目录
一.概念介绍
1.1 gitlab-ci && 自动化部署工具的运行机制
1.2 自动化部署给我们带来的好处
二.知识预备
2.1 gitlab-ci涉及的抽象概念(Runner/PipeLine/Executor/Job )
2.2 YML文件的基本语法规则
2.3 .gitlab-ci.yml配置的特定关键字
三.CI实战
3.1 编写一个gitlab-ci的“hello world”
四.坑点总结
五.gitlab-ci进阶
5.1 YML的片段复用和模块化
5.2 gitlab-ci提供的其他配置关键字一.概念介绍
1.1 gitlab-ci && 自动化部署工具的运行机制
以gitlab-ci为例:
(1) 通过在项目根目录下配置.gitlab-ci.yml文件,可以控制ci流程的不同阶段,例如install/检查/编译/部署服务器。gitlab平台会扫描.gitlab-ci.yml文件,并据此处理ci流程
(2) ci流程在每次团队成员push/merge后之后触发。每当你push/merge一次,gitlab-ci都会检查项目下有没有.gitlab-ci.yml文件,如果有,它会执行你在里面编写的脚本,并完整地走一遍从intall => eslint检查=>编译 =>部署服务器的流程
(3)gitlab-ci提供了指定ci运行平台的机制,它提供了一个叫gitlab-runner的软件,只要在对应的平台(机器或docker)上下载并运行这个命令行软件,并输入从gitlab交互界面获取的token,就可以把当前机器和对应的gitlab-ci流程绑定,也即:每次跑ci都在这个平台上进行。
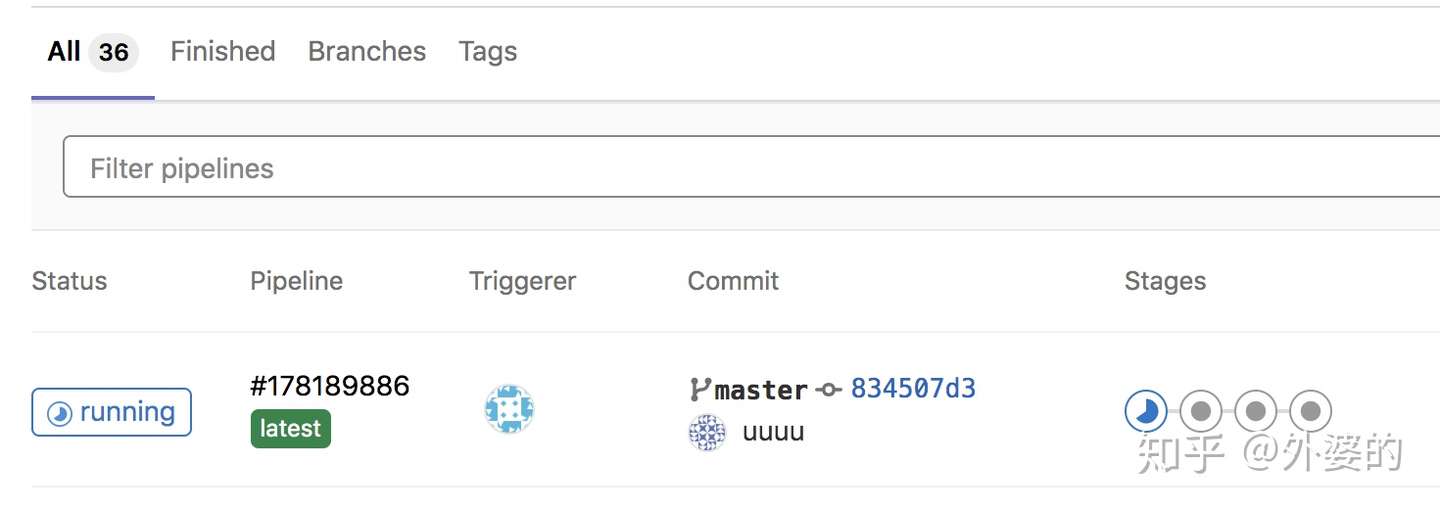
(4).gitlab-ci的所有流程都是可视化的,每个流程节点的状态可以在gitlab的交互界面上看到,包括执行成功或失败。如下图所示,因为它的执行看上去就和多节管道一样,所以我们通常用“pipeLine”来称呼它
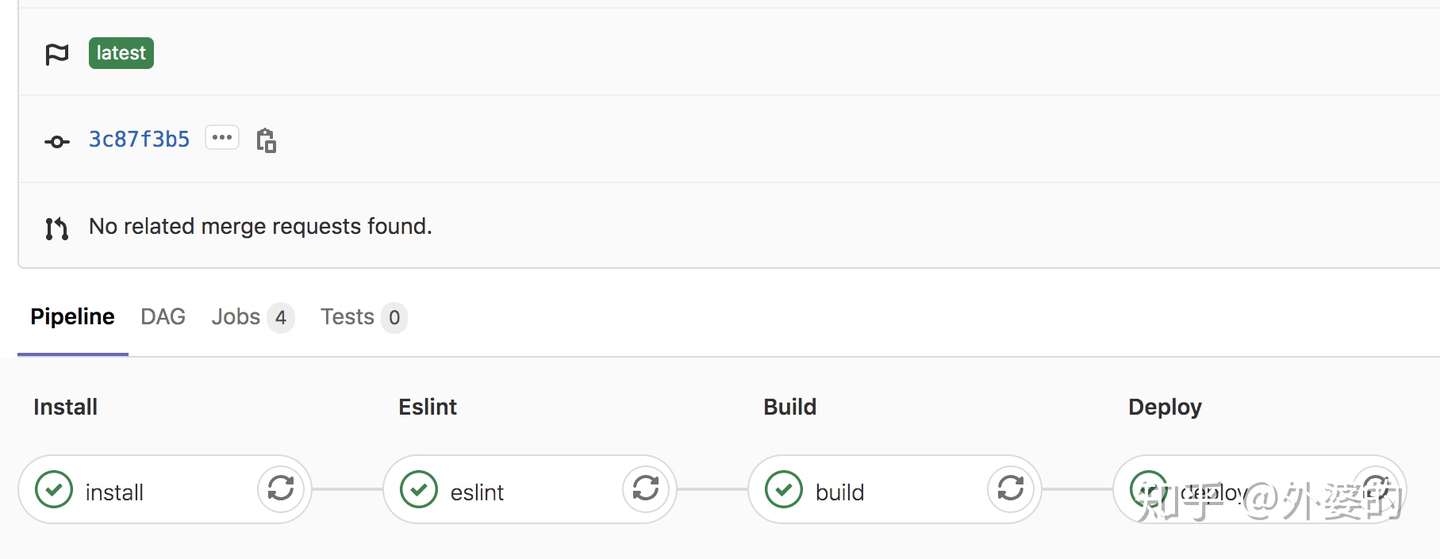
(5).不同push/merge所触发的CI流程不会互相影响,也就是说,你的一次push引发的CI流程并不会因为接下来另一位同事的push而阻断,它们是互不影响的。这一个特点方便让测试同学根据不同版本进行测试。
(6)pipeline不仅能被动触发,也是可以手动触发的。
1.2 自动化部署給我们带来的好处
自动化部署的好处体现在几个方面
1.提高前端的开发效率和开发测试之间的协调效率
Before
如果按照传统的流程,在项目上线前的测试阶段,前端同学修复bug之后,要手动把代码部署之后。才能通知测试同学在测试环境进行测试。
这会造成几个问题:本身手动部署服务的工作是比较繁琐的,占用了开发时间。同时开发-测试之间的环节的耦合问题,则会增加团队沟通成本。
After
通过gitlab-ci,前端开发在提交代码之后就不用管了,ci流程会自动部署到测试或集成环境的服务器。很大程度上节约了开发的时间。
同时,因为开发和测试人员可以共用gitlab里的pipeline界面, 测试同学能够随时把握代码部署的情况,同时还可以通过交互界面手动启动pipeline,自己去部署测试,从而节约和开发之间的沟通时间。
2.从更细的粒度把握代码质量
我们可以把eslint或其他的代码检查加到pipeline流程中,每当团队成员提交和合并一次,pipeline都会触发一次并对代码做一次全面检测,这样就从一个更细的粒度上控制代码质量了。
二.知识预备
介绍完gitlab-ci的基本概念,接下来我将会介绍编写一个gitlab-ci用例所需要的知识。这是在实战之前的一点准备工作,主要包括三部分
- gitlab-ci涉及的抽象概念
- YML文件的基本语法规则
- .gitlab-ci.yml配置的特定关键字
2.1 gitlab-ci涉及的抽象概念
首先要了解的是gitlab-ci中涉及的一些基本概念
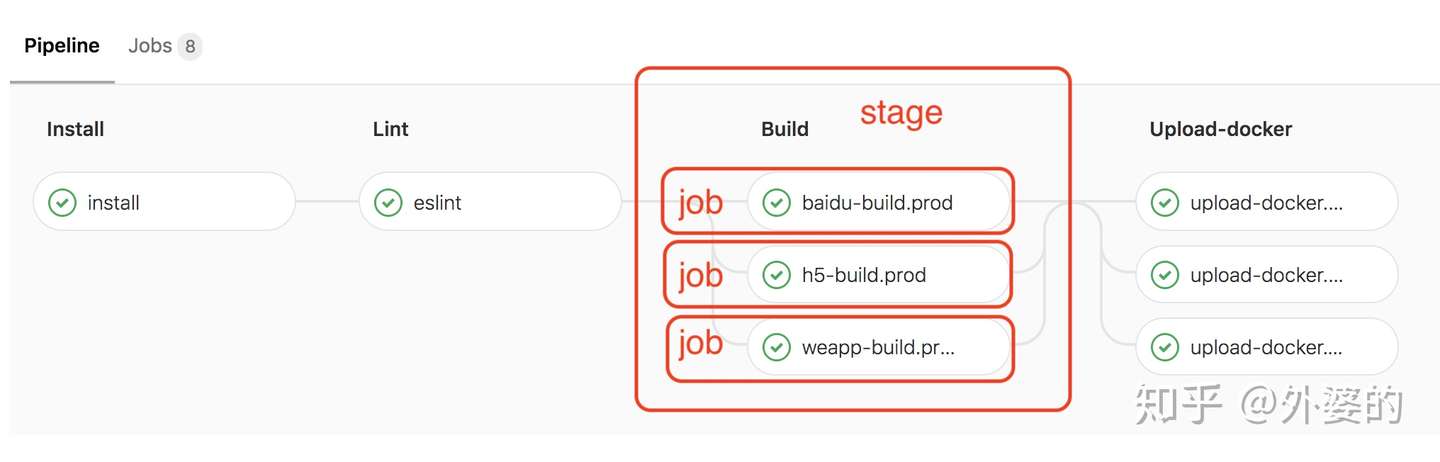
1.Pipeline & Job
Pipeline是Gitlab根据项目的.gitlab-ci.yml文件执行的流程,它由许多个任务节点组成, 而这些Pipeline上的每一个任务节点,都是一个独立的Job
Job在YML中的配置我们将会在下面介绍,现在需要知道的是:每个Job都会配置一个stage属性,来表示这个Job所处的阶段。
一个Pipleline有若干个stage,每个stage上有至少一个Job,如下图所示:
2.Runner
Runner可以理解为:在特定机器上根据项目的.gitlab-ci.yml文件,对项目执行pipeline的程序。Runner可以分为两种: Specific Runner 和 Shared Runner
- Shared Runner是Gitlab平台提供的免费使用的runner程序,它由Google云平台提供支持,每个开发团队有十几个。对于公共开源项目是免费使用的,如果是私人项目则有每月2000分钟的CI时间上限。
- Specific Runner是我们自定义的,在自己选择的机器上运行的runner程序,gitlab给我们提供了一个叫gitlab-runner的命令行软件,只要在对应机器上下载安装这个软件,并且运行gitlab-runner register命令,然后输入从gitlab-ci交互界面获取的token进行注册, 就可以在自己的机器上远程运行pipeline程序了。
Gitlab-runner下载链接:https://docs.gitlab.com/runner/install/
Shared Runner 和 Specific Runner的区别
- Shared Runner是所有项目都可以使用的,而Specific Runner只能针对特定项目运行
- Shared Runner默认基于docker运行,没有提前装配的执行pipeline的环境,例如node等。而Specific Runner你可以自由选择平台,可以是各种类型的机器,如Linux/Windows等,并在上面装配必需的运行环境,当然也可以选择Docker/K8s等
- 私人项目使用Shared Runner受运行时间的限制,而Specific Runner的使用则是完全自由的。

3.Executor
什么是Executor? 我们上面说过 Specific Runner是在我们自己选择的平台上执行的,这个平台就是我们现在说到的“Executor”,我们在特定机器上通过gitlab-runner这个命令行软件注册runner的时候,命令行就会提示我们输入相应的平台类型。可供选择的平台一共有如下几种,下面是一张它们各方面特点的比较表格
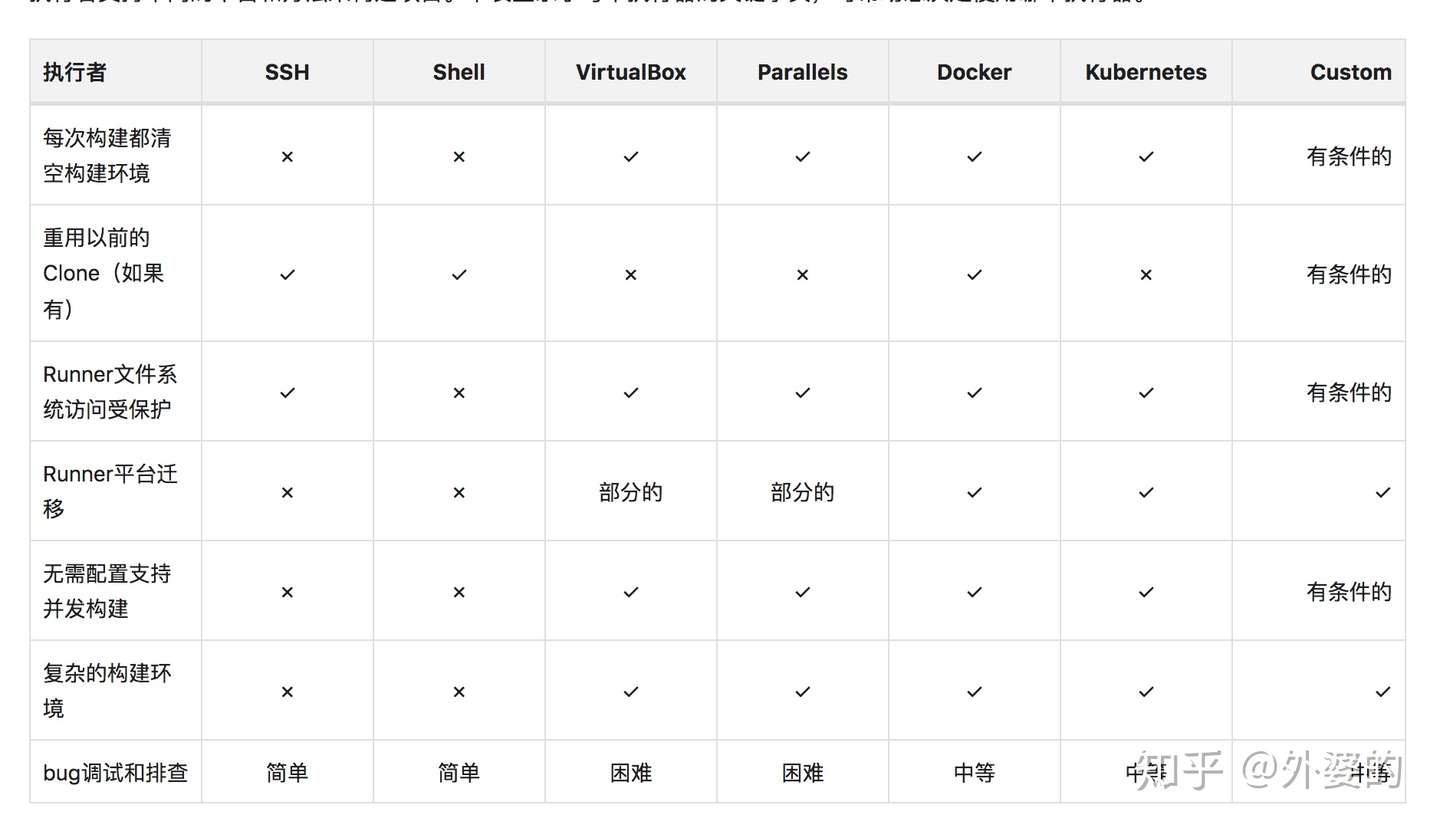
下面是表格的原文链接
参考链接:https://docs.gitlab.com/runner/executors/#selecting-the-executor
为了简单起见,我下面的实践部分使用的是我自己的本地Mac机器作为Executor,并且在注册时选择“Shell”作为Executor类型。
2.2 YML文件的基本语法规则
CI流程的运行控制,决定于项目根目录下编写的配置文件—— .gitlab-ci.yml,正因如此,我们需要掌握YML的基本语法规则。
YML是一种编写配置文件的语言,比JSON更为简洁和方便,因此,我们首先要掌握的就是YML文件的编写语法。
一份简单的YML文件长下面这个样子:
install-job: # 注释
tags:
- sss
stage: install
script:
- npm install从这里我们就可以看出:
- YML通过缩进组织层级
- YML里允许通过#符号编写注释
在基本结构上,YML和 JSON也类似
- JSON是由对象,数组,以及对象和数组的嵌套结构组成的
- YML也是由对象,数组,以及对象和数组的嵌套结构组成的。
如下所示:
YML中的数组写法
colors
- red
- blue
- yellow相当于JSON中的
{ "colors": ["red","blue","yellow"] }YML中的对象写法:
people:
name: zhangsan
age: 14相当于JSON中的
{
"people": {
"name": "zhangsan"
"age": 14
}
}当然也可以是数组和对象之间形成的嵌套结构
a:
b:
- d
c: e相当于
{
"a": {
"b": [ "d" ],
"c": "e"
}
}从JSON到YML之间的过渡学习的注意要点:
- 你不再需要“{}”这种符号去区分层级边界了,你需要考虑使用缩进
- 这里可以使用注释,用#符号
- 如果不涉及特殊符号比如“[”,你一般是不需要給YML中的字符串加双引号或者单引号的(当然加了也可以)
了解了这些,对于编写一个gitlab-ci的hello world已经没有问题了。
当然YML还有着比JSON更为丰富的功能,比如用”&"符号和"<<:*”符号可以实现的片段导入的功能,以及gitlab-ci提供的include关键字和extend关键字等提供的结构编排功能。这些我将在最后面的小节中讲解,这里暂时不多赘述
2.3 gitlab-ci.yml配置的特定关键字
在了解了YML文件的语法格式后,接下来需要了解的就是gitlab-ci独特的配置关键字,这些关键字将在.gitlab-ci.yml中使用,并用来控制一个pipeline具体的运作过程
gitlab提供了很多配置关键字,其中最基础和常用的有这么几个
- stages
- stage
- script
- tags
stages & stage
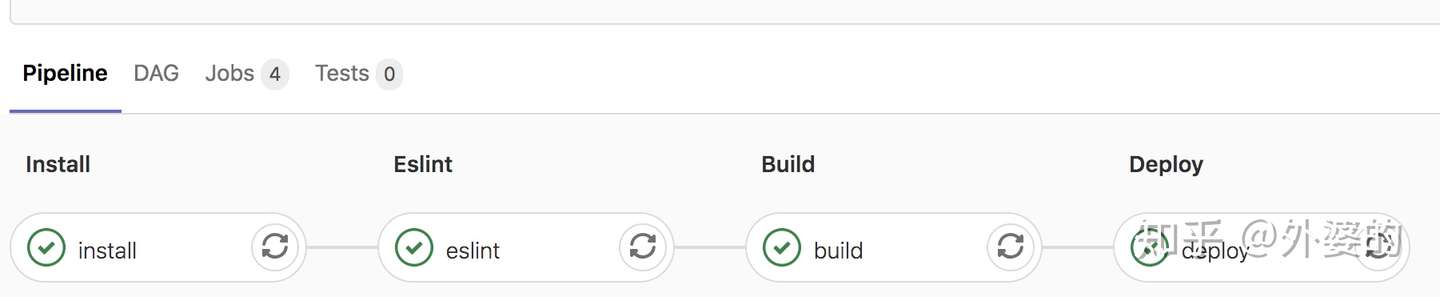
stages定义在YML文件的最外层,它的值是一个数组,用于定义一个pipeline不同的流程节点
例如我们定义如下:
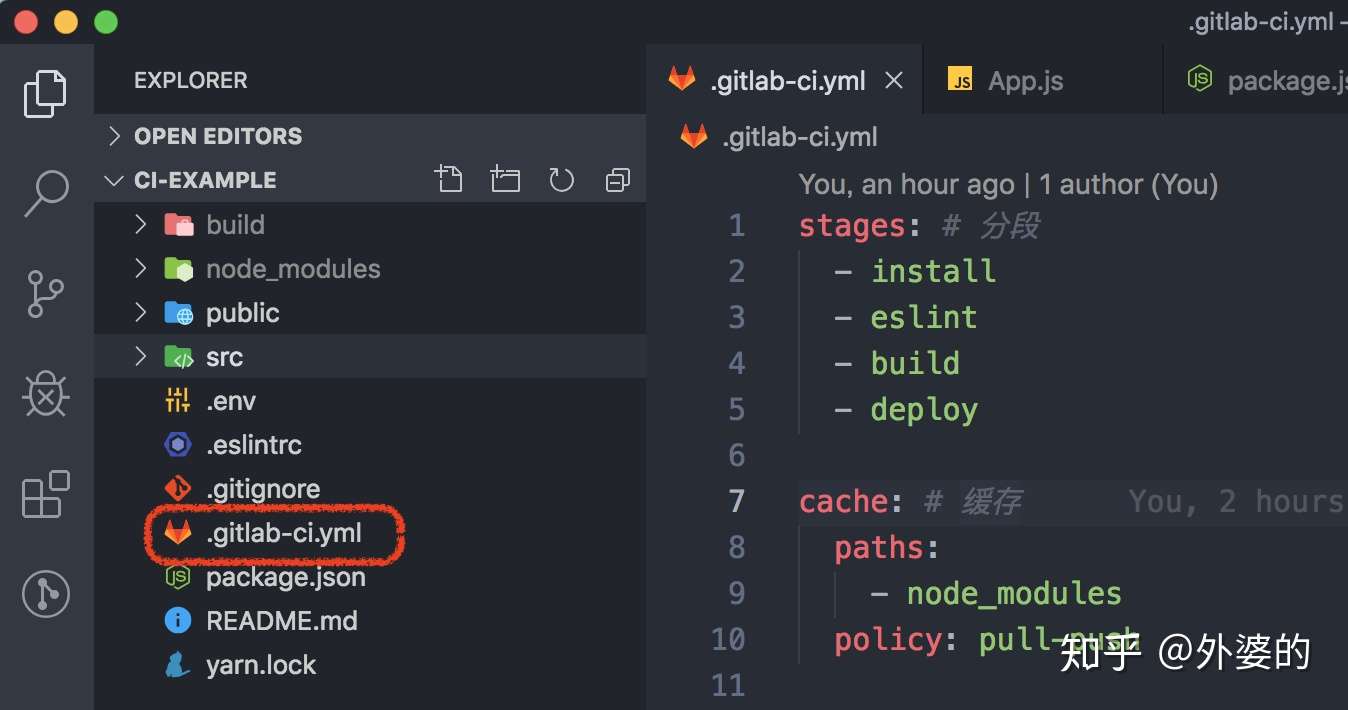
stages: # 分段
- install
- eslint
- build
- deploy则在Gitlab交互界面中能够看到如下展示
我们上面说过:Job是pipeline的任务节点,它构成了pipeline的基本单元
而stage/script/tags这三个关键字,都是作为Job的子属性来使用的,如下所示,install就是我们定义的一个Job
install:
tags:
- sss
stage: install
script:
- npm install
stage
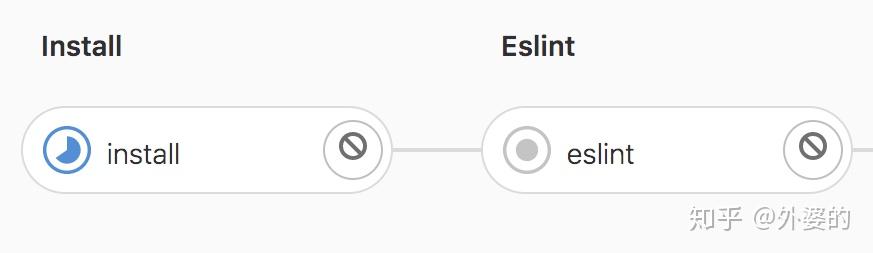
是一个字符串,且是stages数组的一个子项,表示的是当前的pipeline节点。
当前stage的执行情况能在交互面板上能看的清清楚楚:
- 正在执行是蓝色
- 尚未执行是灰色
- 执行成功是绿色
- 执行失败是红色

script
它是当前pipeline节点运行的shell脚本(以项目根目录为上下文执行)。
这个script是我们控制CI流程的核心,我们所有的工作:从安装,编译到部署都是通过script中定义的shell脚本来完成的。
如果脚本执行成功,pipeline就会进入下一个Job节点,如果执行失败那么pipeline就会终止
tags
tags是当前Job的标记,这个tags关键字是很重要,因为gitlab的runner会通过tags去判断能否执行当前这个Job
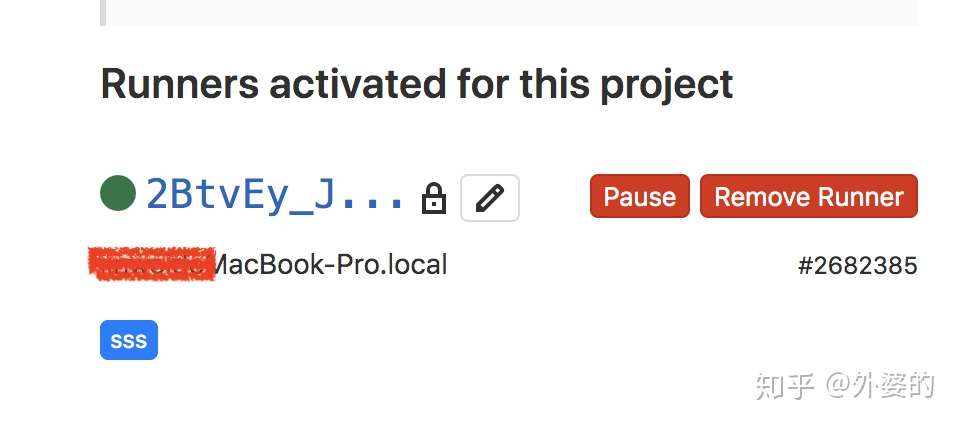
例如我们在gitlab的面板中能看到当前激活的runner的信息
Gitlab项目首页=> setting => CI/CD => Runners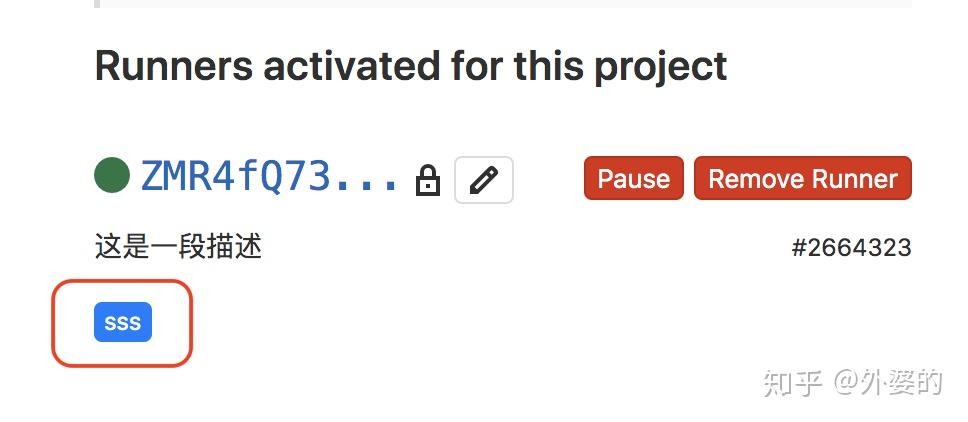
上面的这个sss就是当前Runner的tags,这意味着:这个runner只会执行tag为sss的Job。如果一个Job没有tag或者tag不是sss,那么即使这个Runner是激活且空闲的,也不会去执行!
基本的gitlab-ci关键字就介绍结束了,有了这些知识对于编写一个gitlab-ci的”hello world”已经足够了。对于更多的关键字的相关知识,将在文章最后再进行介绍
三.gitlab-ci实战
3.1 编写一个gitlab-ci的"hello world"
好,说了这么多终于到了实践的部分了,请原谅前面的啰嗦,下面我将会展示一下如何从零开始实践一个gitlab-ci的Hello world:
1.在平台上下载并安装Gitlab-runner命令行
我是在Mac上跑的ci,所以下面的适用于OSX系统(如果是其他平台,可自行参考以下官方链接中的相关资料)
参考资料: https://docs.gitlab.com/runner/install/
依次运行:
sudo curl --output /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-darwin-amd64
sudo chmod +x /usr/local/bin/gitlab-runner备注: 这个下载过程可能会很慢,你可以复制上面的链接到浏览器中FQ下载,然后下载完毕再进行后续处理
2.初始化gitlab-runner
cd ~
gitlab-runner install
gitlab-runner start最后输出如下,说明成功了。
3.注册Runner
运行完gitlab-runner start只是完成了初始化,接下来你还要通过注册才能运行runner
参考链接: https://docs.gitlab.com/runner/register/index.html
注册runner只需要一条运行命令:
sudo gitlab-runner register然后写入相应的token,url和tag等相关信息,就注册完毕了。

上面要求输入的Runner绑定的token和url, 获取方式如下:
Gitlab项目首页=> setting => CI/CD => Runners => Specific Runners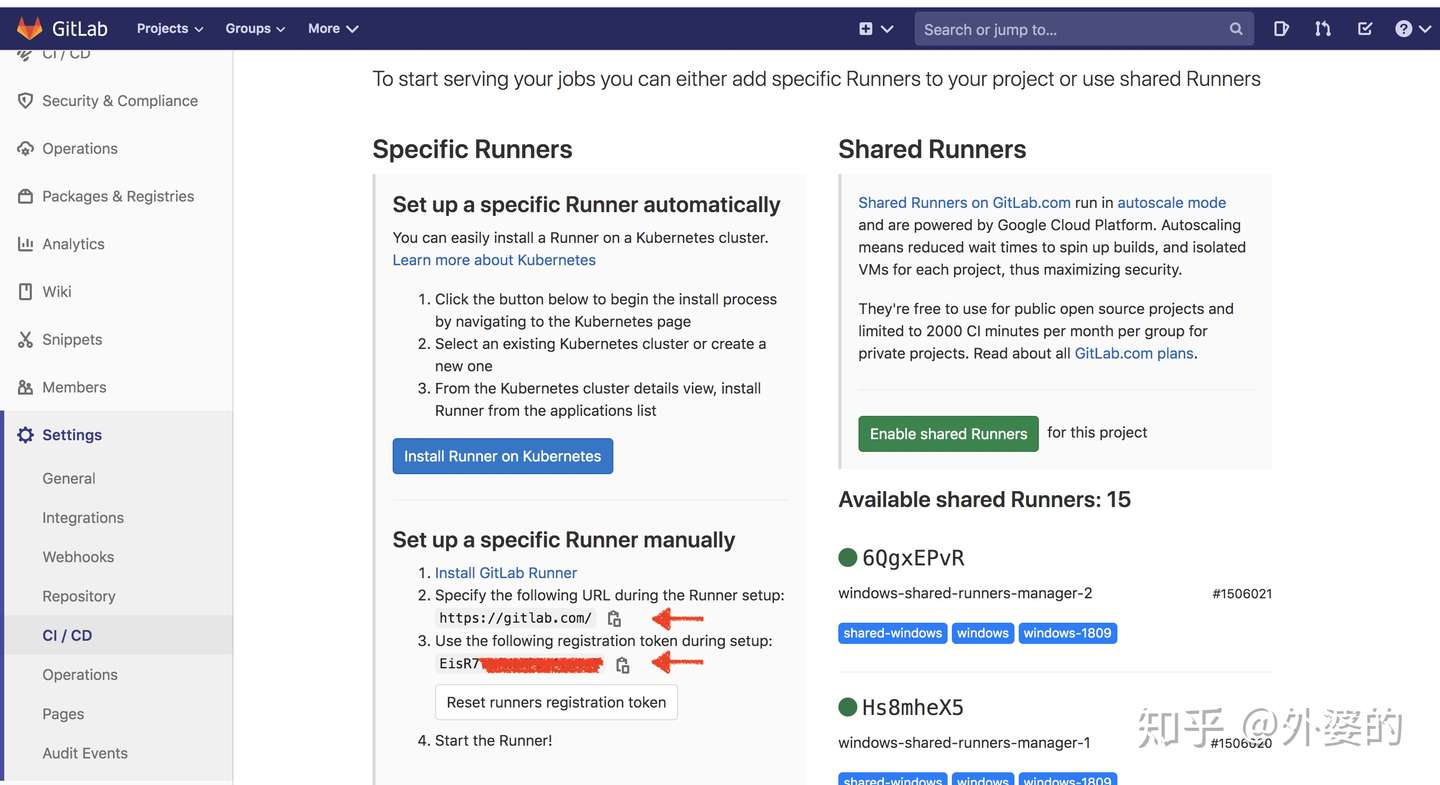
4.激活Runner
注册完了可能还需要激活,这时我们可以看下面板,如果有个黑色的感叹号,这说明runner注册成功了,但是尚未激活(如果是绿色的说明已经激活,本步骤跳过)
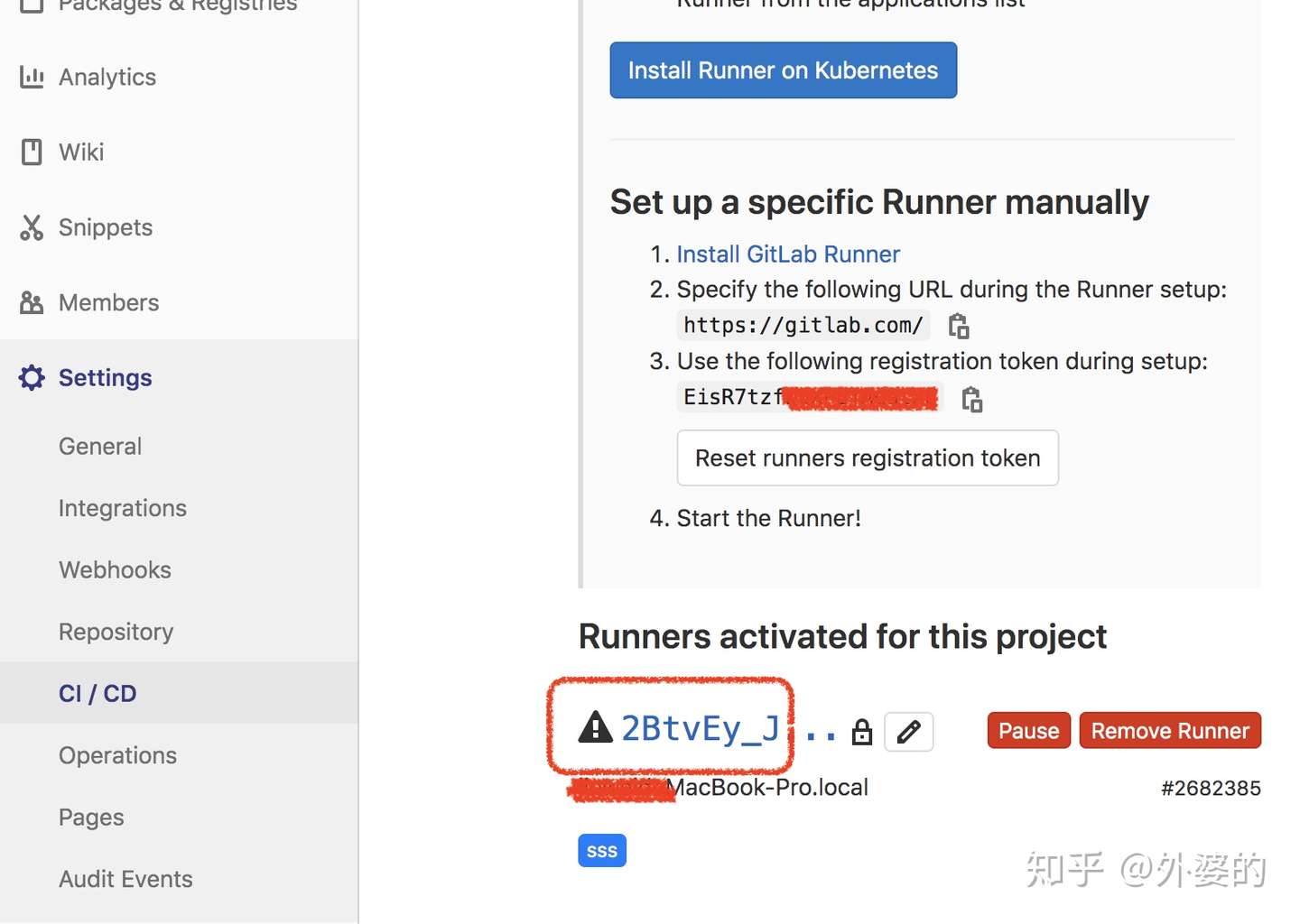
激活方法是本地运行:
sudo gitlab-runner verify输出

这时候回去看Gitlab面板里的Runner参数:
是绿色就说明激活成功了
5.梳理和规划Pipeline的不同阶段和过程
在编写.gitlab-ci.yml前,首先需要考虑的是我们的pipeline分几个阶段处理。
从前端工程师的角度出发,一个前端项目的PipeLine处理包括以下阶段
<1> install阶段
就是执行npm install命令,根据package.json安装node_modules依赖包
<2> eslint阶段
执行eslint检查,判断代码格式是否符合规范,如果不符合则pipeline终止。
在这之前,我先通过npm install eslint安装了eslint检查工具,然后在项目根目录下配置了.eslintrc文件。这部分可自行参考相关资料,这里暂不多赘述。
<3>build阶段
编译生成生产代码,可以通过webpack之类的打包工具执行编译。当然可以通过框架提供的编译命令进行编译,例如我这个示例项目是用 react-scripts脚手架搭建的,所以通过npx react-scripts build进行编译。
<4>deploy阶段
deploy也就是部署阶段,也就是把刚才bulid阶段生成的生产代码,部署到生产访问的服务器上。这里又具体有以下两部分工作要做
A.申请服务器 & 安装web服务 (准备工作)
(1)我本次使用的是百度云的云服务器(每天9点的时候可以抢有一定免费使用期限的服务器)
(2)然后在本地终端通过ssh远程登陆服务器,并安装apache以提供web服务
sudo apt-get install apache2(3)然后,安装完后的apache会在服务器下新增/var/www/html/目录, 这个目录就是存放网站资源的位置。
(4)最后我们只需要在每次部署的时候把生产的单页面拷贝到这个页面下,就能在浏览器上通过对应的 IP+路径 来访问Web页面了。
B. 部署资源(每次pipeline都进行)
我下面的示例中,是通过 scp 这一命令,将本地机器代码远程拷贝到云服务器上。
因为这一命令需要输入密码,所以通过 sshpass 命令携带密码再执行scp:
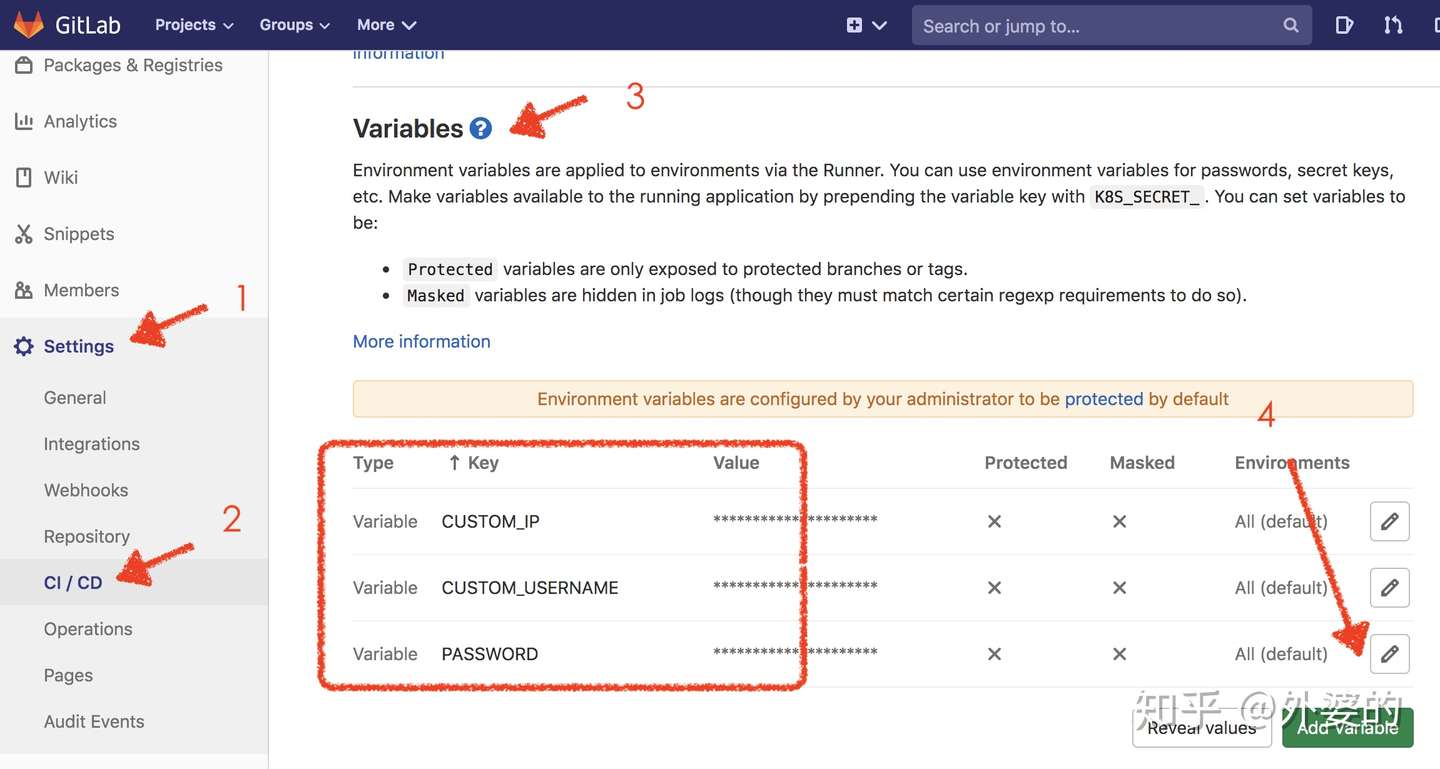
sshpass -p $PASSWORD scp -r ./build $CUSTOM_USERNAME@$CUSTOM_IP:/var/www/html这里说明一下,Gitlab有自定义变量的功能,例如我们觉得直接在YML中写入密码/账号等信息不太好,那么可以通过美元符号$写入一个预定义的变量,然后在Gitlab面板上输入它
7.编写.gitlab-ci.yml配置文件
回顾一下之前YML语法规则和gitlab-ci配置关键字的知识,就不难编写出以下YML文件
stages: # 分段
- install
- eslint
- build
- deploy
cache: # 缓存
paths:
- node_modules
- build
install-job:
tags:
- sss
stage: install
script:
- npm install
eslint-job:
tags:
- sss
stage: eslint
script:
- npm run eslint
build-job:
tags:
- sss
stage: build
script:
- npm run build
deploy-job:
tags:
- sss
stage: deploy
script:
- sshpass -p $PASSWORD scp -r ./build $CUSTOM_USERNAME@$CUSTOM_IP:/var/www/htmlpackage.json如下
{
...
"scripts": {
"start": "react-scripts start",
"build": "npx react-scripts build",
"eslint": "eslint ./src",
},
....
}8.提交项目代码
OK!终于到最后一步了,commit然后push
可以看到运行如下
跑完后
最后输入我们部署的IP看看我们部署的网页
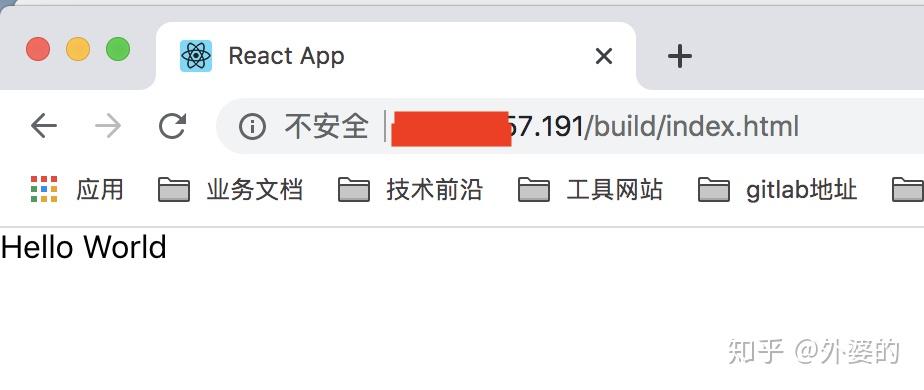
发现已经把我们的项目代码部署上去了
四. Gitlab-ci坑点详解
说多了都是泪。。。。。下面总结一下使用过程中遇到的典型坑点
1.Runner未激活问题
有时候注册之后,查看面板上的Runner信息,可能会发现Runner处在未激活状态
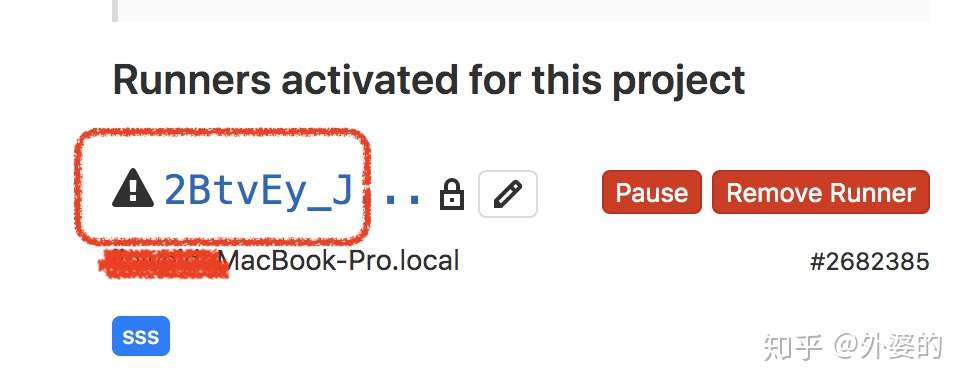
解决方法:
运行以下命令重新启动runner
sudo gitlab-runner verify
sudo gitlab-runner restart
2.Job一直挂起,没有Runner来处理
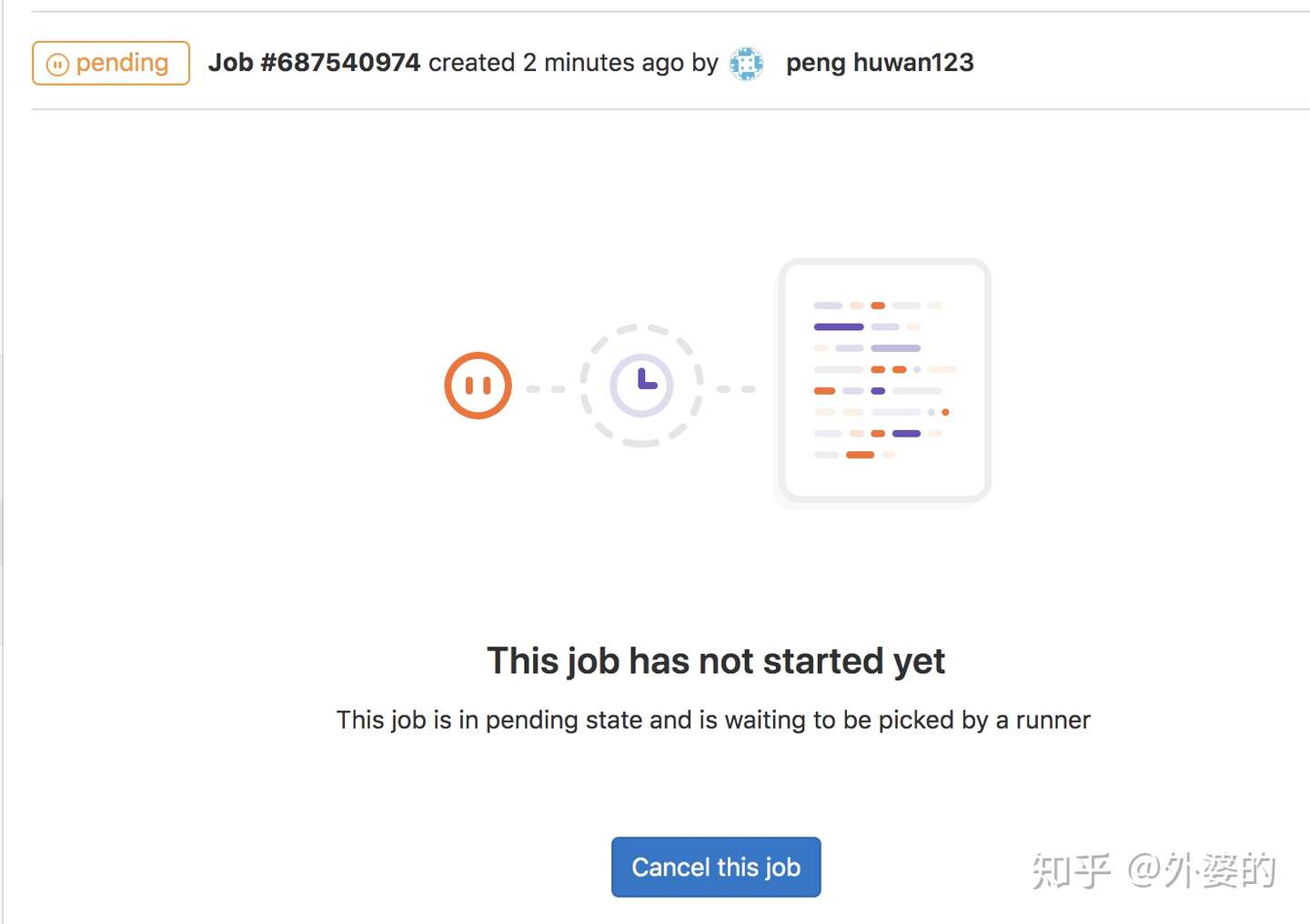
1.首先考虑的是不是Runner没有激活,如果没有那么按上面方式处理
2.还可能是tag没有匹配到,上面说过,Runner注册时是要填写绑定tag的,如果你在YML里面编写Job没有带上tag是不会有自定义Runner来处理。解决方法:给Job加tags
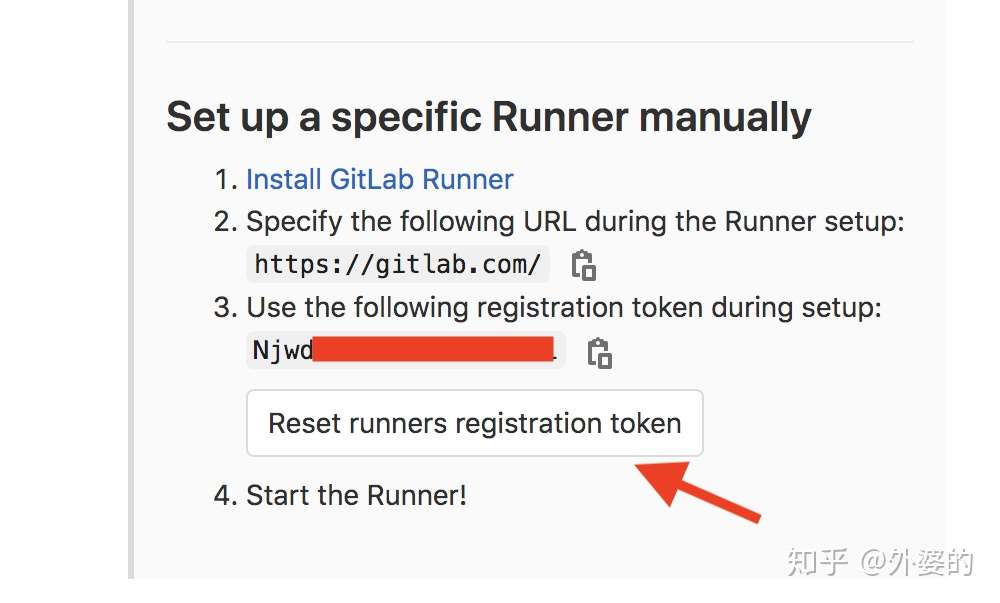
3.最后一种可能:你连续注册了多个Runner,这些Runner冲突了,或者是新注册的Runner和旧Runner使用了同一个token,这时候的解决方法如下:
先删掉本地其他旧的Runner
sudo gitlab-runner unregister --all-runners然后重置token,并使用更新后的token重新注册一个Runner
3.specific Runner被Share Runner抢占了Job
有时候你可能会发现:你的Job并没有被你新建的Runner执行,而是被Share Runner抢先执行了。你如果不想要Share Runner,你可以在Gitlab面板上关掉
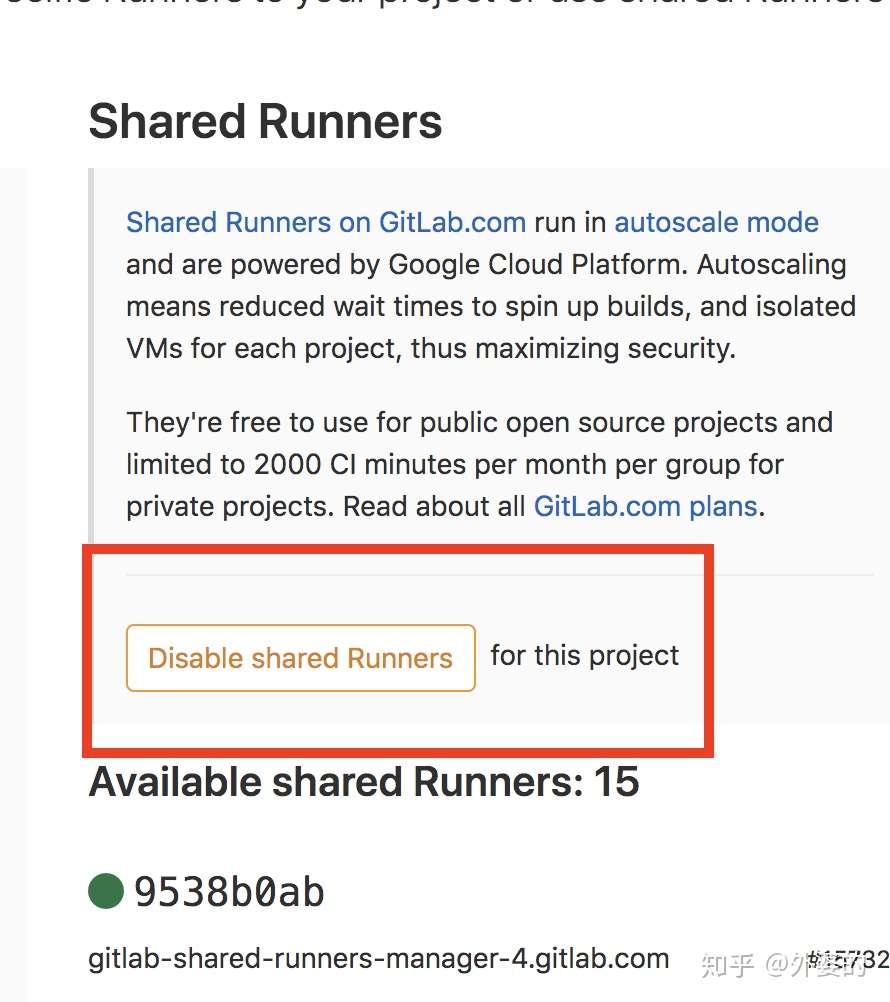
五.gitlab-ci进阶
5.1 YML的片段复用和模块化
上面我们编写了gitlab-ci的"hello world"。但在实际项目的运行中,.gitlab-ci.yml的编写可能会渐趋复杂。那么这个时候YML的一些其他语法功能就派上用场了,上面我们将JSON和YML的基本结构做比较并发现它们的相似之处,但实际上,YML提供了比JSON更为丰富的功能。
YML的片段复用功能
试思考:如果有一段配置片段会被很多Job使用,那么如果重复写入片段,则会使我们的YML文件变得过分冗长。
而如果能把这段提前进行定义,并根据别名进行导入,就能让YML文件简洁很多了。
YML的语法天然提供了这个功能:
- 使用 &符号可以定义一个片段的别名
- 使用 <<符号和 * 符号可以将别名对应的YML片段导入
.common-config: &commonConfig
only: # 表示仅在develop/release分支上执行
refs:
- develop
- release
install-job:
# 其他配置 ....
<<: *commonConfig
build-job:
# 其他配置 ....
<<: *commonConfig
YML的模块化功能
试思考,如果我们配置脚本很长的话,我们一定要把它写在.gitlab-ci.yml这单独一个文件里吗?
能否将它分成多个yml文件,然后把其他YML文件导入到入口YML文件(.gitlab-ci.yml)中呢。
gitlab-ci提供的include关键字便可实现这个功能, 它可以用来导入外部的YML文件。
例如我们有如下的YML结构
├── .gitlab-ci.h5.yml'
├── .gitlab-ci.bd.yml'
├── .gitlab-ci.wx.yml
└── .gitlab-ci.yml那么在.gitlab-ci.yml中这么写,就可以对它们做合并
include:
- '/.gitlab-ci.wx.yml'
- '/.gitlab-ci.bd.yml'
- '/.gitlab-ci.h5.yml'gitlab-ci还提供了extend关键字,它的功能和前面提到的YML的片段导入的功能是一样的,
不过可读性更好一些。
.common-config:
only: # 表示仅在develop/release分支上执行
refs:
- develop
- release
install-job:
# 其他配置 ....
extends: .common-config
build-job:
# 其他配置 ....
extends: .common-config
5.2 Gitlab-ci的其他配置项
cache关键字
cache关键字是需要特别着重讲的一个关键字。顾名思义,它是用来做缓存的。
为什么要做缓存呢? 当然是为了重复运行pipeline的时候不会重复安装全部node_modules的包,从而减少pipeline的时间,提高pipeline的性能。
但是,这并不是cache关键字唯一的功能!
在介绍cache的另外一个功能之前,我要先说一下gitlab-ci的一个优点“恶心人”的特点:
它在运行下一个Job的时候,会默认把前一个Job新增的资源删除得干干静静
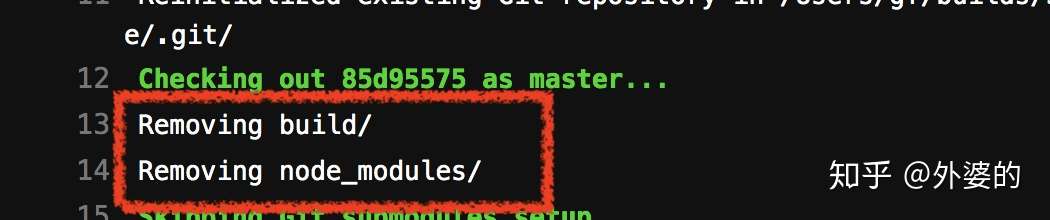
没错,也就是说,我们上面bulid阶段编译生成的包,会在deploy阶段运行前被默认删除!(我生产包都没了我怎么部署emmmmmmm)
而cache的作用就在这里体现出来了:如果我们把bulid生产的包的路径添加到cache里面,虽然gitlab还是会删除bulid目录,但是因为在删除前我们已经重新上传了cache,并且在下个Job运行时又把cache给pull下来,那么这个时候就可以实现在下一个Job里面使用前一个Job的资源了
总而言之,cache的功能体现在两点:
- 在不同pipeline之间重用资源
- 在同一pipeline的不同Job之间重用资源
虽然cache会缓存旧的包,但我们并不用担心使用到旧的资源,因为npm install还是会如期运行,并检查package.json是否有更新,npm build的时候,生成的build资源包也会覆盖cache,并且在当前Job运行结束时,作为"新的cache"上传
artifacts关键字
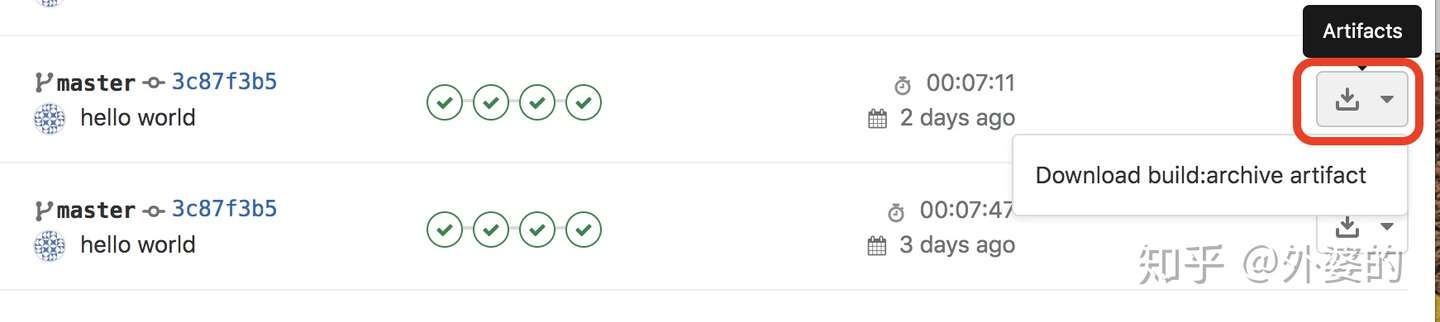
这个关键字的作用是:将生成的资源作为pipeline运行成功的附件上传,并在gitlab交互界面上提供下载
例如我们新增以下YML
Build-job:
stage: build
script:
- 'npm run build'
artifacts:
name: 'bundle'
paths:
- build/pipeline跑完后是这样的:
image/services
这两个关键字可使用Docker的镜像和服务运行Job,具体可参考Docker的相关资料,这里暂不多加叙述
only/except
这两个关键字后面跟的值是tag或者分支名的列表。
故名思义
- only的作用是指定当前Job仅仅只在某些tag或者branch上触发
- 而except的作用是当前Job不在某些tag或者branch上触发
job:
# use regexp
only:
- /^issue-.*$/
- develop
- releaseallow_failure
值为true/false, 表示当前Job是否允许允许失败。
- 默认是false,也就是如果当前Job因为报错而失败,则当前pipeline停止
- 如果是true,则即使当前Job失败,pipeline也会继续运行下去。
job1:
stage: test
script:
- execute_script_that_will_fail
allow_failure: trueretry
顾名思义,指明的是当前Job的失败重试次数的上限。
但是这个值只能在0 ~2之间,也就是重试次数最多为2次,包括第一次运行在内,Job最多自动运行3次
timeout
配置超时时间,超过时间判定为失败
Job:
script: rspec
timeout: 3h 30mWhen
表示当前Job在何种状态下运行,它可设置为3个值
- on_success: 仅当先前pipeline中的所有Job都成功(或因为已标记,被视为成功allow_failure)时才执行当前Job 。这是默认值。
- on_failure: 仅当至少一个先前阶段的Job失败时才执行当前Job。
- always: 执行当前Job,而不管先前pipeline的Job状态如何。
原文:https://zhuanlan.zhihu.com/p/184936276