曲绍冰
学习心得:
在看了视频之后,我学到了很多关于机器学习和深度学习的知识。知道了人工智能、机器学习和深度学习大致包含的内容。同时我还了解到深度学习相较于传统机器学习的优点。认识到了深度学习的发展和应用领域,也认识到了深度学习的不足之处:算法输出不稳定,容易被攻击;模型复杂度高,难以纠错和调试;模型层级复合程度高,参数不透明;端到端训练方式对数据依赖性强,模型增量差;专注直观感知类问题,对开放性推理问题无能为力;机器偏见难以避免。
问题总结:
1.为什么sigmoid函数现在已经不再适用了?
2.选择loss函数时应该注意什么?
陈明朝
学习心得:
通过视频学习,相对了解了“深度学习”的作用和使用限制。“深度学习”应用很广泛,基于“深度学习”的神经网络实例,误差反向传播的学习方式是十分重要有用的知识。但是,通过视频学习,对于三层前馈神经网络bp算法还是没有理解好,前馈反馈过程没有掌握住。
张婷婷
学习心得:
在进行绪论的课程听讲时,最开始是讲了一下有关人工智能方面的想关东西,就从人工智能的起源于开始入手,以前也有自己或者老师讲授了解过相关的一些知识,但是感觉这堂课上带来的人工智能的介绍更加的有冲击力。最开始了解人工智能的时候就只是很客观的说人工智能在我们生活中的大部分应用,这堂课就结合了更具体的生活案例进行讲解,在平常的生活中真的很少结合所学习的专业知识进行思考。很喜欢这样的授课方式,感觉能够接受到的东西比往常自己了解的方式更多,并且更能直观的了解到自己的兴趣。(这个也是这门课程最大的上课的优点,可能是他的定义就是如此,但是还是觉得这样的授课方式真的很有吸引力。)
深度学习就字面意思上进行对人工智能到机器学习再到更深层次的深度学习。就我感觉我觉得机器学习就是了解在人工智能的嵌入下的机器进行学习,但是机器学习可操作定义是其本质就是一个基于经验数据的高数估计问题。实话说这样的转换还真的挺大的。从模型,策略和算法进行机器学习,在模型方面进行学习的时候有突出数据标记更为重要,半监督学习和强化学习。不知道咋听的,感觉机器学习的部分没有听到一些更具体的东西。就前面的机器学习是深度学习的前提,从机器学习到神经网络的应用,感觉脑海里就直接把神经网络等价到了深度学习,也不知道这样的是不是对的。在深度学习概述中有如何去选择研究方向,不能从传统的方向上去研究,最好是可以从传统问题的组合和现代工业界存在问题的方向进行研究。也是这样的,传统的方向已经被更多的研究人员进行研究了,再选择这样的方式感觉也很难得到突出的成绩。深度学习的“不能”有很多,在一定程度上是由“深度学习”本身的特性所决定的,比如数据集在标注过程中带来的偏见最终会导致算法判决结果的偏见、深度学习相对于传统方法而言,准确性越来越高,但是可解释性越来越差。 在符号主义和联结主义方面上,符号主义的解释性较好,但是准确性较差;以联结主义为代表的深度学习则相反,当然如果想二者兼具,最好的方法就是二者结合。连接主义它是一个自下而上的,他的一个思路是模拟人的大脑的结构;符号主义的更多是自上而下的,就像它代表的是专家系统,也就是说他会用人的推理方式。很多关于深度学习和知识图谱之间的一个结合,那么大概有两个方向:1、把知识图谱以先验的形式加入到一个深度学习的表示学习里边;2、基于深度学习对知识图谱的构建去做一些服务,比如说,深度学习应用在图谱的切入表示里面。浅层神经网络好像更加贴近于线性问题——线性超平面将数据分离,单层感知器无法解决最简单的异或问题。激活函数的选择也很关键,relu和sigmoid,前者没有梯度消失的问题,一定程度上二者是等价的。万有逼近定理;第二层看神经网络见的,其实是经过线性变换之后的数据,等效于从不同的视角看数据集;双隐层在理论上可以逼近任何非线性函数。神经网络变深或者是变宽,分别会产生不同的效果。多分类和多标签都可以通过一定的方式转化为二分类的问题,有想关理论证明,瘦高神经网络效果更好。多层神经网络——求导乘积导致最后结果越来越小,逐层预训练:局部极小值数量随着层数增加急剧增多,自编码器最初是用来降维的。后面的东西感觉好多,并不是很能够接受到,感觉只能通过反复回放观看进行理解记忆。
问题总结:
1.对机器学习很懵,可能是对自己思维的转换不够。
2.深度学习能否直接等价于精神网络?
黄成灏
学习心得:
第一课绪论的学习中,了解到了深度学习的发展历史,现状和前景,对深度学习相关的基本概念有了相关的了解,比如印象较深的监督,无监督,半监督,强化四种学习的区别,在机器学习怎么学当中从模型策略算法三个方面学习。
在传统机器学习和深度学习比较的板块中,我最大的体会就是从传统机器学习到后深度学习时代的进步中,其实就是在把工作交给机器人以达到更高效的工作为目的。
了解了神经网络的一个发展的历史。以及现在的一些应用情况。
第二课深度学习的概述中,了解到了现在深度学习的一些不足的地方:稳定性低,可调式性差,参数不透明,机器偏见,增量性差,推理能力差。这六个方面中个人对于机器偏见这个方面印象深刻,怎么样才能让机器不要延续错误的经验,让我觉得很有意思。
在神经网络基础的课中,浅层神经网络通过与神经元的类比,我理解到了浅层神经网络的基本工作原理,在后面的学习中,基于数字逻辑和线性代数的知识,看懂了一部分,但是对于更多方面还需要更多的知识查阅和反复观看才能理解。
总之,看完这两课,我对于深度学习以及当中的神经网络方面有了基本的了解和一些名词概念的认识,能够看清楚学习的方向以及认识到自己的不足,以上就是本次学习的新的体会。
徐敏霞
学习心得:
通过这次视频学习,我对人工智能、机器学习和深度学习的关系有了更深的理解,人工智能是我们要实现的目标或者说是研究的大方向,而机器学习是实现人工智能的一个方法,深度学习则是实现机器学习的一个方法,这三者之间具有包含关系;同时,人工智能并不是万能的,甚至它和人类的差距并没有能让我们产生机器人统治人类的恐惧。虽然人工智能的计算和感知能力远远超过人类,但是它的认识能力并没有很强,就像阿尔法机器人依靠软件方面的优势在围棋方面战胜人类,运动机器人依靠硬件的进步实现了运动,但是目前机器人没有乌鸦一样发现有半瓶水不能喝,于是添加石子的智慧,更何况与人一样呢?还有在深度学习方面也存在很多问题,比如算法输出结果不稳定,容易受到攻击等。此外,我发现要研究人工智能,不仅仅局限于计算机领域,它会用到通信、数学、物理等方面的知识,甚至也需要工业方面的帮助,这就需要通用型的人才了。
问题总结:
1.逐层预训练加入监督之后效果不是很好,没有解决梯度消失,只是解决了初始化问题,这是为什么?此外,既然梯度消失是因为sigmoid激光函数引起的,那为什么不考虑换激光函数而要通过逐层预训练设置一个好的初始值使得实现多层神经网络呢?
2.受限玻尔兹曼机和自编码器是神经网络的两种基本结构,都可以起到降维的作用,并且都可以对神经网络进行无监督的预训练,那它们是什么关系,是并列的吗?
赵红霞
学习心得:
在此次课程的学习中,我对人工智能的过去、现在和未来有了一定的了解,从计算到感知到认知,人工智能从能存能算,到能听会说、能看会认,再到能理解、会思考,我们最终希望人工智能可以像人一样可以进行逻辑推理、知识论断、探索思考。而“人工智能+”对我们的生活和行业也带来了很大的变化,给我们带来了方便和快捷。再说机器学习,它是实现人工智能最主要的一个方法,它的应用领域主要有计算机视觉、语音技术和自然语言处理。机器学习是从数据中自动提取知识,它既有好的一面,也有不好的一面,可以减少人工繁杂的工作,提高信息处理的效率,且来源比较真实,但结果可能不易理解。而关于深度学习,它是从机器学习中的人工神经网络发展出来的新领域,其思想就是对堆叠多个层,也就是说这一层的输出作为下一层的输入。深度学习的“不能”有稳定性低、可调试性差、参数不透明、机器偏见、增量性差和推理能力差几方面。与此对应的是浅层神经网络,它是由多个神经元构成的,对于一个简单两层神经网络,它包含了输入层、输出层和隐藏层,其中输入层不是神经元。此外,课程中也说明了网络应该越“深”越好,增加网络深度可以带来更强的网络表示能力,产生更多的线性区域。总之,这次的学习让我对机器学习和深度学习相关的知识有了初步的认识和了解,也拓展了我的这方面的知识。
问题总结:
1.对机器学习模型这一部分的内容不太理解。
2.不太明白感知器是如何做到自动学习的?
张杰
学习心得:
1.介绍了如今国际环境下各国关于人工智能的研究情况,而我国有一些劣势。对此我国教育部也制定了相关的措施;人工智能的起源、标志性事件和发展;深度学习;Google无人自行车;
2.对深度学习更深入的研究理解;深度学习的“不能”;万有逼近定理;自编译器;受限玻尔兹曼机; 自编译器和受限玻尔兹曼机的比较;预训练的实际作用。
问题总结:
1.为什么构建深度学习模型需要使用GPU?
2.是否需要大量数据来训练深度学习模型?
代码练习:
1. pytorch基础:

想法解读:代码中关于m@v的内容出现的错误应该是float和long类型不一致导致的错误,暂时不知道怎么弄,其他的代码中关于数组以及数组矩阵的输出便是运用了不同的函数,使得数组格式发生变换。修改后的结果如下图:

2. 螺旋数据分类:
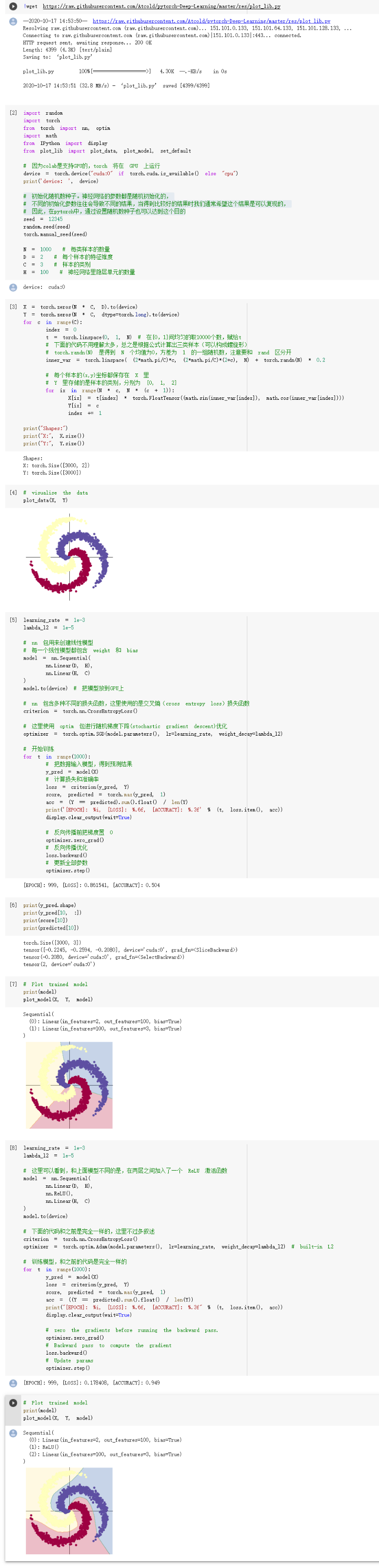
想法解读:因为PyTorch默认会对梯度进行累加,根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 了。
从以上可以看出线性模型对于复杂的数据难以实现准确分类 。
其中,加入了ReLu激活函数后解决了梯度消失的问题,所以之后分类的准确率提高了。