主要记录一下其中写到的问题和我自己的补充解释
版本2018.5.20
斜体是原文,其他是笔记和解释
部分有点基础都知道的就不写了= =
1. 命名风格
1.1 基本就是驼峰命名,见名知意,类名和其中元素要使用全拼(方法,属性)。(局部变量没有规定,应该就是for循环中的 i 这种是可以使用的)
1.2 布尔类型不要使用is前缀,有可能会和框架冲突,因为框架很多boolean类型也用is开头(= =你是框架你说了算。。。我之前boolean貌似都是is开头。。。)
1.3 Service和DAO层实现类要用 接口名+Impl
2. 常量定义
2.1 Long a = 2L 不要用小写避免和数字1混淆
2.2 常量要按类型归类写在不同类里分开维护(作用名 + Consts)
3. 代码格式
基本就是默认代码格式- -
3.1 单行字符不超过120个,换行需要从第二行起缩进4格,括号和逗号前不换行,运算符前可以换行,a.get(name, password) 可以在点前面换行,多参数逗号后面要有空格
阿里手册里左大括号前不换行和国外不同,澳大利亚大阔号前是要换行的= =
中国:
if (a == 1) { // 小括号与里面内容之间无空格,大括号前一个空格, 运算符与变量间需要加空格, 注释与双斜线之间有一个空格。
a = 2; // 括号内容需要换行。
} else { // 大括号结束后有else不换行 (我经常换。。。需要改一下。。。)
a = 3;
}
澳大利亚: 老师说这样的好处是可以很容易根据其中一个括号的位置找到对应括号位置。
if (a == 1)
{
a = 2;
}
else
{
a = 3;
}
4. OOP(面向对象)规约
4.1. 静态变量或者方法直接使用类名引用。
静态变量或者方法都是指向共同内存,所以直接类名引用就行。比如常用的:
Integer.parseInt();或者Math里面的方法。
4.2. 所有重写必须加@Override
可以校验
4.3. 尽量不用可变参数
public List<Object> getList{}
这种。
4.4. 接口过时要使用 @Deprecated
也就是我们平时开发常见的被横斜划掉的那些类。。。java自带的很多还能用,不过平时开发自己写的要表明提醒其他人= =
4.5.equals要用确定有值的变量或者常量来调用,避免空指针异常
要用: "1".equals(a);
而不是:a.equals("1");
= =这个有点毁我三观。。。
4.6 所有包装类对象之间的比较全部使用equals
这个挺重要的,原文解释:
说明:对于Integer var = ? 在-128至127范围内的赋值,Integer对象是在IntegerCache.cache产生,会复用已有对象,这个区间内的Integer值可以直接使用==进行判断,但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象,这是一个大坑,推荐使用equals方法进行判断。
虽说包装类本质就已经是引用对象了貌似都应该用equals。。。
4.7 局部变量使用基本类型(int,char,boolean这类小写的), 类属性,参数,返回值等要用包装类型(Integer,Character,Boolean这类大写的)
使用基本类如果赋值失败(比如数据库中没有查到数据),会给与默认值(int 是 0), 而包装类会返回null或者报异常(基本类型是没有空值的。。。char c = ''; 会报错, Character c = ''; 不会)。

4.8 定义类时尽量不要给属性加默认值
4.9 序列化类新增属性时,不要修改 serialVersionUID
避免不一致抛出异常
4.10 构造方法中不要加业务逻辑
比如
Account(String name, String password){
this.name = name + "_aaa"; //这种应该加在init中
}
4.11 POJO类(简单的Java对象,只有属性(构造方法,get,set 这类方法,专门用来储存对象的类))必须写toString
可以在异常时或者调试时打印其内容
4.12 【推荐】使用索引访问用String的split方法得到的数组时,需做最后一个分隔符后有无内容的检查,否则会有抛IndexOutOfBoundsException的风险。
说明:
String str = "a,b,c,,";
String[] ary = str.split(",");
// 预期大于3,结果是3
System.out.println(ary.length);
4.13 类中方法的顺序
公有 > 私有 > get,set
同名方法(方法重载)写在一起(优先级高于上一条)。 (重载:同一个类中方法同名不同参数。 重写:子类override父类方法)。
4.14 循环体内字符串连接用StringBuilder.append
java源码中String a = a + "b";
本质就是调用了StringBuilder.append 然后toString转回String, 循环体内多次拼接用Stringbuilder可以使编译时避免多次new StringBuilder,更加节省内存资源。
4.15 慎用clone来拷贝对象
因为clone是浅拷贝,如果需要使用需要重写clone方法。
如果直接继承Object的clone方法,因为是浅拷贝,如果Class B 中有个属性是 ClassA classA(包含关系), 那么B.clone 返回值的classA属性地址会直接赋值给clone的出来的新对象,两个ClassB中的classA会指向同一个地址,一个改全都改(类似static)
4.16 类方法与成员控制从严
简单点说就是: private > protected > default > public 能不让别人用就尽量别给权限。 工具类不要有public或者default构造方法 (比如Math这种= =)
5 集合
5.1 Set和Map的存储都是用equals判断是否相同的,equals则采用了对比hashcode。
所以使用Map和Set存储对象时,需要重写hashCode和equals方法。
5.2 ArrayList的subList需要注意使用
ArrayList的subList并不是截取后复制了一份新的ArrayList,而是SubList,他只是ArrayList的一个视图(对其操作其实操作的是原ArrayList)。
5.3 在subList场景中,高度注意对原集合元素的增加或删除,均会导致子列表的遍历、增加、删除产生ConcurrentModificationException 异常。
这个是和上一条有关系的,因为ArrayList和subList都有一个参数叫modCount,记录了这个集合修改的次数,
关于这个参数,注释如下
/**
* The number of times this list has been <i>structurally modified</i>.Structural modifications are those that change the size of the list, * or otherwise perturb it in such a fashion that iterations in progress may yield incorrect results. * * <p>This field is used by the iterator and list iterator implementation returned by the {@code iterator} and {@code listIterator} methods. * If the value of this field changes unexpectedly, the iterator (or list iterator) will throw a {@code ConcurrentModificationException} in * response to the {@code next}, {@code remove}, {@code previous}, {@code set} or {@code add} operations. This provides * <i>fail-fast</i> behavior, rather than non-deterministic behavior in the face of concurrent modification during iteration. * * <p><b>Use of this field by subclasses is optional.</b> If a subclass wishes to provide fail-fast iterators (and list iterators), then it * merely has to increment this field in its {@code add(int, E)} and {@code remove(int)} methods (and any other methods that it overrides * that result in structural modifications to the list). A single call to {@code add(int, E)} or {@code remove(int)} must add no more than * one to this field, or the iterators (and list iterators) will throw bogus {@code ConcurrentModificationExceptions}. If an implementation * does not wish to provide fail-fast iterators, this field may be ignored. */说明:使用toArray带参方法,入参分配的数组空间不够大时,toArray方法内部将重新分配内存空间,并返回新数组地址;如果数组元素个数大于实际所需,下标为[ list.size() ]的数组元素将被置为null,其它数组元素保持原值,因此最好将方法入参数组大小定义与集合元素个数一致。 正例:
List<String> list = new ArrayList<String>(2);
list.add("guan");
list.add("bao");
String[] array = new String[list.size()];
array = list.toArray(array);
反例:直接使用toArray无参方法存在问题,此方法返回值只能是Object[]类,若强转其它类型数组将出现ClassCastException错误。
5.5 使用工具类Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法,它的add/remove/clear方法会抛出UnsupportedOperationException异常。 说明:asList的返回对象是一个Arrays内部类,并没有实现集合的修改方法。Arrays.asList体现的是适配器模式,只是转换接口,后台的数据仍是数组。 String[] str = new String[] { "you", "wu" }; List list = Arrays.asList(str); 第一种情况:list.add("yangguanbao"); 运行时异常。 第二种情况:str[0] = "gujin"; 那么list.get(0)也会随之修改。
5.6 泛型通配符<? extends T>来接收返回的数据,此写法的泛型集合不能使用add方法,而<? super T>不能使用get方法,作为接口调用赋值时易出错。 说明:扩展说一下PECS(Producer Extends Consumer Super)原则:第一、频繁往外读取内容的,适合用<? extends T>。第二、经常往里插入的,适合用<? super T>。
这里说一下<? extends T>和<? super T>
平时我们常见的泛型应该是<T>,方法的返回类型<T>后,可以避免强制转换,在方法中直接操作该类型。而<? extends T>则是表示 T 和它的子类,<? super T>表示<T>和它的父类。
不难理解,由于有多态的存在,父类 father = new 子类(); 是可行的,子类可以强制转化为父类,父类不能强转为子类。因为如果一个<? extends T>(子类向下, T和T的子类)集合使用add添加父类,无法把添加的父类统一成子类,就会报错。同理,一个<? super T>(父类向上,T和T的父类)的集合,取出一个元素由子类接收,也无法把取出的父类转化为子类,也会报错。
测试:
ClassA 是 ClassB 的父类
ClassC 是 ClassB 的子类
报错信息如下。

5.7 不要在foreach循环里进行元素的remove/add操作。remove元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁。
正例:
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if (删除元素的条件) {
iterator.remove();
}
}
反例:
for (String item : list) {
if ("1".equals(item)) { //为1是不报错,2的时候抛出异常ConcurrentModificationException,就是5.3 讲到的那个= =
list.remove(item);
}
}
区别主要是一个用list.remove(),一个用Iterator.remove。
另外foreach的底层其实就是Iterator。。。
网上看到有人说是因为modCount,但是那样解释不了为什么1不会报错。。。
我看了看源码。。。发现貌似是因为数组越界?
public void remove() {
if (this.lastRet < 0) {
throw new IllegalStateException();
} else {
this.checkForComodification();
try {
AbstractList.this.remove(this.lastRet);
if (this.lastRet < this.cursor) {
--this.cursor;
}
this.lastRet = -1;
this.expectedModCount = AbstractList.this.modCount;
} catch (IndexOutOfBoundsException var2) {
throw new ConcurrentModificationException();
}
}
}
其实就是遍历的时候删了一个,后面的前移导致实际长度和遍历前不一样到导致了数组越界,但是报错这里抓取的是数组越界,报的错是集合被修改,所以有些人就想当然的以为和5.3那个是一个问题。。。
5.8 在JDK7版本及以上,Comparator实现类要满足如下三个条件,不然Arrays.sort,Collections.sort会报IllegalArgumentException异常。 说明:三个条件如下 1) x,y的比较结果和y,x的比较结果相反。 2) x>y,y>z,则x>z。 3) x=y,则x,z比较结果和y,z比较结果相同。 反例:下例中没有处理相等的情况,实际使用中可能会出现异常:
new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getId() > o2.getId() ? 1 : -1;
}
};
5.9 集合初始化时,指定集合初始值大小。 说明:HashMap使用HashMap(int initialCapacity) 初始化。 正例:initialCapacity (需要存储的元素个数 / 负载因子) + 1。 注意 负载因子(即loader factor 默认为 0.75,如果 暂时无法 确定 初始值大小,请设置为 16(即默认值)。 反例: HashMap需要 放置 1024个 元素, 由于 没有设置容量 初 始大小,随着元素不断增加,容
量 7 次 被迫扩大, resize需要重建 hash表,严重影响性能。
这个根据实际情况= =如果个数很少救不用预设initialCapacity了
5.10 使用entrySet遍历Map类集合KV,而不是keySet方式进行遍历。 说明:keySet其实是遍历了2次,一次是转为Iterator对象,另一次是从hashMap中取出key所对应的value。而entrySet只是遍历了一次就把key和value都放到了entry中,效率更高。如果是JDK8,使用Map.foreach方法。 正例:values()返回的是V值集合,是一个list集合对象;keySet()返回的是K值集合,是一个Set集合对象;entrySet()返回的是K-V值组合集合。
5.11
高度注意Map类集合K/V能不能存储null值的情况,如下表格:
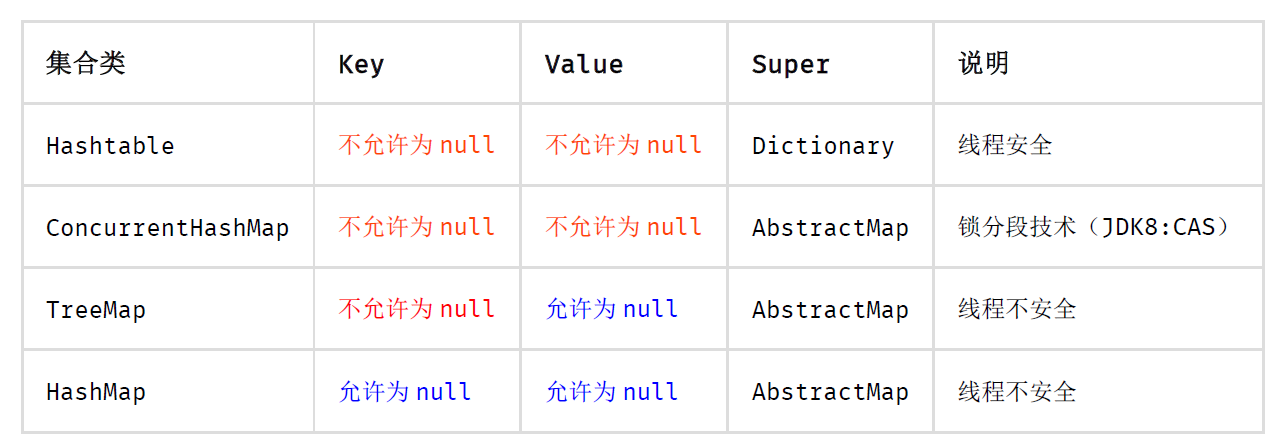
反例: 由于HashMap的干扰,很多人认为ConcurrentHashMap是可以置入null值,而事实上,存储null值时会抛出NPE异常。
注意hashtable的线程安全。。。经常会问