一 生成器 与 yield
若函数体包含yield关键字,再调用函数,并不会执行函数体代码,得到的返回值即生成器对象
>>> def my_range(start,stop,step=1):
... print('start...')
... while start < stop:
... yield start
... start+=step
... print('end...')
...
>>> g=my_range(0,3)
>>> g
<generator object my_range at 0x104105678>
生成器内置有__iter__和__next__方法,所以生成器本身就是一个迭代器
>>> g.__iter__
<method-wrapper '__iter__' of generator object at 0x1037d2af0>
>>> g.__next__
<method-wrapper '__next__' of generator object at 0x1037d2af0>
因而我们可以用next(生成器)触发生成器所对应函数的执行,
>>> next(g) # 触发函数执行直到遇到yield则停止,将yield后的值返回,并在当前位置挂起函数
start...
0
>>> next(g) # 再次调用next(g),函数从上次暂停的位置继续执行,直到重新遇到yield...
1
>>> next(g) # 周而复始...
2
>>> next(g) # 触发函数执行没有遇到yield则无值返回,即取值完毕抛出异常结束迭代
end...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
既然生成器对象属于迭代器,那么必然可以使用for循环迭代,如下:
>>> for i in countdown(3):
... print(i)
...
countdown start
3
2
1
Done!
有了yield关键字,我们就有了一种自定义迭代器的实现方式。yield可以用于返回值,但不同于return,函数一旦遇到return就结束了,而yield可以保存函数的运行状态挂起函数,用来返回多次值
二 yiedld 表达式应用
在函数内可以采用表达式形式的yield
>>> def eater():
... print('Ready to eat')
... while True:
... food=yield
... print('get the food: %s, and start to eat' %food)
...
可以拿到函数的生成器对象持续为函数体send值,如下
>>> g=eater() # 得到生成器对象
>>> g
<generator object eater at 0x101b6e2b0>
>>> next(g) # 需要事先”初始化”一次,让函数挂起在food=yield,等待调用g.send()方法为其传值
Ready to eat
>>> g.send('包子')
get the food: 包子, and start to eat
>>> g.send('鸡腿')
get the food: 鸡腿, and start to eat
针对表达式形式的yield,生成器对象必须事先被初始化一次,让函数挂起在food=yield的位置,等待调用g.send()方法为函数体传值,g.send(None)等同于next(g)。
我们可以编写装饰器来完成为所有表达式形式yield对应生成器的初始化操作,如下
def init(func):
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper
@init
def eater():
print('Ready to eat')
while True:
food=yield
print('get the food: %s, and start to eat' %food)
表达式形式的yield也可以用于返回多次值,即变量名=yield 值的形式,如下
>>> def eater():
... print('Ready to eat')
... food_list=[]
... while True:
... food=yield food_list
... food_list.append(food)
...
>>> e=eater()
>>> next(e)
Ready to eat
[]
>>> e.send('蒸羊羔')
['蒸羊羔']
>>> e.send('蒸熊掌')
['蒸羊羔', '蒸熊掌']
>>> e.send('蒸鹿尾儿')
['蒸羊羔', '蒸熊掌', '蒸鹿尾儿']
三 三元表达式、生成式
3.1三元表达式
三元表达式是python为我们提供的一种简化代码的解决方案,语法如下
res = 条件成立时返回的值 if 条件 else 条件不成立时返回的值
针对下述场景
def max2(x,y):
if x > y:
return x
else:
return y
res = max2(1,2)
用三元表达式可以一行解决
x=1
y=2
res = x if x > y else y # 三元表达式
3.2列表生成式
列表生成式是为了快速生成列表的一种方式
针对下述场景
#列表生成器 把0-9放进列表内
l = []
for i in range(10):
l.append(i)
print(l)
用列表生成式一行解决
案例1
# 列表生成式 打印0-9
l = [ i for i in range(10)]
print(l)
案例2
# 把大于5的放到列表里面
l = [i for i in range(10) if i>5]
print(l)
案例3
# 给每个元素后面加上烧饼
names = ['lxx','hxx','wxx','lili']
l = [name + 'sb' for name in names ]
print(l)
案例4
# 把字符串后面烧饼结尾的放到一个列表里面
names = ['egon','lxx_sb','hxx_sb','wxx_sb']
res = [ name for name in names if name.endswith('sb')]
print(res)
3.3字典生成式
字典生成式是为了快速生成字典的一种方式
res = {i: i ** 2 for i in range(5)}
print(res)
>>> {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
3.4集合生成式
res = {i for i in range(5)}
print(res)
3.5生成器表达式(生成器生成式)
创建一个生成器对象有两种方式,一种是调用带yield关键字的函数,另一种就是生成器表达式,与列表生成式的语法格式相同,只需要将[]换成(),即:
(expression for item in iterable if condition)
对比列表生成式返回的是一个列表,生成器表达式返回的是一个生成器对象
>>> [x*x for x in range(3)]
[0, 1, 4]
>>> g=(x*x for x in range(3))
>>> g
<generator object <genexpr> at 0x101be0ba0>
对比列表生成式,生成器表达式的优点自然是节省内存(一次只产生一个值在内存中)
>>> next(g)
0
>>> next(g)
1
>>> next(g)
4
>>> next(g) #抛出异常StopIteration
如果我们要读取一个大文件的字节数,应该基于生成器表达式的方式完成
with open('db.txt','rb') as f:
nums=(len(line) for line in f)
total_size=sum(nums) # 依次执行next(nums),然后累加到一起得到结果=
四 函数递归
4.1函数递归介绍
函数不仅可以嵌套定义,还可以嵌套调用,即在调用一个函数的过程中,函数内部又调用另一个函数,而函数的递归调用指的是在调用一个函数的过程中又直接或间接地调用该函数本身
例如
在调用f1的过程中,又调用f1,这就是直接调用函数f1本身
def f1():
print('from f1')
f1()
f1()
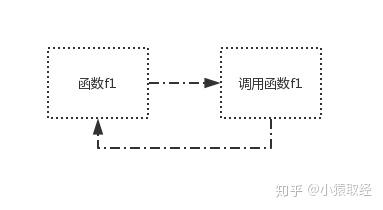
在调用f1的过程中,又调用f2,而在调用f2的过程中又调用f1,这就是间接调用函数f1本身
def f1():
print('from f1')
f2()
def f2():
print('from f2')
f1()
f1()
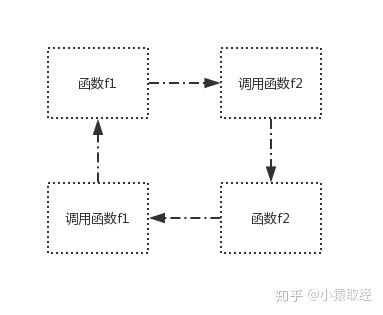
从上图可以看出,两种情况下的递归调用都是一个无限循环的过程,但在python对函数的递归调用的深度做了限制,因而并不会像大家所想的那样进入无限循环,会抛出异常,要避免出现这种情况,就必须让递归调用在满足某个特定条件下终止。
提示:
#1. 可以使用sys.getrecursionlimit()去查看递归深度,默认值为1000,虽然可以使用
sys.setrecursionlimit()去设定该值,但仍受限于主机操作系统栈大小的限制
#2. python不是一门函数式编程语言,无法对递归进行尾递归优化。
4.2回溯与递推
# 大前提:递归调用一定要在某一层结束
# 递归的两个阶段:
#1、回溯:向下一层一层运行
#2、递推:向上一层返回
举例:第一个同学说比第二个同学大十岁第二个同学说比第三个同学大十岁....最后一个同学说自己18岁
# age(5) = age(4) + 10
# age(4) = age(3) + 10
# age(3) = age(2) + 10
# age(2) = age(1) + 10
# age(1) =18
基于函数需要的时候直接调用
# def age(n):
# if n ==1:
# return 18
# return age(n-1) +10
# res = age(5)
# print(res)
举例1
# nums = [1,[2,[3,[4,[5,[6,[7,]]]]]]]
# def get(l):
# for num in l:
# if type(num) is list:
# get(num)
# else:
# print(num)
# get(nums)
举例2 二分法
nums = [-3,1,3,7,13,23,37,43,57,63,77,91,103]
find_num = 64
def find (nums,find_num):
print(nums)
if len(nums)==0:
print('not in ')
return
num= len(nums) //2
if find_num > nums[num]:
find(nums[num+1:],find_num)
elif find_num < nums[num]:
find(nums[:num],find_num)
else:
print('you got it')
find(nums,find_num)
五 编程范式
很多初学者在了解了一门编程语言的基本语法和使用之后,面对一个’开发需求‘时仍然会觉得无从下手、没有思路/套路,本节主题“编程范式”正是为了解决该问题,那到底什么是编程范式呢?
编程范式指的就是编程的套路,打个比方,如果把编程的过程比喻为练习武功,那编程范式指的就是武林中的各种流派,而在编程的世界里常见的流派有:面向过程、函数式、面向对象等,本节我们主要介绍前两者。
在正式介绍前,我们需要强调:“功夫的流派没有高低之分,只有习武的人才有高低之分“,在编程世界里更是这样,各种编程范式在不同的场景下都各有优劣,谁好谁坏不能一概而论,下面就让我们来一一解读它们
六面向过程编程
”面向过程“核心是“过程”二字,“过程”指的是解决问题的步骤,即先干什么再干什么......,基于面向过程开发程序就好比在设计一条流水线,是一种机械式的思维方式,这正好契合计算机的运行原理:任何程序的执行最终都需要转换成cpu的指令流水按过程调度执行,即无论采用什么语言、无论依据何种编程范式设计出的程序,最终的执行都是过程式的。
详细的,若程序一开始是要着手解决一个大的问题,按照过程式的思路就是把这个大的问题分解成很多个小问题或子过程去实现,然后依次调用即可,这极大地降低了程序的复杂度。举例如下:
写一个数据远程备份程序,分三步:本地数据打包,上传至云服务器,检测备份文件可用性
import os,time
# 一:基于本章所学,我们可以用函数去实现这一个个的步骤
# 1、本地数据打包
def data_backup(folder):
print("找到备份目录: %s" %folder)
print('正在备份...')
zip_file='/tmp/backup_%s.zip' %time.strftime('%Y%m%d')
print('备份成功,备份文件为: %s' %zip_file)
return zip_file
#2、上传至云服务器
def cloud_upload(file):
print("
connecting cloud storage center...")
print("cloud storage connected")
print("upload [%s] to cloud..." %file)
link='https://www.xxx.com/bak/%s' %os.path.basename(file)
print('close connection')
return link
#3、检测备份文件可用性
def data_backup_check(link):
print("
下载文件: %s , 验证文件是否无损..." %link)
#二:依次调用
# 步骤一:本地数据打包
zip_file = data_backup(r"/Users/egon/欧美100G高清无码")
# 步骤二:上传至云服务器
link=cloud_upload(zip_file)
# 步骤三:检测备份文件的可用性
data_backup_check(link)
面向过程总结:
1、优点
将复杂的问题流程化,进而简单化
2、缺点
'''
程序的可扩展性极差,因为一套流水线或者流程就是用来解决一个问题,就好比生产汽水的流水线无法生产汽车一样,即便是能,也得是大改,而且改一个组件,与其相关的组件可能都需要修改,比如我们修改了cloud_upload的逻辑,那么依赖其结果才能正常执行的data_backup_check也需要修改,这就造成了连锁反应,而且这一问题会随着程序规模的增大而变得越发的糟糕。
'''
def cloud_upload(file): # 加上异常处理,在出现异常的情况下,没有link返回
try:
print("
connecting cloud storage center...")
print("cloud storage connected")
print("upload [%s] to cloud..." %file)
link='https://www.xxx.com/bak/%s' %os.path.basename(file)
print('close connection')
return link
except Exception:
print('upload error')
finally:
print('close connection.....')
def data_backup_check(link): # 加上对参数link的判断
if link:
print("
下载文件: %s , 验证文件是否无损..." %link)
else:
print('
链接不存在')
3、应用场景
面向过程的程序设计一般用于那些功能一旦实现之后就很少需要改变的场景, 如果你只是写一些简单的脚本,去做一些一次性任务,用面向过程去实现是极好的,但如果你要处理的任务是复杂的,且需要不断迭代和维护, 那还是用面向对象最为方便。
七 函数式
7.1匿名函数与lambda
对比使用def关键字创建的是有名字的函数,使用lambda关键字创建则是没有名字的函数,即匿名函数,语法如下
lambda 参数1,参数2,...: expression
举例
# 1、定义
lambda x,y,z:x+y+z
#等同于
def func(x,y,z):
return x+y+z
# 2、调用
# 方式一:
res=(lambda x,y,z:x+y+z)(1,2,3)
# 方式二:
func=lambda x,y,z:x+y+z # “匿名”的本质就是要没有名字,所以此处为匿名函数指定名字是没有意义的
res=func(1,2,3)
匿名函数与有名函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放,所以匿名函数用于临时使用一次的场景,匿名函数通常与其他函数配合使用,我们以下述字典为例来介绍它
salaries={
'siry':3000,
'tom':7000,
'lili':10000,
'jack':2000
}
要想取得薪水的最大值和最小值,我们可以使用内置函数max和min(为了方便开发,python解释器已经为我们定义好了一系列常用的功能,称之为内置的函数,我们只需要拿来使用即可)
>>> max(salaries)
'tom'
>>> min(salaries)
'jack'
内置max和min都支持迭代器协议,工作原理都是迭代字典,取得是字典的键,因而比较的是键的最大和最小值,而我们想要的是比较值的最大值与最小值,于是做出如下改动
# 函数max会迭代字典salaries,每取出一个“人名”就会当做参数传给指定的匿名函数,然后将匿名函数的返回值当做比较依据,最终返回薪资最高的那个人的名字
>>> max(salaries,key=lambda k:salaries[k])
'lili'
# 原理同上
>>> min(salaries,key=lambda k:salaries[k])
'jack'
同理,我们直接对字典进行排序,默认也是按照字典的键去排序的
>>> sorted(salaries)
['jack', 'lili', 'siry', 'tom']
7.2map 、 reduce 、filter
函数map、reduce、filter都支持迭代器协议,用来处理可迭代对象,我们以一个可迭代对象array为例来介绍它们三个的用法
array=[1,2,3,4,5]
要求一:对array的每个元素做平方处理,可以使用map函数
map函数可以接收两个参数,一个是函数,另外一个是可迭代对象,具体用法如下
>>> res=map(lambda x:x**2,array)
>>> res
<map object at 0x1033f45f8>
>>>
解析:map会依次迭代array,得到的值依次传给匿名函数(也可以是有名函数),而map函数得到的结果仍然是迭代器。
>>> list(res) #使用list可以依次迭代res,取得的值作为列表元素
[1, 4, 9, 16, 25]
要求二:对array进行合并操作,比如求和运算,这就用到了reduce函数
reduce函数可以接收三个参数,一个是函数,第二个是可迭代对象,第三个是初始值
# reduce在python2中是内置函数,在python3中则被集成到模块functools中,需要导入才能使用
>>> from functools import reduce
>>> res=reduce(lambda x,y:x+y,array)
>>> res
15
解析:
1 没有初始值,reduce函数会先迭代一次array得到的值作为初始值,作为第一个值数传给x,然后继续迭代一次array得到的值作为第二个值传给y,运算的结果为3
2 将上一次reduce运算的结果作为第一个值传给x,然后迭代一次array得到的结果作为第二个值传给y,依次类推,知道迭代完array的所有元素,得到最终的结果15
也可以为reduce指定初始值
>>> res=reduce(lambda x,y:x+y,array,100)
>>> res
115
要求三:对array进行过滤操作,这就用到了filter函数,比如过滤出大于3的元素
>>> res=filter(lambda x:x>3,array)
解析:filter函数会依次迭代array,得到的值依次传给匿名函数,如果匿名函数的返回值为真,则过滤出该元素,而filter函数得到的结果仍然是迭代器。
>>> list(res)
[4, 5]
提示:我们介绍map、filter、reduce只是为了带大家了解函数式编程的大致思想,在实际开发中,我们完全可以用列表生成式或者生成器表达式来实现三者的功能。