这篇博客主要是讲下我在阅读ssd论文时对论文的理解,并且自行使用pytorch实现了下论文的内容,并测试可以用。
开篇放下论文地址https://arxiv.org/abs/1512.02325,可以自行参考论文。
接着放下我使用pytorch复现的版本地址https://github.com/acm5656/ssd_pytorch,如果这篇博客或者代码有帮到你,麻烦给个星哈。
代码解读的博客链接如下https://www.cnblogs.com/cmai/p/10080005.html,欢迎大家前来阅读。
模型图
首先来介绍下ssd模型:
模型图如下:

在图中,我们可以大概看下模型的结构,前半部分是vgg-16的架构,作者在vgg-16的层次上,将vgg-16后边两层的全连接层(fc6,fc7)变换为了卷积层,conv7之后的层则是作者自己添加的识别层。
我们可以在模型图中观察到在conv4_3层,有一层Classifier层,使用一层(3,3,(4*(Classes+4)))卷积进行卷积(Classes是识别的物体的种类数,代表的是每一个物体的得分,4为x,y,w,h坐标,乘号前边的4为default box的数量),这一层的卷积则是提取出feature map,什么是feature map呢,我们在下文会介绍,这时候我们只需要简单的了解下。不仅在conv4_3这有一层卷积,在Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2都有一层这样的卷积层,因此最后提取到6个feature map层。那么细心的小伙伴会发现,最后的Detections:8732 per Class是怎么算出来的呢?具体的计算如下:
Conv4_3 得到的feature map大小为38*38:38*38*4 = 5776
Conv7 得到的feature map大小为19*19:19*19*6 = 2166
Conv8_2 得到的feature map大小为10*10:10*10*6 = 600
Conv9_2 得到的feature map大小为5 * 5 :5 * 5 * 6 = 150
Conv10_2得到的feature map大小为3 * 3 :3 * 3 * 4 = 36
Conv11_2得到的feature map大小为1 * 1 :1 * 1 * 4 = 4
最后结果为:8732
这时候会有小伙伴会疑惑,为什么要乘以4或者6,这个是default box数量,这个会在下文将feature map时介绍到。
那么ssd则是在这8732个结果中找到识别的物体。
default box 和 feature map
讲完模型图,这就来填之前的留下的两个坑,什么是feature map和default box呢?
先看下论文中的图
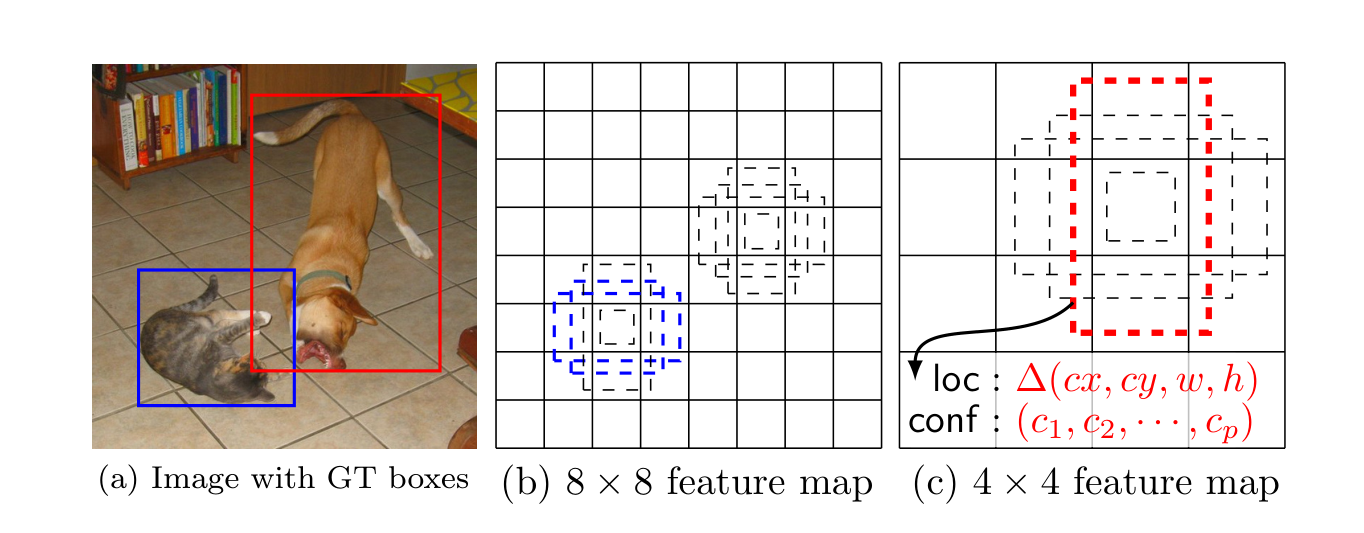
feature map则是刚才指的Classifier产生的结果,如图(b)和(c) b是大小8*8的feature map,c是大小4*4的feature map,其中每一个小个子都包含多个box,同时每个box对应loc(位置坐标)和conf(每个种类的得分),default box长宽比例默认有四个和六个,四个default box是长宽比为(1:1)、(2:1)、(1:2)、(1:1)这四个,六个则是添加了(1:3)、(3:1)这两个,这时候有小伙伴会问,为什么会有两个(1:1)呢。这时候就要讲下论文中Choosing scales and aspect ratios for default boxes这段内容了。作者认为不同的feature map应该有不同的比例,这是什么意思呢,代表的是default box中这个1在原图中的尺寸是多大的,计算公式如下所示:

公式Sk即代表在300*300输入中的比例,m为当前的feature map是第几层,k代表的是一共有多少层的feature map,Smin和Smax代表的是第一层和最后一层所占的比例,在ssd300中为0.2-0.9。那么S怎么用呢,作者给出的计算方法是,wk = Sk√ar,hk = Sk / √ar,其中ar代表的是之前提到的default box比例,即(1,2,3,1/2,1/3),对于default box中心点的值取值为((i+0.5) / |fk|,(j+0.5)/|fk|),其中i,j代表在feature map中的水平和垂直的第几格,fk代表的是feature map的size。那么重点来了,还记得之前有一个小疑问,为什么default box的size有两个1吗?作者在这有引入了一个Sk' = √Sk*Sk+1,多出来的那个1则是通过使用这个Sk'来计算的,有的小伙伴可能会有疑问,这有了k+1则需要多出来一部分的Sk啊,是的没错,作者的代码中就添加了两层,第一层取0.1,最后一层取1。到这位置,基本上模型和default box是解释清楚了。
损失函数
讲完之前的所有内容,模型我们大概都有了了解,最后则是损失函数部分了。先放出来论文中的损失函数。
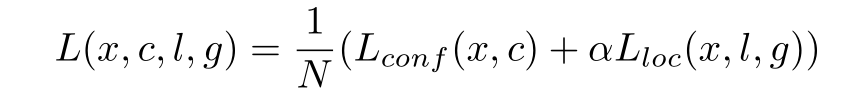
Lconf和Lloc分别代表的是得分损失函数和位置损失函数,N代表的数量,接下来将两个函数分开来看下:
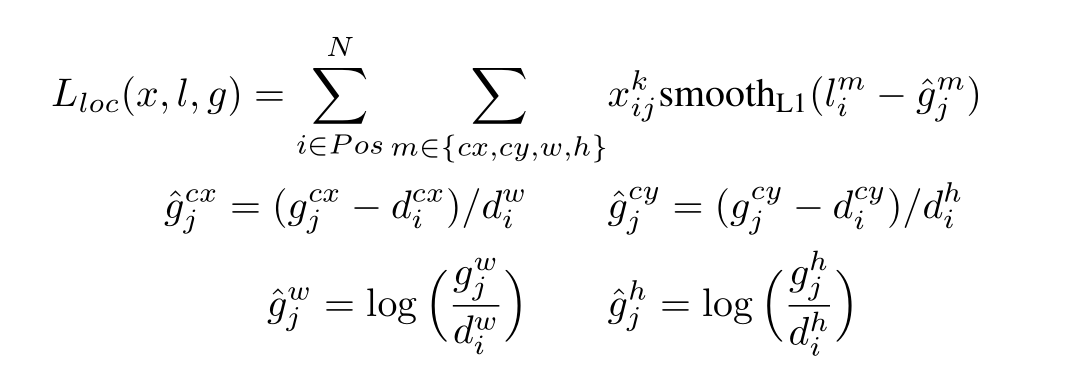
其中Xijk代表的是第i个default box,第j个box的比例,k代表的是第k个种类,X的值为{0,1},gj代表的是ground truth box,即图片中类别的位置,有四个,分别为cx,cy,w,h,di则对应的是之前default box计算的大小,然后根据上述公式转换算出所有的g',使用预测的l进行做差,使用smoothL1损失函数计算损失。

Lconf函数则相对比较简单,通过使用sigmod求出Cip的正比和反比,求log相加即可。
结束
到此整个ssd模型大体上算是讲清楚了,从model到match box到loss函数,算是整体过了一遍,其中还有一些不清楚的地方,可以参考下篇讲代码实现的博客。在论文中作者还使用了data argumentation,扩大数据,具体的做法在此不详细讲解了,笔者以后有时间会加以了解并讲解的。