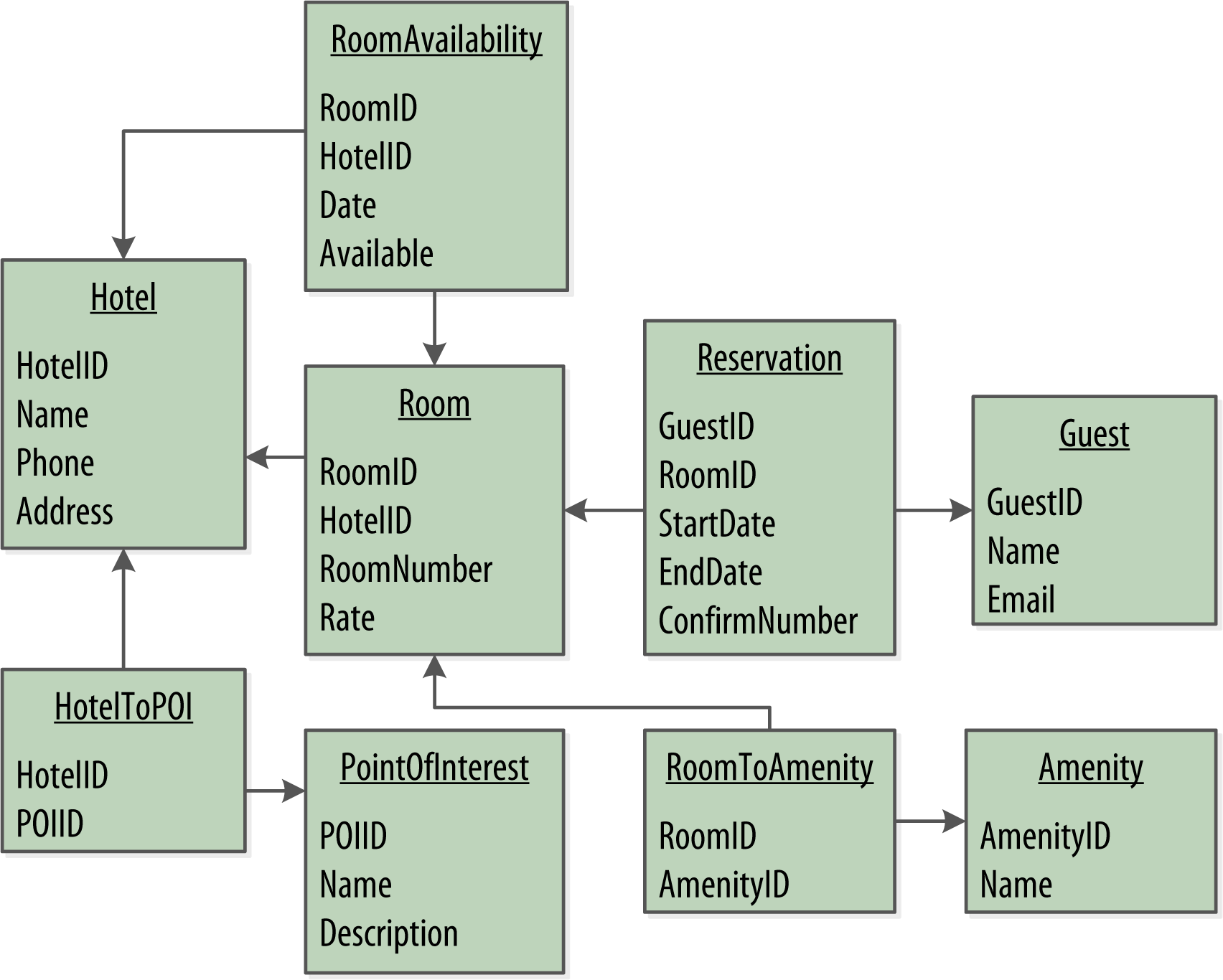
3.1. RDBMS和Cassandra之间的设计差异
• 没有连接(join)
在Cassandra中,无法执行连接(join)操作。如果你已经设计了一个数据模型并且需要一个连接其它表的数据,那么你不得不在客户端做这种连接,或者创建一个非规范化的第二个表来表示连接结果,后一种方法是Cassandra数据建模的首选方法。
• 没有外键引用
在关系数据库中,可以在表中指定外键来引用另一个表的主键。但Cassandra并没有强制要求必须定义外键来引用。在表中存储与其他实体相关的ID仍然是常见的设计需求,但是级联删除等操作不可用。
• 非规范化
在关系数据库设计中,经常会强调范式重要性,数据库设计三范式。但是在Cassandra中,遵循范式不是一个好的选择,因为通常在不遵循范式时执行得最好。
关系数据库故意去规范化的第二个原因是需要保留的业务文档结构。也就是说,有一个封闭的表,它引用了很多外部表,这些表的数据可能会随着时间的变化而变化,但是你需要将封闭的文档保存为历史记录中的一个快照。这里最常见的例子是发票。假设已经有了customer和product表,可能你认为可以只制作一个针对这些表的发票,但在实践中永远不应该这样做。顾客或价格信息可能会改变,然后你将失去失去发票单据上发票日期的完整性,这可能违反审计、报告、或法律,并导致其他问题。可以看到,在这种情况下,冗余是必要的。
在Cassandra中,非规范化是完全正常的。
• 查询优先
简单的来说,关系建模意味着概念领域模型开始,用表来表示领域对象,用表字段来表示领域对象的属性,然后设置主键和外键来表示领域对象之前的关系。如果有多对多的关系,还要再建一张中间表。关系世界中的查询是次要的。只要对表进行适当的建模,就可以始终获得所需的数据。即使必须使用几个复杂的子查询或连接语句,这通常也是正确的。
相比之下,在Cassandra中,不是从数据模型开始的,而是从查询模型开始的。Cassandra不是先对数据建模,然后编写查询,而是先对查询建模,让数据围绕查询进行组织。考虑应用程序将使用的最常见的查询路径,然后创建支持它们所需的表。
• 最佳存储设计
在关系数据库中,对于用户来说,表是如何存储在磁盘上的通常是透明的,基本不用关心。然而,这是Cassandra中的重要考虑因素。由于Cassandra表都存储在磁盘上的独立文件中,因此将相关列一起定义在同一个表中非常重要。
在Cassandra中创建数据模型时,一个关键目标是最小化必须搜索的分区数量,以满足给定的查询。由于分区是不跨节点划分的存储单元,因此搜索单个分区的查询通常会产生最佳性能。
• 排序是一个设计决策
在RDBMS中,可以通过在查询中使用ORDER BY轻松地更改记录返回的顺序。默认的排序顺序是不可配置的;默认情况下,记录是按照写入的顺序返回的。如果要更改顺序,只需修改查询即可,并且可以根据任何列进行排序。
但是,在Cassandra中,排序的处理方式有所不同。这是一个设计决策。查询中可用的排序顺序是固定的,并且完全由在CREATE TABLE命令中提供的集群列的选择确定。CQL SELECT语句确实支持ORDER BY语义,但仅按聚簇列指定的顺序。
4. 定义应用程序的查询
既然是查询驱动的,那么就先看看针对酒店预订这个例子,业务都需要查询,毕竟技术是为业务服务的,抛开业务弹设计是不可取的。
(画外音:此刻,突然想到那句“技术支撑商业、技术拓展商业、技术创作商业”)
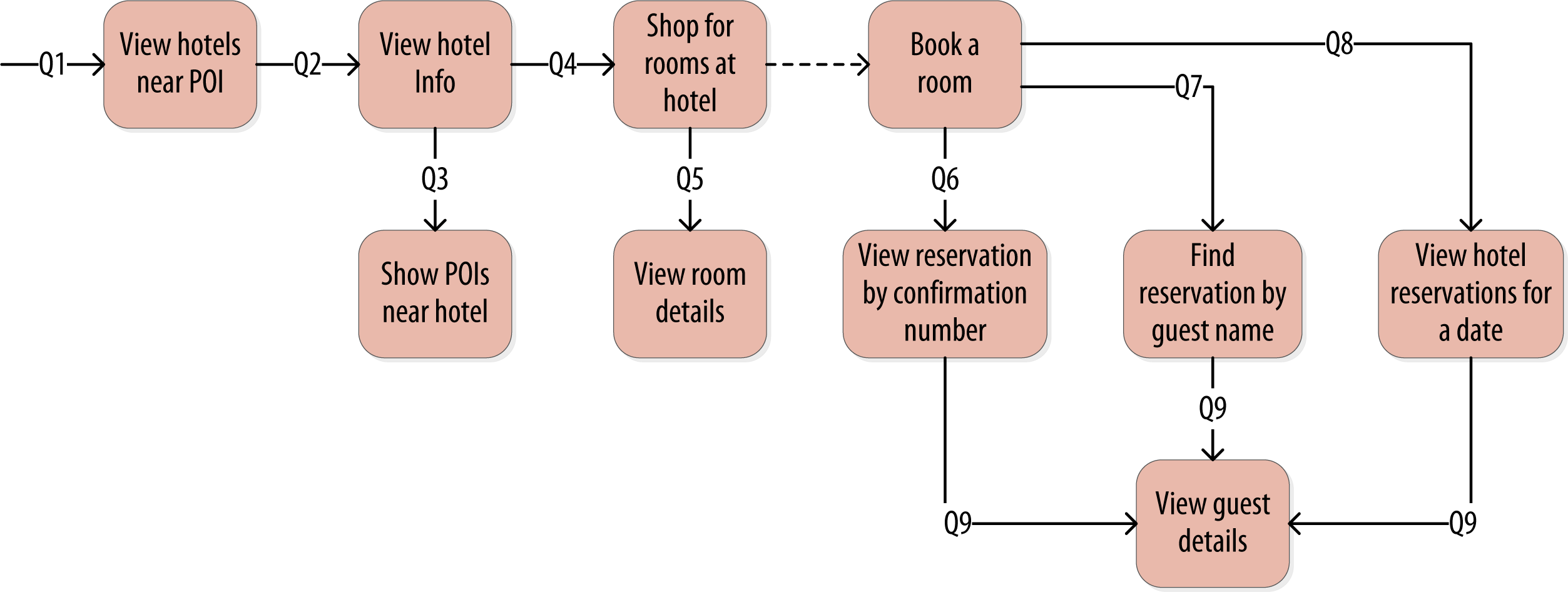
言归正传,在酒店预订的例子中,可以大致梳理出以下业务查询:
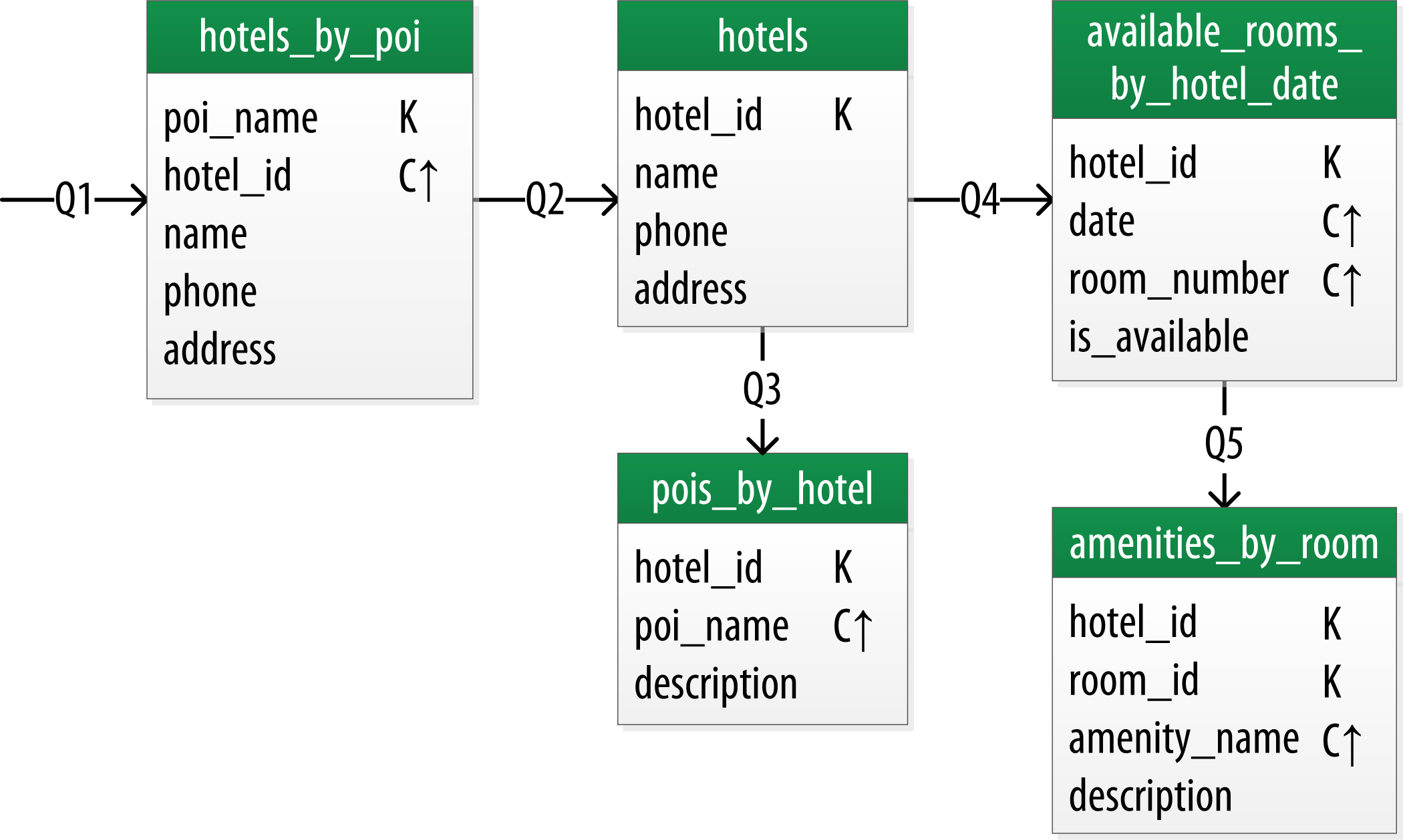
Q1: 查找某个景点附近的酒店
Q2: 查找某个酒店的信息
Q3: 查找某个酒店附近的景点
Q4: 在给定的日期范围内找到一个可用的房间
Q5: 查找房间的价格和设施
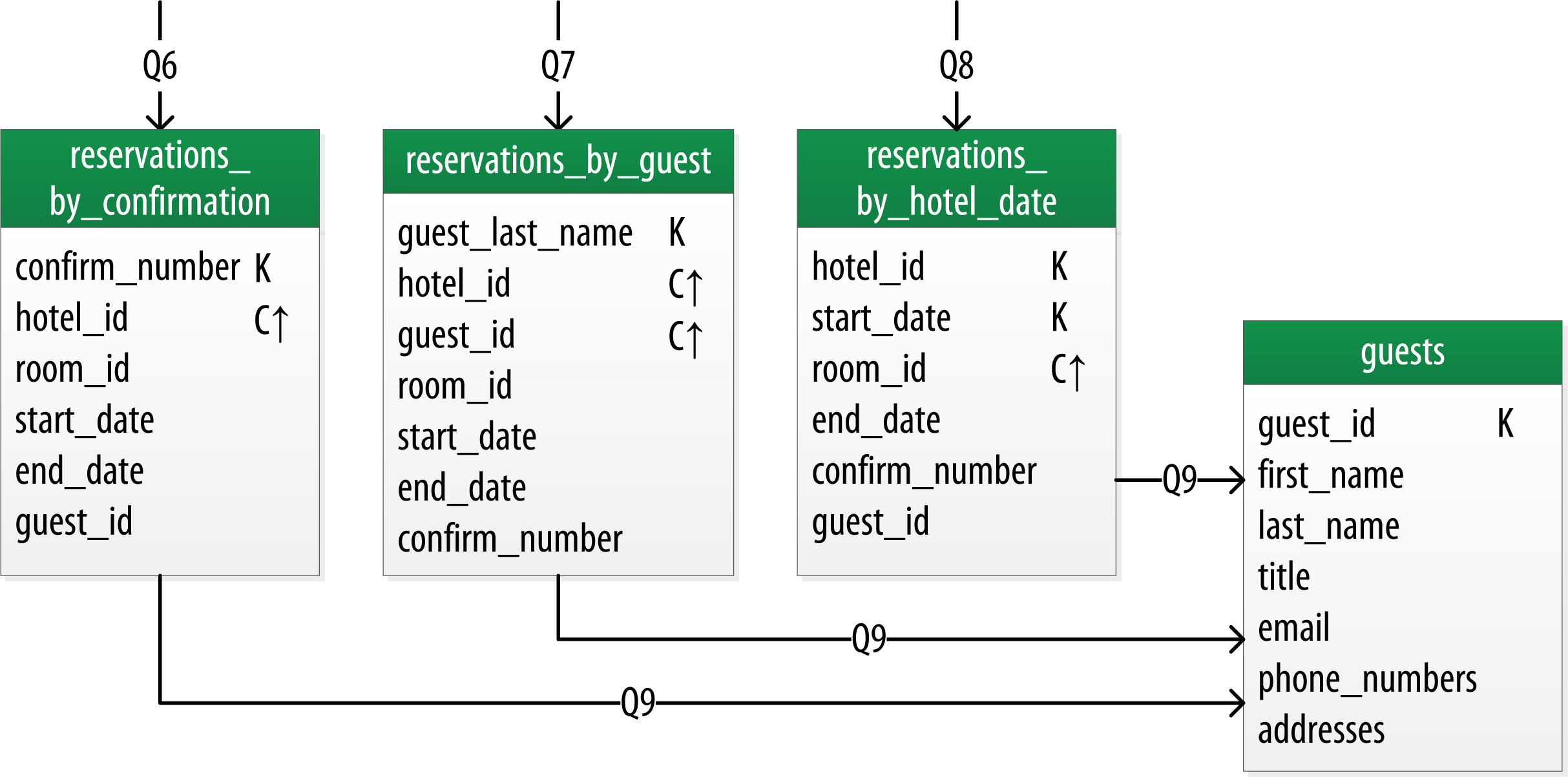
Q6: 通过确认码查找预订
Q7: 根据酒店、日期和顾客姓名查找预订
Q8: 按顾客姓名查找所有预订
Q9: 查看顾客详细信息
5. 逻辑数据建模
为了更生动形象地表示数据模型,这里采用下面这种图表方式:
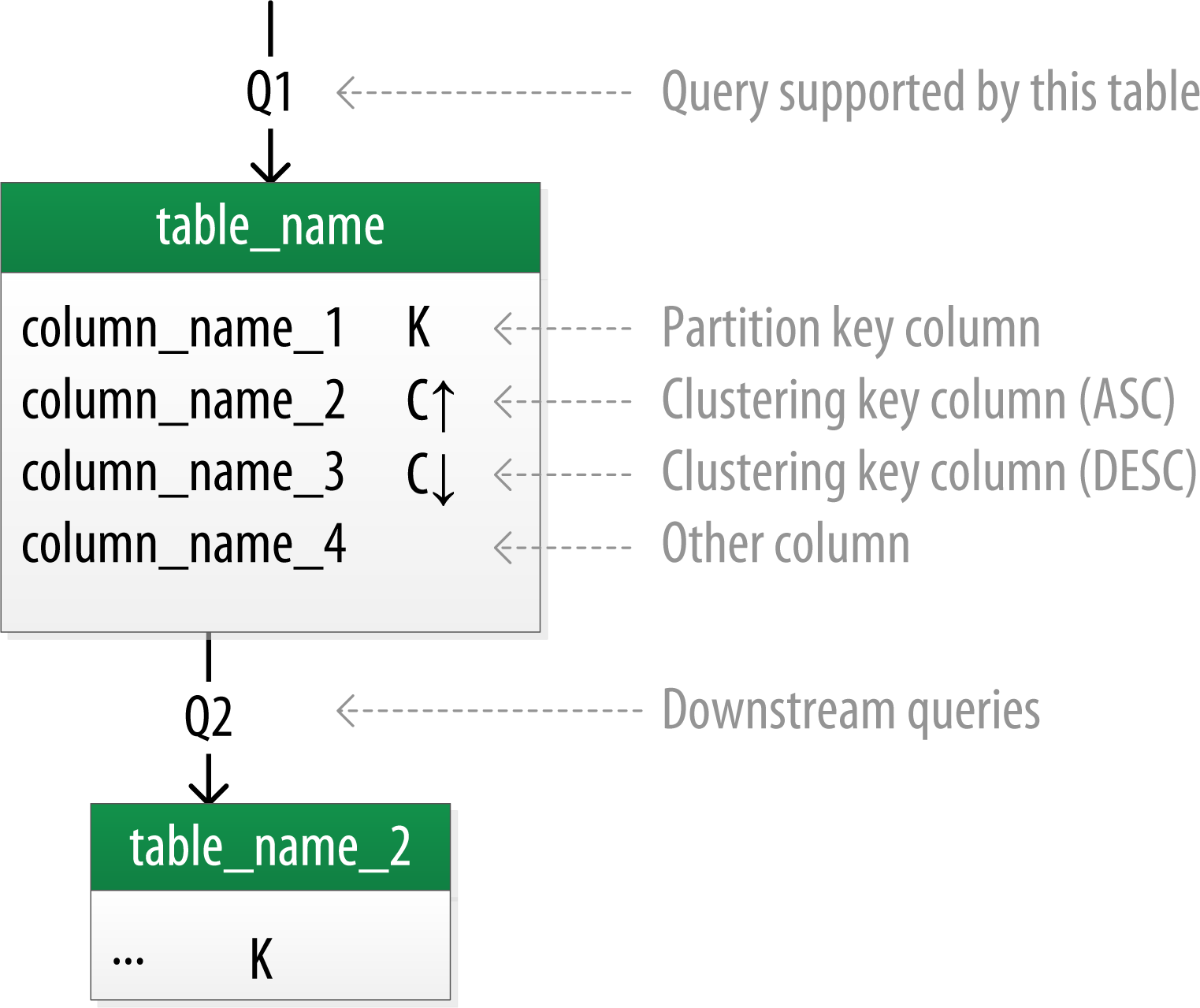
5.1. Hotel逻辑数据模型
按照上面的图表方式,酒店逻辑数据模型表示如下:
5.2. Reservation逻辑数据模型
同样的方式,预订逻辑数据模型表示如下:
6. 物理数据建模
(画外音:一切设计都是为了查询,这话听着很耳熟,哈哈,Elasticsearch说过,一切设计都是为了提高检索的性能)
为了方便理解,采用如下格式来表示。不用多说,看图说话:

酒店数据模型:
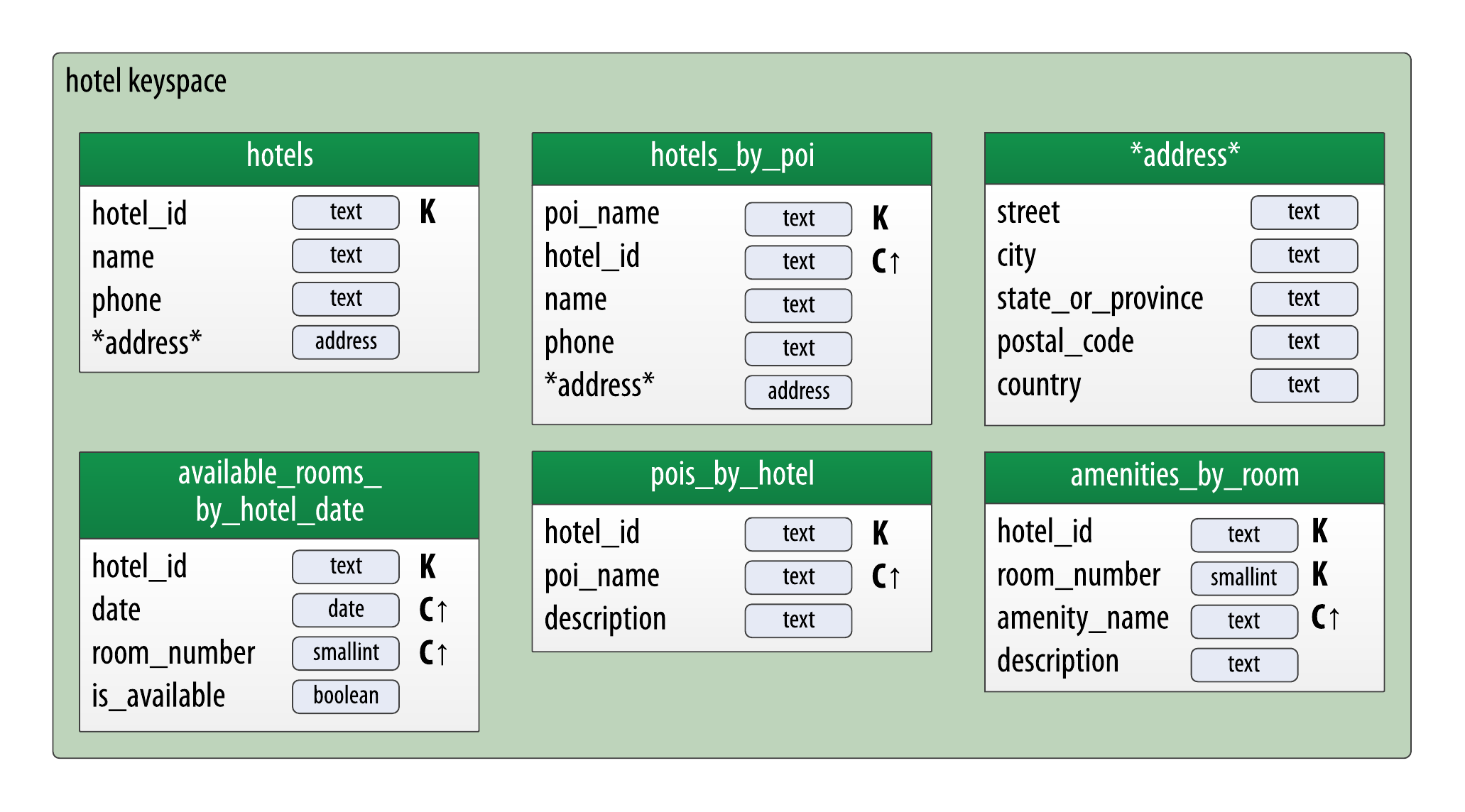
预订数据模型:

7. 评估和完善数据模型
7.1. 计算分区大小
首先要考虑的是,表的分区是否太大,或者换句话说,太宽。分区大小是通过存储在分区中的单元格(值)的数量来度量的。Cassandra的硬限制是每个分区有20亿个单元格(PS:类比Excel中的单元格),但是在达到这个限制之前,可能会遇到性能问题。
分区大小计算公式:N_v = N_r (N_c - N_{pk} - N_s) + N_s
其中:
N_r表示行数
N_c表示列数
N_pk表示主键列数
N_s表示静态列数
N_v表示单元格数量
那么,单元格数量 = 行数 × (总列数 - 主键列数 - 静态列数) + 静态列数
以available_rooms_by_hotel_date表为例,根据公式,该表的单元格总数 = 行数 × (4 - 3 -0) + 0
7.2. 计算磁盘大小
每种数据类型所占磁盘空间大小不一,粗略地可以用所有列所占磁盘大小乘以行数来计算
7.3. 拆分大分区
有一种称为bucketing的技术常被用来将数据分割成中等大小的分区。例如,可以通过向分区键添加一个month列(可能表示为一个整数)来分解available_rooms_by_hotel_date表。与原设计的对比如下图所示。虽然month列部分重复了date,但它提供了一种很好的方法,可以在分区中对相关数据进行分组,而且分区不会变得太大。

8. 定义数据库Schema
schema可以理解为数据库,一个schema就是指一个数据库
下面是为hotel keyspace定义的schema:
CREATE KEYSPACE hotel WITH replication =
{‘class’: ‘SimpleStrategy’, ‘replication_factor’ : 3};
CREATE TYPE hotel.address (
street text,
city text,
state_or_province text,
postal_code text,
country text );
CREATE TABLE hotel.hotels_by_poi (
poi_name text,
hotel_id text,
name text,
phone text,
address frozen<address>,
PRIMARY KEY ((poi_name), hotel_id) )
WITH comment = ‘Q1. Find hotels near given poi’
AND CLUSTERING ORDER BY (hotel_id ASC) ;
CREATE TABLE hotel.hotels (
id text PRIMARY KEY,
name text,
phone text,
address frozen<address>,
pois set )
WITH comment = ‘Q2. Find information about a hotel’;
CREATE TABLE hotel.pois_by_hotel (
poi_name text,
hotel_id text,
description text,
PRIMARY KEY ((hotel_id), poi_name) )
WITH comment = Q3. Find pois near a hotel’;
CREATE TABLE hotel.available_rooms_by_hotel_date (
hotel_id text,
date date,
room_number smallint,
is_available boolean,
PRIMARY KEY ((hotel_id), date, room_number) )
WITH comment = ‘Q4. Find available rooms by hotel date’;
CREATE TABLE hotel.amenities_by_room (
hotel_id text,
room_number smallint,
amenity_name text,
description text,
PRIMARY KEY ((hotel_id, room_number), amenity_name) )
WITH comment = ‘Q5. Find amenities for a room’;
reservation keyspace 的 schema 如下:
CREATE KEYSPACE reservation WITH replication = {‘class’:
‘SimpleStrategy’, ‘replication_factor’ : 3};
CREATE TYPE reservation.address (
street text,
city text,
state_or_province text,
postal_code text,
country text );
CREATE TABLE reservation.reservations_by_confirmation (
confirm_number text,
hotel_id text,
start_date date,
end_date date,
room_number smallint,
guest_id uuid,
PRIMARY KEY (confirm_number) )
WITH comment = ‘Q6. Find reservations by confirmation number’;
CREATE TABLE reservation.reservations_by_hotel_date (
hotel_id text,
start_date date,
end_date date,
room_number smallint,
confirm_number text,
guest_id uuid,
PRIMARY KEY ((hotel_id, start_date), room_number) )
WITH comment = ‘Q7. Find reservations by hotel and date’;
CREATE TABLE reservation.reservations_by_guest (
guest_last_name text,
hotel_id text,
start_date date,
end_date date,
room_number smallint,
confirm_number text,
guest_id uuid,
PRIMARY KEY ((guest_last_name), hotel_id) )
WITH comment = ‘Q8. Find reservations by guest name’;
CREATE TABLE reservation.guests (
guest_id uuid PRIMARY KEY,
first_name text,
last_name text,
title text,
emails set,
phone_numbers list,
addresses map<text,
frozen<address>,
confirm_number text )
WITH comment = ‘Q9. Find guest by ID’;
9. 文档
https://cassandra.apache.org/doc/latest/data_modeling/index.html
https://cassandra.apache.org/doc/latest/data_modeling/intro.html
https://cassandra.apache.org/doc/latest/data_modeling/data_modeling_rdbms.html