一、基础环境
三台虚拟机,使用CentOS 6.5 版本Linux系统
二、SSH免密登录
对于集群来说,需要用我们的NameNode主节点来控制所有的DataNode开启节点服务,所以我们的方式就是用NameNode节点连接其他的DataNode节点,输入开启命令即可。
但是一天机器连接另外一台机器需要输入密码,为解决输入密码的麻烦,我们就需要用到ssh免密登录
SSH免密登录的原理这里不说,自行百度
步骤:
1.cd到root目录下,查看有没有.ssh 文件夹,没有的话可以自己建立一个
2.然后输入命令:ssh-keygen -t rsa 生成公私钥对,这个钥对会在.ssh文件夹下,一个公钥,一个私钥

3.最后将公钥发给远程主机(这里我们把公钥发给我们本机,这样我们只需要再克隆俩次本机,这样后面的俩个机器,ssh 免密登录就都配置好了,一举两得)
ssh-copy-id root@【ip地址】

4.测试,使用 ssh 【IP地址】,看能不能连接到对方主机,第一次会让你输入yes,输入即可 #小技巧: ssh 0.0.0.0 代表本机
三、搭建集群
1.每个节点上 设置ip地址,主机名,映射 防火墙 selinux jdk ssh免密登陆 (略,详情见上一篇博客)
2.在每个节点 的 /opt/isntall 目录下 安装Hadoop
3.修改六个配置文件,并同步其余两个节点 #【一样】见上一篇博客
1 1. hadoop-env.sh JDK 2 2. core-site.xml [一样] 3 <property> 4 <name>fs.default.name</name> 5 <value>hdfs://hadoop1.baizhiedu.com:8020</value> 6 </property> 7 <property> 8 <name>hadoop.tmp.dir</name> 9 <value>/opt/install/hadoop-2.5.2/data/tmp</value> 10 </property> 11 3. hdfs-site.xml 12 <property> 13 <name>dfs.permissions.enabled</name> 14 <value>false</value> 15 </property> 16 4. yarn-site.xml[一样] 17 <property> 18 <name>yarn.nodemanager.aux-services</name> 19 <value>mapreduce_shuffle</value> 20 </property> 21 5. mapred-site.xml[一样] 22 <property> 23 <name>mapreduce.framework.name</name> 24 <value>yarn</value> 25 </property> 26 6. slaves 27 hadoop1.baizhiedu.com 28 hadoop2.baizhiedu.com 29 hadoop3.baizhiedu.com
4.在NameNode 节点上 格式化 bin/hdfs namenode -format
5.启动、关闭集群
sbin/start-dfs.sh
sbin/stop-dfs.sh
6.测试 到Windows上输入 hostname:50070 检测,能进到页面,代表NameNode 启动成功,点击Datanodes 看到三个DataNode 代表集群搭建成功
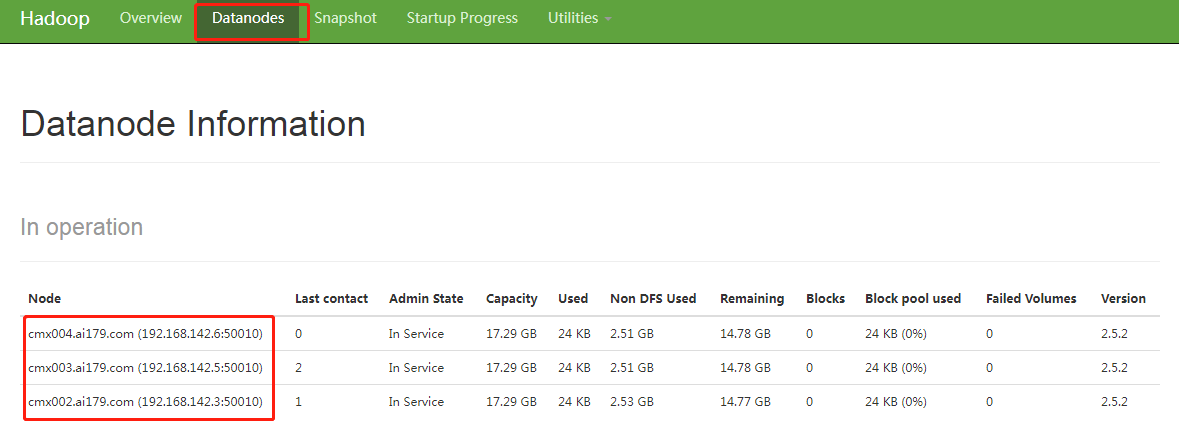
7.注意
若第六步测试没有成功,可做如下的修改
1.删除每个节点的 Hadoop 下data/tmp的所有文件,之后再次重启服务,如还没有达到最终的结果,请看第二步
2.在NameNode的Hadoop的配置文件,仔细检查每一个文件,看有没有错,再就是检测三个节点,能不能互相ssh 通