Moving Data
Objectives
After completing this lesson, you should be able to:
• Describe ways to move data
• Explain the general architecture of Oracle Data Pump
• Create and use directory objects
• Use Data Pump Export and Import to move data between Oracle databases
• Use SQL*Loader to load data from a non-Oracle database (or user files)
• Use external tables to move data via platform-independent files
目标
完成本课程后,您应该能够:
•描述移动数据的方法
•解释Oracle数据泵的总体架构
•创建和使用目录对象
•使用数据泵导出和导入在Oracle数据库之间移动数据
•使用SQL*加载程序从非Oracle数据库(或用户文件)加载数据
•使用外部表通过独立于平台的文件移动数据
Moving Data: General Architecture 移动数据:通用体系结构

Oracle Data Pump: Overview
As a server-based facility for high-speed data and metadata movement, Oracle Data Pump:
• Is callable via DBMS_DATAPUMP
• Provides the following tools:
– expdp
– impdp
– GUI interface in Enterprise Manager Cloud Control
• Provides four data movement methods:
– Data file copying
– Direct path
– External tables
– Network link support
• Detaches from and re-attaches to long-running jobs
• Restarts Data Pump jobs
Oracle数据泵:概述
作为基于服务器的高速数据和元数据移动工具,Oracle data Pump:
•可通过DBMS U数据泵调用
•提供以下工具:
–出口产品开发计划
–impdp公司
–Enterprise Manager云控制中的图形用户界面
•提供四种数据移动方法:
–数据文件复制
–直接路径
–外部表格
–网络链接支持
•脱离并重新连接到长时间运行的作业
•重新启动数据泵作业
Oracle Data Pump: Benefits
Data Pump offers many benefits and many features, such as:
• Fine-grained object and data selection
• Explicit specification of database version
• Parallel execution
• Estimation of export job space consumption
• Network mode in a distributed environment
• Remapping capabilities
• Data sampling and metadata compression
• Compression of data during a Data Pump export
• Security through encryption
• Ability to export XMLType data as CLOBs
• Legacy mode to support old import and export files
Oracle数据泵:好处
数据泵提供许多优点和功能,例如:
•细粒度对象和数据选择
•明确说明数据库版本
•并行执行
•估算出口工作空间消耗
•分布式环境中的网络模式
•重新映射功能
•数据采样和元数据压缩
•数据泵导出期间的数据压缩
•通过加密实现安全性
•能够将XMLType数据导出为clob
•支持旧导入和导出文件的传统模式
Directory Objects for Data Pump 数据泵的目录对象
Creating Directory Objects 创建目录对象
SQL> create directory exp_dump as '/u01/'; 创建目录
Directory created.
Data Pump Export and Import Clients: Overview 数据泵导出和导入客户端:概述 (可通过此方式完成数据库升级操作,比如从11g升级到12c)
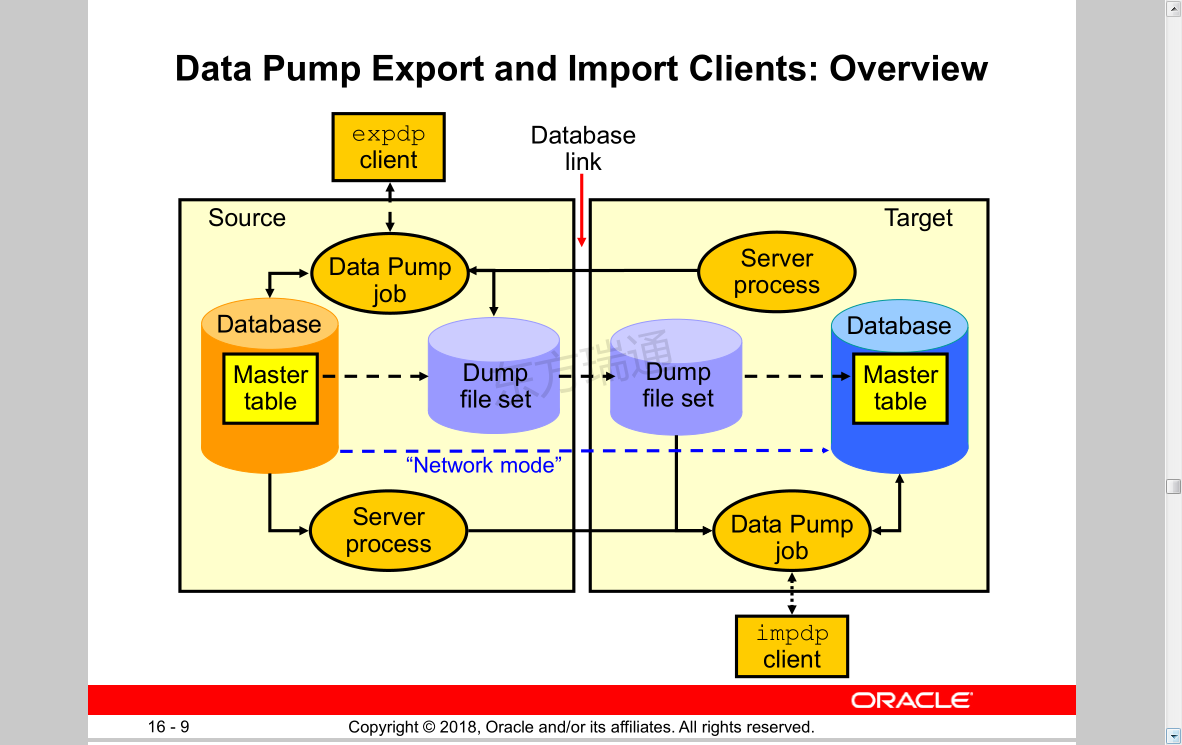
Data Pump Utility: Interfaces and Modes
• Data Pump Export and Import interfaces:
– Command line
– Parameter file
– Interactive command line
– Enterprise Manager Cloud Control
• Data Pump Export and Import modes:
– Full
– Schema
– Table
– Tablespace
– Transportable tablespace
– Transportable database
数据泵实用程序:接口和模式
•数据泵导出和导入接口:
–命令行
–参数文件
–交互式命令行
–Enterprise Manager云控制
•数据泵导出和导入模式:
–已满
–架构
–桌子
–表空间
–可传输表空间
–可移植数据库
Performing a Data Pump Export by Using Enterprise Manager Cloud Control 使用Enterprise Manager云控制执行数据泵导出 (可用schema方式导出)
SQL> select * from job_history; 查看表是否存在
[oracle@yf u01]$ expdp system directory=exp_dump dumpfile=exp_hr.dmp logfile=hr_exp.log schemas=hr
[oracle@yf u01]$ expdp数据库导出导入工具 system用户名 directory目录对象=exp_dump刚才创建的目录对象 dumpfile=exp_hr.dmp指定dmp文件的名称 logfile=hr_exp.log指定日志文件名称 schemas=hr指定导出的方式和名称
Export: Release 18.0.0.0.0 - Production on Sat Jun 27 21:24:03 2020
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Password: 输入用户口令
[oracle@yf u01]$ cd /u01
[oracle@yf u01]$ ls *.log
hr_exp.log
[oracle@yf u01]$ more hr_exp.log 查看新生成的log文件
[oracle@yf u01]$ ls *.dmp
[oracle@yf u01]$ sqlplus hr/hr
SQL> drop table job_history purge; 模拟表被误删除
Table dropped.
SQL> select * from job_history;
select * from job_history 表已经不在了
*
ERROR at line 1:
ORA-00942: table or view does not exist
[oracle@yf ~]$ impdp system directory=exp_dump dumpfile=exp_hr.dmp logfile=imp_hr.log tables=hr.job_history
[oracle@yf ~]$ impdp导入工具 system用户名 directory=exp_dump目录对象名称 dumpfile=exp_hr.dmp文件名 logfile=imp_hr.log日志文件名 tables=hr.job_history需要导入的表
Import: Release 18.0.0.0.0 - Production on Sat Jun 27 21:53:26 2020
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Password:
Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production
Master table "SYSTEM"."SYS_IMPORT_TABLE_01" successfully loaded/unloaded
Starting "SYSTEM"."SYS_IMPORT_TABLE_01": system/******** directory=exp_dump dumpfile=exp_hr.dmp logfile=imp_hr.log tables=hr.job_history
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
. . imported "HR"."JOB_HISTORY" 7.187 KB 10 rows 导入成功
Processing object type SCHEMA_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type SCHEMA_EXPORT/TABLE/COMMENT
Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "SYSTEM"."SYS_IMPORT_TABLE_01" successfully completed at Sat Jun 27 21:53:54 2020 elapsed 0 00:00:22
Performing a Data Pump Import
Data Pump can be invoked on the command line:
执行数据泵导入
可以在命令行上调用数据泵:
$ impdp hr DIRECTORY=DATA_PUMP_DIR
DUMPFILE=HR_SCHEMA.DMP
PARALLEL=1
CONTENT=ALL
TABLES="EMPLOYEES"
LOGFILE=DATA_PUMP_DIR:import_hr_employees.log
JOB_NAME=importHR
TRANSFORM=STORAGE:n
Data Pump Import: Transformations
You can remap:
• Data files by using REMAP_DATAFILE
• Tablespaces by using REMAP_TABLESPACE
• Schemas by using REMAP_SCHEMA
• Tables by using REMAP_TABLE
• Data by using REMAP_DATA
数据泵导入:转换
您可以重新映射:
•使用REMAP_DATAFILE的数据文件
•使用REMAP_表空间的表空间
•使用重新映射模式的模式
•使用REMAP_TABLE的表
•使用重新映射数据的数据
REMAP_TABLE = 'EMPLOYEES':'EMP'
SQL*Loader: Overview SQL*加载程序:概述
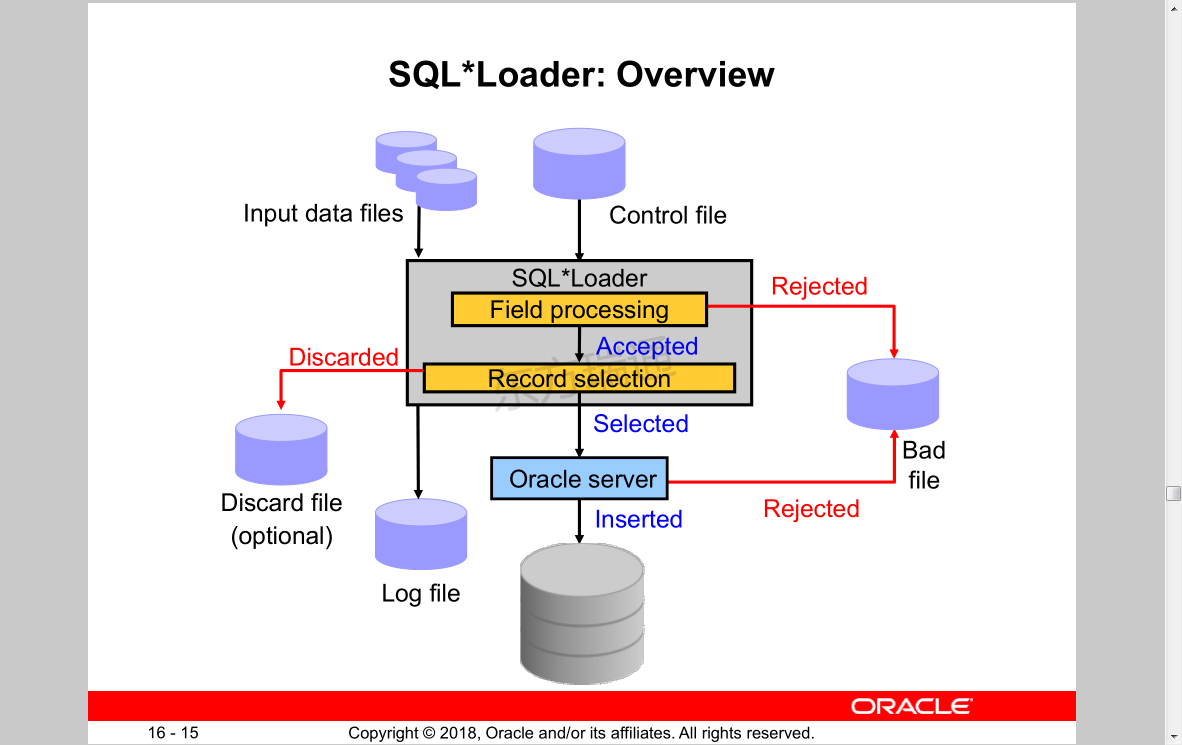
SQL*Loader Control File
The SQL*Loader control file instructs SQL*Loader about:
• Location of the data to be loaded
• Data format
• Configuration details:
– Memory management
– Record rejection
– Interrupted load handling details
• Data manipulation details
SQL*加载程序控制文件
SQL*加载器控制文件指示SQL*加载器关于:
•待加载数据的位置
•数据格式
•配置细节:
–内存管理
–拒绝记录
–中断负载处理细节
•数据操作细节
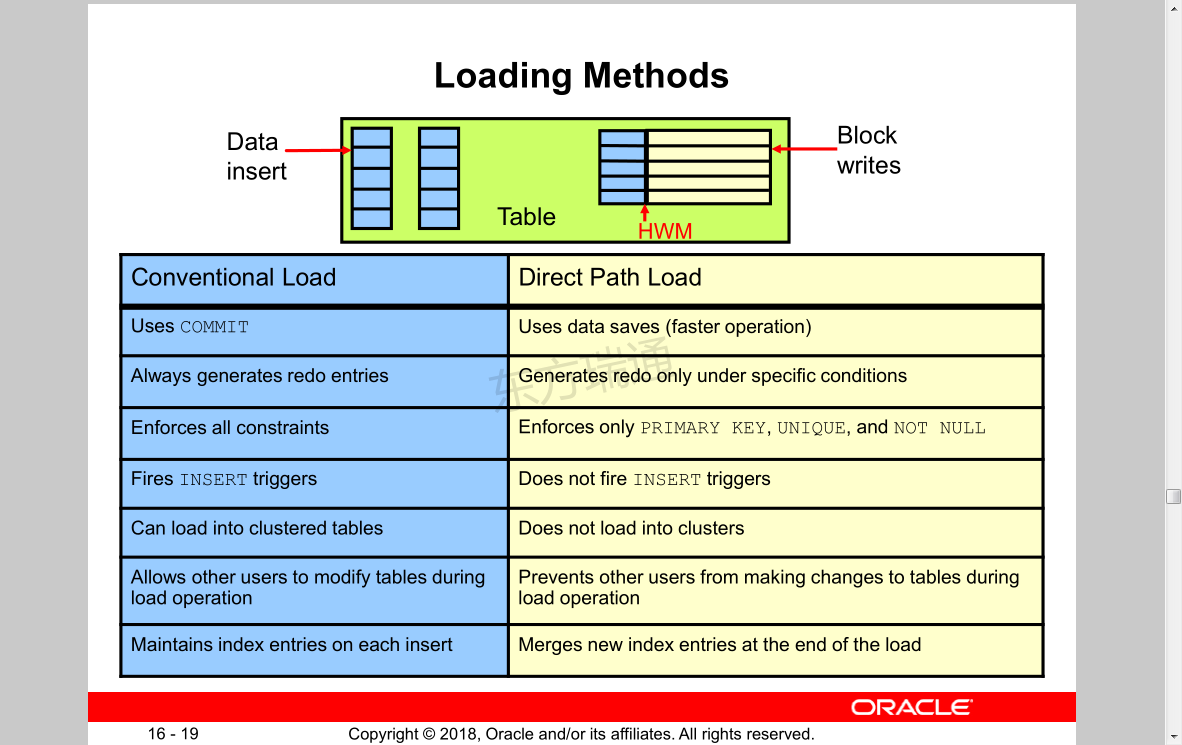
Loading Methods 装载方法
Conventional Load Direct Path Load
Uses COMMIT
Always generates redo entries
Enforces all constraints
Fires INSERT triggers
Can load into clustered tables
Uses data saves (faster operation)
Generates redo only under specific conditions
Enforces only PRIMARY KEY, UNIQUE, and NOT NULL
Does not fire INSERT triggers
Does not load into clusters
Allows other users to modify tables during
load operation
Prevents other users from making changes to tables during load operation
Maintains index entries on each insert Merges new index entries at the end of the load
常规负载直接路径负载
使用提交
总是生成重做条目
强制执行所有约束
激发插入触发器
可以加载到群集表中
使用数据保存(更快的操作)
仅在特定条件下生成重做
只强制主键,唯一,不为空
不触发插入触发器
不加载到群集
允许其他用户在
负荷运行
防止其他用户在加载操作期间更改表
在每次插入时维护索引项在加载结束时合并新索引项
[root@yf ~]# su - oracle
SQL> startup
SQL> exit
[oracle@yf ~]$ sqlldr -help 查看SQL*Loader 的命令帮助
SQL*Loader: Release 18.0.0.0.0 - Production on Sun Jun 28 20:02:20 2020
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Usage: SQLLDR keyword=value [,keyword=value,...]
Valid Keywords:
userid -- ORACLE username/password
control -- control file name
log -- log file name
bad -- bad file name
data -- data file name
discard -- discard file name
discardmax -- number of discards to allow (Default all)
skip -- number of logical records to skip (Default 0)
load -- number of logical records to load (Default all)
errors -- number of errors to allow (Default 50)
rows -- number of rows in conventional path bind array or between direct path data saves
(Default: Conventional path 250, Direct path all)
bindsize -- size of conventional path bind array in bytes (Default 1048576)
silent -- suppress messages during run (header,feedback,errors,discards,partitions)
direct -- use direct path (Default FALSE) 装载方式
parfile -- parameter file: name of file that contains parameter specifications
parallel -- do parallel load (Default FALSE)
file -- file to allocate extents from
skip_unusable_indexes -- disallow/allow unusable indexes or index partitions (Default FALSE)
skip_index_maintenance -- do not maintain indexes, mark affected indexes as unusable (Default FALSE)
commit_discontinued -- commit loaded rows when load is discontinued (Default FALSE)
readsize -- size of read buffer (Default 1048576)
external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE
columnarrayrows -- number of rows for direct path column array (Default 5000)
streamsize -- size of direct path stream buffer in bytes (Default 256000)
multithreading -- use multithreading in direct path
resumable -- enable or disable resumable for current session (Default FALSE)
resumable_name -- text string to help identify resumable statement
resumable_timeout -- wait time (in seconds) for RESUMABLE (Default 7200)
date_cache -- size (in entries) of date conversion cache (Default 1000)
no_index_errors -- abort load on any index errors (Default FALSE)
partition_memory -- direct path partition memory limit to start spilling (kb) (Default 0)
table -- Table for express mode load
date_format -- Date format for express mode load
timestamp_format -- Timestamp format for express mode load
terminated_by -- terminated by character for express mode load
enclosed_by -- enclosed by character for express mode load
optionally_enclosed_by -- optionally enclosed by character for express mode load
characterset -- characterset for express mode load
degree_of_parallelism -- degree of parallelism for express mode load and external table load
trim -- trim type for express mode load and external table load
csv -- csv format data files for express mode load
nullif -- table level nullif clause for express mode load
field_names -- field names setting for first record of data files for express mode load
dnfs_enable -- option for enabling or disabling Direct NFS (dNFS) for input data files (Default FALSE)
dnfs_readbuffers -- the number of Direct NFS (dNFS) read buffers (Default 4)
sdf_prefix -- prefix to append to start of every LOB File and Secondary Data File
help -- display help messages (Default FALSE)
empty_lobs_are_null -- set empty LOBs to null (Default FALSE)
defaults -- direct path default value loading; EVALUATE_ONCE, EVALUATE_EVERY_ROW, IGNORE, IGNORE_UNSUPPORTED_EVALUATE_ONCE, IGNORE_UNSUPPORTED_EVALUATE_EVERY_ROW
direct_path_lock_wait -- wait for access to table when currently locked (Default FALSE)
PLEASE NOTE: Command-line parameters may be specified either by
position or by keywords. An example of the former case is 'sqlldr
scott/tiger foo'; an example of the latter is 'sqlldr control=foo
userid=scott/tiger'. One may specify parameters by position before
but not after parameters specified by keywords. For example,
'sqlldr scott/tiger control=foo logfile=log' is allowed, but
'sqlldr scott/tiger control=foo log' is not, even though the
position of the parameter 'log' is correct.
[oracle@yf ~]$
SQL*Loader Express Mode
• Specify a table name to initiate an Express Mode load.
• Table columns must be scalar data types (character,number, or datetime).
• A data file can contain only delimited character data.
• SQL*Loader uses table column definitions to determine input data types.
• There is no need to create a control file.
SQL*加载程序快速模式
•指定表名以启动快速模式加载。
•表列必须是标量数据类型(字符、数字或日期时间)。
•数据文件只能包含分隔字符数据。
•SQL*加载器使用表列定义来确定输入数据类型。
•无需创建控制文件。
[oracle@yf ~]$ sqlldr hr/hr table=test 将test.bat文件装载到test表中,装载是以添加方式装载的,test表在装载前的记录并不会删除

External Tables
External tables are read-only tables stored as files on the operating system outside of the Oracle database.
外部表
外部表是只读表,作为文件存储在Oracle数据库之外的操作系统上。
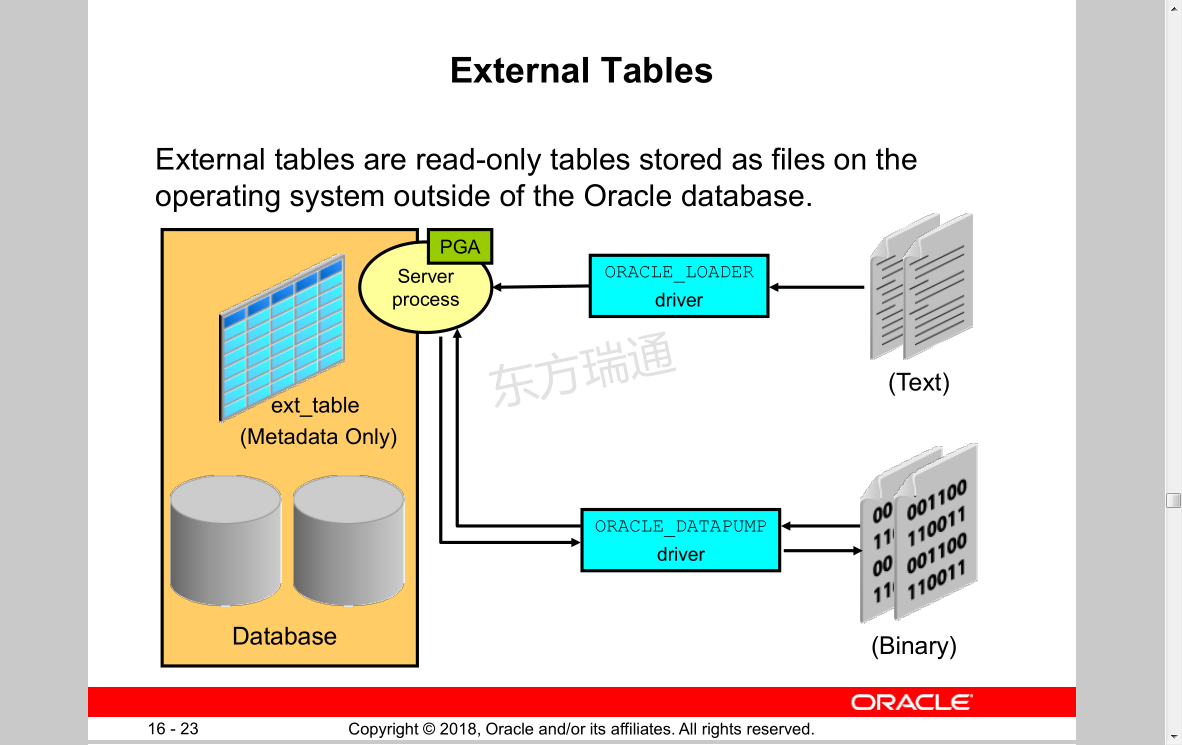
External Table: Benefits
• Data can be used directly from the external file or loaded into another database.
• External data can be queried and joined directly in parallel with tables residing in the database, without requiring it to be loaded first.
• The results of a complex query can be unloaded to an external file.
• You can combine generated files from different sources for loading purposes.
From Oracle Database From external file
外部表格:好处
•数据可以直接从外部文件中使用,也可以加载到另一个数据库中。
•可以直接查询外部数据并将其与数据库中的表并行连接,而无需先加载外部数据。
•复杂查询的结果可以卸载到外部文件中。
•您可以将来自不同来源的生成文件组合起来用于加载目的。
从外部文件的Oracle数据库
Defining an External Tables with ORACLE_LOADER
用ORACLE加载程序定义外部表
CREATE TABLE extab_employees
(employee_id NUMBER(4),
first_name VARCHAR2(20),
last_name VARCHAR2(25),
hire_date DATE)
ORGANIZATION EXTERNAL
( TYPE ORACLE_LOADER DEFAULT DIRECTORY extab_dat_dir
ACCESS PARAMETERS
( records delimited by newline
badfile extab_bad_dir:'empxt%a_%p.bad'
logfile extab_log_dir:'empxt%a_%p.log'
fields terminated by ','
missing field values are null
( employee_id, first_name, last_name,
hire_date char date_format date mask "dd-mon-yyyy“))
LOCATION ('empxt1.dat', 'empxt2.dat') )
PARALLEL REJECT LIMIT UNLIMITED;

External Table Population with ORACLE_DATAPUMP
使用ORACLE数据泵填充外部表

Using External Tables
• Querying an external table:
SQL> SELECT * FROM extab_employees;
• Querying and joining an external table with an internal table:
SQL> SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM departments d, extab_employees e WHERE d.department_id = e.department_id;
• Appending data to an internal table from an external table:
使用外部表
•查询外部表:
•查询外部表并将其与内部表连接:
•从外部表向内部表追加数据:
Data Dictionary 数据字典
View information about external tables in:
• [DBA| ALL| USER]_EXTERNAL_TABLES
• [DBA| ALL| USER]_EXTERNAL_LOCATIONS
• [DBA| ALL| USER]_TABLES
• [DBA| ALL| USER]_TAB_COLUMNS
• [DBA| ALL]_DIRECTORIES
Quiz
Like other database objects, directory objects are owned by the user that creates them unless another schema is specified during creation.
测验
与其他数据库对象一样,目录对象由创建它们的用户拥有,除非在创建过程中指定了其他架构 错的
An index can be created on an external table.
可以在外部表上创建索引 错的 ,外表不可建立索引, 可将外边转换成堆表
Summary
In this lesson, you should have learned how to:
• Describe ways to move data
• Explain the general architecture of Oracle Data Pump
• Create and use directory objects
• Use Data Pump Export and Import to move data between Oracle databases
• Use SQL*Loader to load data from a non-Oracle database (or user files)
• Use external tables to move data via platform-independent files
摘要
在本课中,您应该学习如何:
•描述移动数据的方法
•解释Oracle数据泵的总体架构
•创建和使用目录对象
•使用数据泵导出和导入在Oracle数据库之间移动数据
•使用SQL*加载程序从非Oracle数据库(或用户文件)加载数据
•使用外部表通过独立于平台的文件移动数据