入门学习了Linux的系统编程和网路编程,应该写一个小项目来练练手啦。这里模仿的是Github上一个开源项目:TinyWebServer。
项目地址:https://github.com/qinguoyi/TinyWebServer
非常感谢社长(TinyWebServer项目owner)的项目,项目代码量不算多,但是麻雀虽小五脏俱全,是一个非常好的把学过的各个知识点串在一起的小项目!!这里想讲一下实现过程以及其中的一些坑和收获(我学习的是项目的raw version)。这篇(上)就先讲项目最最最重要那些功能。阅读本文或者说要完全理解这个项目需要有Linux系统编程基础和网络编程基础,以及对计算机网路和http有一定了解。
博主水平十分有限(不是谦虚呀qaq),文章很可能有遗漏/错误,请大家也自行思考,欢迎指出讨论。
(更新中~~~~~)
概括
项目分成Main模块,epoll模块,http模块,lock模块,threadpool模块,log模块,timer模块,mysql模块。先简单讲一下各个模块的功能。main模块就是服务器主函数,主要是负责把各个模块组合协调工作。epoll模块是写epoll相关的函数。http模块是最关键的,提供处理http请求以及处理后返回http响应的所有函数。后面的lock就是提供同步工具(互斥锁/条件锁/信号量),threadpool当然就是线程池提供工作线程来处理http请求,log日记模块,mysql数据库模块提供数据库服务,timer定时器模块主要任务是负责定时清理长时间无反应的连接。
main模块
首先由main开始,主函数要协调各个模块进行工作,主要任务就是调用epoll函数监听各种事件并对事件调用相应的处理模块,接下啦详细讲一下:
在开始监听之前我们先创建listenfd并用epoll对其监听,然后我们开始正式工作,不断while知道WebServer停止服务,在while中我们调用epoll_wait函数得到所有有反应的事件,我们对这些事件分成几类来进行处理(根据事件的sockfd来判断):
①新连接请求,判断条件是sockfd == listenfd,那么没什么好说的我们accept接受请求就是了,并且保存好用户连接数据(ip,端口,connfd等),然后就把connfd挂到eoll上监听它的读事件。
②对端关闭,判断条件是EPOLLRDHUP | EPOLLHUP | EPOLLERR,那么我们这边也关闭该连接相关资源。
③读事件且是信号事件,判断条件是(sockfd==pipefd[0]) && (whatopt & EPOLLIN),这里为什么信号会当成epoll的读事件?是因为统一了信号源,在信号的回调函数想管道里写东西,然后epoll监听管道,所以会监听到读事件,这里也许需要配合信号模块的讲解才容易理解。
④读事件且是客户端发送请求报文,判断条件是EPOLLIN,那么这里是读又不是信号,那么就是客户端的请求报文啦,那么我们把这次的读数据全部读到我们提前为该客户的准备的读数据缓冲区,然后我们把一个任务插入到线程池的任务队列中。于是我们就不用管了,工作线程自然会处理。
⑤写事件,判断条件是EPOLLOUT。WebServer只用一种写事件就是我们的工作线程做好了请求报文的处理,并且已经搓好了响应报文放在了客户的写数据缓冲区中,那么我们的任务就是调用函数把响应报文发送给浏览器。
这里直接讲main函数,可以看到整个服务器是怎么工作的,当然也有可能还没有接触到响应的各个模块所以有些懵逼,但是这里先有个大概流程了解后面了解清除所有模块工作之后回来会更加清晰。


1 while (!stop_server) 2 { 3 int total = epoll_wait(epollfd,events,MAX_EVENT_NUMBER,-1); 4 if (total < 0 && errno != EINTR) { 5 //把错误记录到日志 6 break; 7 } 8 9 for (int i = 0; i < total; i++) { 10 int sockfd = events[i].data.fd; 11 int whatopt = events[i].events; 12 13 //有新连接请求事件 14 if (sockfd == listenfd) { 15 struct sockaddr_in client_address; 16 socklen_t client_address_len = sizeof(client_address); 17 18 //LT 19 int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_address_len); 20 if (connfd < 0) { 21 //accept错误 22 continue; 23 } 24 if (http_conn::m_user_count >= MAX_FD) { 25 //用户数量超过最大描述符了 26 continue; 27 } 28 29 in_addr client_ip; 30 memcpy(&client_ip, &client_address.sin_addr.s_addr, 4); 31 printf("ip:%s connect ", inet_ntoa(client_ip) ); 32 33 // 初始化新客户,并在这里面把课后挂到epoll监听树上 34 users[connfd].init(connfd, client_address); 35 36 //创造timer和client_data 37 user_timer[connfd].address = client_address; 38 user_timer[connfd].sockfd = connfd; 39 40 util_timer* timer = new util_timer; 41 timer->user_data = &user_timer[connfd]; 42 timer->cb_func = cb_func; 43 timer->expire = time(NULL) + 6 * TIMESLOT; 44 45 user_timer[connfd].timer = timer; 46 //上面创造好了timer,加入到链表中 47 timer_lst.add_timer(timer); 48 } 49 //对端关闭连接事件(EPOLLRDHUP | EPOLLHUP 这两个是关闭) 50 else if (whatopt & (EPOLLRDHUP | EPOLLHUP | EPOLLERR)) { 51 //对端关闭了,我们这边也关闭然后取消定时器 52 util_timer* timer = user_timer[sockfd].timer; 53 timer->cb_func(&user_timer[sockfd]); 54 if (timer) timer_lst.del_timer(timer); 55 } 56 //因为统一了事件源,信号处理当成读事件来处理 57 //怎么统一?就是信号回调函数哪里不立即处理而是写到:pipe的写端 58 else if ((sockfd==pipefd[0]) && (whatopt & EPOLLIN)) { 59 int sig; 60 char signals[1024]; 61 int ret = recv(pipefd[0], signals, sizeof(signals), 0); 62 if (ret == -1) continue; 63 if (ret == 0) continue; 64 //在这里处理信号 65 for (int i = 0; i < ret; i++) { 66 switch (signals[i]) 67 { 68 case SIGALRM: 69 timeout = true; 70 break; 71 case SIGTERM: 72 stop_server = true; 73 default: 74 break; 75 } 76 } 77 } 78 /*输入事件,理想步骤是: 79 process->porcess_read(不断parse_line->parse_status_line/parse_headers/parse_content 80 ->do_request)->process_write(add_line/heads/content...) 81 ->把报文搓到输出缓冲区 82 */ 83 else if (whatopt & EPOLLIN) { 84 //开始处理这个浏览器请求 85 util_timer* timer = user_timer[sockfd].timer; 86 if (users[sockfd].read_once()) { //1,把所有数据读进来 87 pool->append(users + sockfd); //2,读完之后把往线程池任务队列放入一个任务,这里process函数最后会添加监听写时间 88 89 //因为有了新请求,所以把这个客户的不活跃事件延后 90 //延后时间之后做出位置调整 91 if (timer) { 92 timer->expire = time(NULL) + 6 * TIMESLOT; 93 timer_lst.adjust_timer(timer); 94 } 95 } 96 //read_once()失败,关闭连接吧 97 else { 98 timer->cb_func(&user_timer[sockfd]); 99 if (timer) timer_lst.del_timer(timer); 100 } 101 } 102 //输出事件 103 else if (whatopt & EPOLLOUT) { 104 util_timer* timer = user_timer[sockfd].timer; 105 //在上面读事件已经搓好响应报文就等这里write把输出缓冲区发送给浏览器 106 if (users[sockfd].write()) { //write函数最后会重新监听读事件 107 //跟读事件一样,延后这个客户的不活跃事件 108 if (timer) { 109 timer->expire = time(NULL) + 6 * TIMESLOT; 110 timer_lst.adjust_timer(timer); 111 } 112 } 113 else { //这里的话就是write发送给浏览器失败,关闭连接 114 timer->cb_func(&user_timer[sockfd]); 115 if (timer) timer_lst.del_timer(timer); 116 } 117 } 118 } 119 120 if (timeout) { 121 timer_handler(); 122 printf("Now %d clients connect ", http_conn::m_user_count); 123 timeout = false; 124 } 125 }
epoll模块
epoll模块就是和epoll相关的我们需要的函数在这里定义,这里比较简答就不细讲了,看代码注释肯定能懂。
1 int epoll_myinit() { 2 int epollfd = epoll_create(5); 3 assert(epollfd != -1); 4 return epollfd; 5 } 6 7 //把文件描述符fd设为非阻塞 8 int setnoblocking(int fd) { 9 int old_option = fcntl(fd, F_GETFL); 10 int new_option = old_option | O_NONBLOCK; 11 fcntl(fd, F_SETFL, new_option); 12 return old_option; 13 } 14 15 //把fd添加到监听红黑树epollfd上 16 void addfd(int epollfd, int fd, bool oneshot) { 17 epoll_event event; 18 event.data.fd = fd; 19 20 event.events = EPOLLIN | EPOLLRDHUP; //读事件 21 //EPOLLRDHUP 表示读关闭。 22 //1 对端发送 FIN (对端调用close 或者 shutdown(SHUT_WR)). 23 //2 本端调用 shutdown(SHUT_RD). 当然,关闭 SHUT_RD 的场景很少。 24 25 if (oneshot) 26 event.events |= EPOLLONESHOT; 27 /*eppll 即使使用ET模式,一个socket上的某个事件还是可能被触发多次,采用线程城池的方式来处理事件,可能一个socket同时被多个线程处理 28 如果对描述符socket注册了EPOLLONESHOT事件,那么操作系统最多触发其上注册的一个可读、可写或者异常事件,且只触发一次。。想要下次再触发则必须使用epoll_ctl重置该描述符上注册的事件,包括EPOLLONESHOT 事件。 29 EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里 30 */ 31 32 epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); 33 setnoblocking(fd); //设置为非阻塞,如果ET是必须的 34 } 35 //把fd从监听红黑树epollfd上摘下来 36 void removefd(int epollfd, int fd) { 37 epoll_ctl(epollfd, EPOLL_CTL_DEL, fd,0); 38 close(fd); 39 } 40 //将事件重置为EPOLLONESHOT 41 void modfd(int epollfd, int fd, int ev) { 42 epoll_event event; 43 event.data.fd = fd; 44 //LT 45 event.events = ev | EPOLLONESHOT | EPOLLRDHUP; 46 epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event); 47 }
locker模块
locker模块包装了一些我们做线程同步的工具类,具体有:信号量类,互斥锁,条件变量类。没有什么太特别的,就是把这些工具函数将他们的错误处理包装起来方便使用。
1 #ifndef LOCKER_H 2 #define LOCKER_H 3 4 #include<exception> 5 #include<pthread.h> 6 #include<semaphore.h> 7 8 //一个简单的信号量类 9 class sem 10 { 11 public: 12 sem() { 13 if (sem_init(&m_sem, 0, 0) != 0) 14 throw std::exception(); 15 } 16 sem(int num) { 17 if (sem_init(&m_sem, 0, num) != 0) 18 throw std::exception(); 19 } 20 ~sem() { 21 sem_destroy(&m_sem); 22 } 23 24 //加锁与解锁 25 bool wait() { 26 return sem_wait(&m_sem) == 0; 27 } 28 bool post() { 29 return sem_post(&m_sem) == 0; 30 } 31 32 private: 33 sem_t m_sem; 34 }; 35 36 37 //简单的互斥锁 38 class locker 39 { 40 public: 41 locker() { 42 if (pthread_mutex_init(&m_mutex,NULL) != 0) 43 throw std::exception(); 44 } 45 ~locker() { 46 pthread_mutex_destroy(&m_mutex); 47 } 48 49 bool lock() { 50 return pthread_mutex_lock(&m_mutex) == 0; 51 } 52 bool unlock() { 53 return pthread_mutex_unlock(&m_mutex) == 0; 54 } 55 pthread_mutex_t* get() { 56 return &m_mutex; 57 } 58 59 private: 60 pthread_mutex_t m_mutex; 61 }; 62 63 64 //简单的条件变量 65 class cond 66 { 67 public: 68 cond() { 69 if (pthread_cond_init(&m_cond, NULL) != 0) 70 throw std::exception(); 71 } 72 ~cond() { 73 pthread_cond_destroy(&m_cond); 74 } 75 76 //设置条件变量 77 bool wait(pthread_mutex_t* m_mutex) { 78 return pthread_cond_wait(&m_cond, m_mutex); 79 } 80 bool timewait(pthread_mutex_t* m_mutex, struct timespec t) { 81 return pthread_cond_timedwait(&m_cond, m_mutex, &t)==0; 82 } 83 //条件变量满足,唤醒阻塞在m_mutex互斥量的线程 84 bool signal() { 85 return pthread_cond_signal(&m_cond) == 0; 86 } 87 bool broadcast() { 88 return pthread_cond_broadcast(&m_cond) == 0; 89 } 90 91 private: 92 pthread_cond_t m_cond; 93 }; 94 95 #endif // !LOCKER_H
threadpool模块
一个web服务器几乎离不开多线程了,在main那里我们说到main把所有读时间能读到的数据都存放在客户读缓冲区中,然后就插入任务到任务队列等待线程去完成。我们来仔细讲一下:
线程池类有两个最为关键的成员:
pthread_t* m_threads; //线程池数组
std::list<T*> m_workqueue; //请求队列
什么是请求队列,就是一个存储任务的list,我们在main函数把新任务放到list的尾部,然后所有线程争夺list中的任务(这里要使用条件变量),争夺到的线程先对任务队列加互斥锁然后从list头取出任务结构体,在这个任务结构体内有一个回调函数,这个函数就是真正的工作(包括解析http请求报文,对请求资源的检查,搓响应报文一条龙)当然这个函数我们放在http模块以更加模块化,从线程的角度就是我们拿到任务然后调用这个函数,线程就是在漫长的这个函数中度过了。
然后是线程池数组,这个线程池还是比较简单的线程池(没有对线程的动态删减等等),那么我们就是在线程池构造的时候就创建好约定个数的线程储存在线程数组里,并且把线程detach掉,这样我们就不需要对线程进行回收等等操作。线程的关键是线程的工作函数run(),这个函数不断while循环直到被条件变量唤醒然后上锁从list尾取出任务,开始执行任务(函数是porcess,看下个模块)
1 #ifndef THREADPOOL_H 2 #define THREADPOOL_H 3 4 #include<cstdio> 5 #include<pthread.h> 6 #include<exception> 7 #include<list> 8 9 #include "../lock/locker.h" 10 #include"../CGImysql/sql_connection_pool.h" 11 12 template<typename T> 13 class threadpool 14 { 15 public: 16 /*thread_number是线程池中线程的数量,max_requests是请求队列中最多允许的、等待处理的请求的数量*/ 17 threadpool(connection_pool* connPool, int thread_number = 8, int max_request = 10000); 18 ~threadpool(); 19 bool append(T* request); 20 21 private: 22 /*工作线程运行的函数,它不断从工作队列中取出任务并执行之*/ 23 static void* worker(void* arg); 24 void run(); 25 26 private: 27 int m_thread_number; //线程池线程数 28 int m_max_requests; //请求队列的最大请求数 29 30 pthread_t* m_threads; //线程池 数组 31 std::list<T*> m_workqueue; //请求 队列 32 33 locker m_queuelocker; //请求队列的互斥锁 34 sem m_queuestat; //请求队列的信号量(可以看出要处理的任务数) 35 36 bool m_stop; //线程池结束标志 37 connection_pool* m_connPool; //数据库连接池 38 }; 39 40 //线程池构造函数 41 template<typename T> 42 threadpool<T>::threadpool(connection_pool* connPool, int thread_number, int max_request) : 43 m_thread_number(thread_number), m_max_requests(max_request), m_stop(false), m_threads(NULL), m_connPool(connPool) { 44 if (thread_number <= 0 || max_request <= 0) //不合理的线程数量和请求队列数量 45 throw std::exception(); 46 m_threads = new pthread_t[m_thread_number]; 47 if (!m_threads) 48 throw std::exception(); 49 //创造thread_number个线程并且存储起来 50 for (int i = 0; i < thread_number; i++) { 51 if (pthread_create(m_threads + i, NULL, worker, this) != 0) { 52 delete[] m_threads; //失败 53 throw std::exception(); 54 } 55 if (pthread_detach(m_threads[i])) { 56 delete[] m_threads; //失败 57 throw std::exception(); 58 } 59 } 60 } 61 62 //线程池析构函数 63 template<typename T> 64 threadpool<T>::~threadpool() { 65 delete[] m_threads; 66 m_stop = true; 67 } 68 69 //将“待办工作”加入到请求队列 70 template<typename T> 71 bool threadpool<T>::append(T *request) { 72 m_queuelocker.lock(); 73 if (m_workqueue.size() > m_max_requests) { 74 m_queuelocker.unlock(); 75 return false; 76 } 77 m_workqueue.push_back(request); 78 m_queuelocker.unlock(); 79 m_queuestat.post(); 80 return true; 81 } 82 83 //线程回调函数/工作函数,arg其实是this 84 template<typename T> 85 void* threadpool<T>::worker(void *arg) { 86 threadpool* pool = (threadpool*)arg; 87 pool->run(); 88 return pool; 89 } 90 91 //回调函数会调用这个函数工作 92 //工作线程就是不断地等任务队列有新任务,然后就加锁取任务->取到任务解锁->执行任务 93 template<typename T> 94 void threadpool<T>::run() { 95 while (!m_stop) { 96 //请求队列长度--,互斥锁锁住 97 m_queuestat.wait(); 98 m_queuelocker.lock(); 99 100 if (m_workqueue.empty()) { 101 m_queuelocker.unlock(); 102 continue; 103 } 104 105 T* request = m_workqueue.front(); 106 m_workqueue.pop_front(); 107 108 m_queuelocker.unlock(); 109 110 if (!request) continue; 111 112 // 113 connectionRAII mysqlcon(&request->mysql, m_connPool); 114 115 request->process(); 116 } 117 } 118 119 120 #endif // THREADPOOL_H
线程池的数量是不是越多服务器的性能越高呢?其实不是这样的,简单来说线程数量和计算机的CPU核心数成一定关系时,表现会较好。从网上找到一个回答(出处不详

http模块
好的到了这里我们终于到了最关键的http模块了,在http模块我们将完成最关键的处理http请求报文和搓http响应报文的工作。如果一个个函数细细讲这一块可以讲很久很久。。。
我们先看看主要函数以及它们的协调合作:

我们先理解这一块使用到的“状态机设计模式”,我们学过UML里的状态图,那么我们应该很容易理解这个设计模式。简单理解就是,我们经常会遇到需要根据不同的情况作出不同的处理的情况,这时候我们写出大量的if else使得逻辑十分混乱。那么我们可以这样设计:我们在类里面设计一个状态,并且允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。感觉说起来还是比较抽象,看代码会比较容易理解,其实就是看状态调用不同的函数。
在http中我们如何使用状态机,我们有两个状态机:主状态机和从状态机。
//主状态机的状态:解析请求行 解析请求头 解析消息体(仅用于解析POST请求)
enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT };
//报文解析的结果:请求不完整需要继续读取请求报文数据 获得了完整的HTTP请求 HTTP请求报文有语法错误 服务器内部错误,该结果在主状态机逻辑switch的default下,一般不会触发
enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE, FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };
//从状态机的状态:完整读取一行 报文语法有误 读取的行不完整
enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN };
这一部分知识强烈建议看一下社长公众号系列文章,我们需要重点理解主状态机和从状态机,我的个人理解是主状态机是更为宏观一点的他主要关注当前解析到 请求行 / 请求头 / 请求主体 ?那么我们的代码就要根据这个主状态机的状态判断当前的解析进度从而判断当前进度下一步要做的动作(举个例子:比如我现在是请求头状态并且也发现现在已经把最后一行请求头解析完了,那么我们就变换主状态机状态,这时下一次代码就能判断到当前解析到请求主体了所以调用相关的函数)。
那么从状态机又怎么理解呢?从状态机就是更加聚焦于一行行,着眼更加细致,他关心的是当前这一行读完整了/不完整/格式有误,亦即从状态机关注一行的解析状态。(那么显然这里可以想到其实每一个主状态机状态可能对应多轮的从状态改变,类似与包含关系),所以从状态机的函数会关注当前字符是什么,根据这个字符判断当前是读完了吗是格式错误吗等等。
我们从状态机的角度看看这个函数调用:
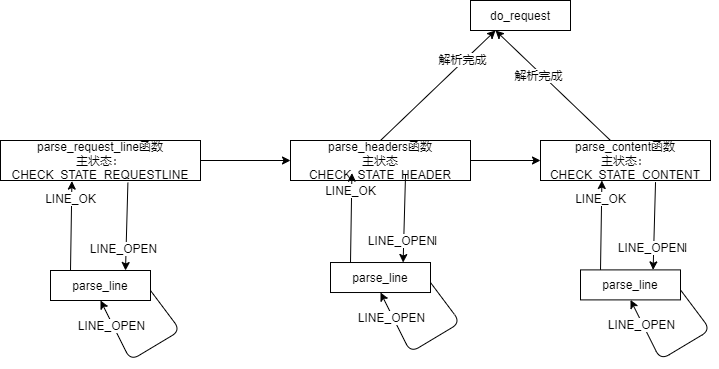
http模块就讲到这里了,具体每个函数实现还是得认真看代码,有很多很多细节值得学习,这里怕是讲不完。
OK到这里我们就讲了TinyWebServer的前五个模块了,写成这样其实webserver已经能够基础工作了,监听/请求/响应都可以完成了。后面我们要对这个服务器增加更多的模块,使得他的性能上升和提供更多的功能。
参考资料:
TinyWebServer项目地址:https://github.com/qinguoyi/TinyWebServer