一、前言
Elasticsearch 主要包含索引过程和搜索过程。
索引过程:一条文档被索引到 Elasticsearch 之后,默认情况下 ES 中会保存两份内容,一份是该文档的原始内容,也就是 _source 中共的文档内容,另一份是索引时通过分词、过滤等一系列过程生成的倒排索引文件,倒排索引中保存了词项和文档的对应关系。
搜索过程:当用户对文档进行检索时,ES 接收到查询关键词之后到倒排索引中进行查询,通过倒排索引中维护的倒排记录表找到关键词对应的文档集合,然后做评分、排序、高亮处理,最终返回搜索结果给用户。
二、搜索详解
Elasticsearch 提供 DSL(Domain Specific Language,特定领域语言)用来查询,官网文档地址为:Query DSL
2.1 基本检索
创建索引并设置 settings 和 mappings,如下:
PUT books { "settings": { "number_of_replicas": 1, "number_of_shards": 3 }, "mappings": { "IT": { "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "ik_max_word" }, "language": { "type": "keyword" }, "author": { "type": "keyword" }, "price": { "type": "double" }, "year": { "type": "date", "format": "yyyy-MM-dd" }, "description": { "type": "text", "analyzer": "ik_max_word" } } } } }
执行 bulk 批量导入命令把文档写入 Elasticsearch,如下:
curl -XPOST "http://192.168.56.110:9200/books/IT/_bulk?pretty" --data-binary @books.json
在 Kibana 的 Dev Tools 中执行 match_all query 查询 IT 下的全部数据,也可以去掉 IT 类型,查询 books 索引中的全部数据:
GET books/IT/_search { "query" : { "match_all" : {} } }
match_all query 可以简写如下:
GET books/IT/_search
以 term query 为例,介绍如何进行词项搜索、分页限制、返回指定字段、显示版本号、控制最小评分以及关键字的高亮。
2.1.1 词项搜索
term 查询用来查找指定字段中包含给定单词的文档,term 查询不被解析,只有查询词和文档中的词精确匹配才会被搜索到,应用场景为查询人名、地名等需要精确配备的需求。
GET books/_search { "query": { "term": { "title": { "value": "思想" } } } }
或者如下
GET books/_search { "query": { "term": { "title": "思想" } } }
2.1.2 分页限制
Elasticsearch 提供了结果分页的两个属性: from 和 size。from 指定返回结果的开始位置,默认值为 0,也就是从头开始返回文档,size 指定了一次返回结果所包含的最大文档数量,默认值为 10。size 的大小不能超过 index.max_result_window 这个参数的大小,该参数值默认为 10000,如果 size 需要大于10000,则需要首先修改 index.max_result_window 的参数大小。
GET books/_search { "from": 0, "size": 20, "query": { "term": { "title": { "value": "思想" } } } }
2.1.3 返回指定字段
默认情况下返回结果中包含了文档的所有字段信息,有时候为了简洁,只需要在查询结果中返回某些字段。例如查询标题 title 中包含关键字 java 的书籍,只返回 title 和 price 字段,如下:
GET books/IT/_search { "_source": ["title","price"], "query": { "term": { "title": { "value": "java" } } } }
2.1.4 显示版本号
默认情况下返回结果中不包含文档的版本号,当需要显示时,可以在查询体中设置 version 属性值为 true,如下:
GET books/IT/_search { "version": true, "query": { "term": { "title": { "value": "java" } } } }
2.1.5 控制最小评分
在查询体中添加 min_score 的最低评分数,只有评分超过这个分数的文档才会被返回,例如查询 title 中包含关键词 java 且文档评分不低于 0.8 的文档,如下:
GET books/IT/_search { "min_score": 0.8, "query": { "term": { "title": { "value": "java" } } } }
2.1.6 关键字高亮
GET books/_search { "query": { "term": { "title": "java思想" } }, "highlight": { "fields": { "title": {} } } }
返回结果如下:
{ "took": 64, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1.3862944, "hits": [ { "_index": "books", "_type": "IT", "_id": "1", "_score": 1.3862944, "_source": { "id": "1", "title": "Java编程思想", "language": "java", "author": "Bruce Eckel", "price": 70.2, "publish_time": "2007-10-01", "description": "Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。" }, "highlight": { "title": [ "<em>Java</em>编程<em>思想</em>" ] } }, { "_index": "books", "_type": "IT", "_id": "2", "_score": 0.9130229, "_source": { "id": "2", "title": "Java程序性能优化", "language": "java", "author": "葛一鸣", "price": 46.5, "publish_time": "2012-08-01", "description": "让你的Java程序更快、更稳定。深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法" }, "highlight": { "title": [ "<em>Java</em>程序性能优化" ] } } ] } }
2.2 全文查询
官方文档参考地址:Full text queries
The high-level full text queries are usually used for running full text queries on full text fields like the body of an email. They understand how the field being queried is analyzed and will apply each field’sanalyzer (or search_analyzer) to the query string before executing.
高级全文查询通常用于在全文字段(如电子邮件正文)上运行全文查询。通过全文查询理解如何分析被查询的字段,并在执行之前将每个字段分析器(或SaleChySalp分析仪)应用到查询字符串。
The standard query for performing full text queries, including fuzzy matching and phrase or proximity queries.
Like the match query but used for matching exact phrases or word proximity matches.
The poor man’s search-as-you-type. Like the match_phrase query, but does a wildcard search on the final word.
The multi-field version of the match query.
multi_match 是 match 的升级,用于搜素多个字段。比如查询语句为 "java编程",查询域为 title 和 description。
GET books/_search { "query": { "multi_match": { "query": "java思想", "fields": [ "title","description" ] } }, "highlight": { "require_field_match": false, "fields": { "title": {}, "description": {} } } }
A more specialized query which gives more preference to uncommon words.
Supports the compact Lucene query string syntax, allowing you to specify AND|OR|NOT conditions and multi-field search within a single query string. For expert users only.
A simpler, more robust version of the query_string syntax suitable for exposing directly to users.
以 match query 为例,match 查询会对查询语句进行分词,分词后查询语句中的任何一个词项被匹配,文档就会被搜索到,默认为 or。如果想查询匹配所有关键词的文档,可以用 and 操作符连接。
GET books/_search { "query": { "match": { "title": { "query": "java编程", "operator": "and" } } } }
2.3 词项查询
词项查询的官网文档地址为:Term level queries
While the full text queries will analyze the query string before executing, the term-level queries operate on the exact terms that are stored in the inverted index, and will normalize terms before executing only for keyword fields with normalizer property.
These queries are usually used for structured data like numbers, dates, and enums, rather than full text fields. Alternatively, they allow you to craft low-level queries, foregoing the analysis process.
上面的全文搜索在执行查询之前会分析查询字符串,词项搜索时对倒排索引中存储的词项进行精确操作。词项级别的查询通常用于结构化数据,如数字、日期和枚举类型。
词项查询
Find documents which contain the exact term specified in the field specified.
词项查询在上面已经演示过,此处不再讲解。
多词项查询
Find documents which contain any of the exact terms specified in the field specified.
terms 查询是 term 查询的升级,可以用来查询文档中包含多个词的文档。
GET books/_search { "query": { "terms": { "title": ["java", "python"] } } }
Find documents which match with one or more of the specified terms. The number of terms that must match depend on the specified minimum should match field or script.
区间查询
Find documents where the field specified contains values (dates, numbers, or strings) in the range specified.
range 查询用于匹配在某一范围内的数值型、日期型或者字符串类型字段的文档。比如想要查询加个大于50小于等于70的书籍,如下:
GET books/_search { "query": { "range": { "price": { "gt": 50, "lte": 70 } } } }
其中,gt 表示大于,gte 表示大于等于,lt 表示小于,lte 表示小于等于。
在 Kibana 的 Dev Tools 中可以输入多条 DSL 语句,如下:
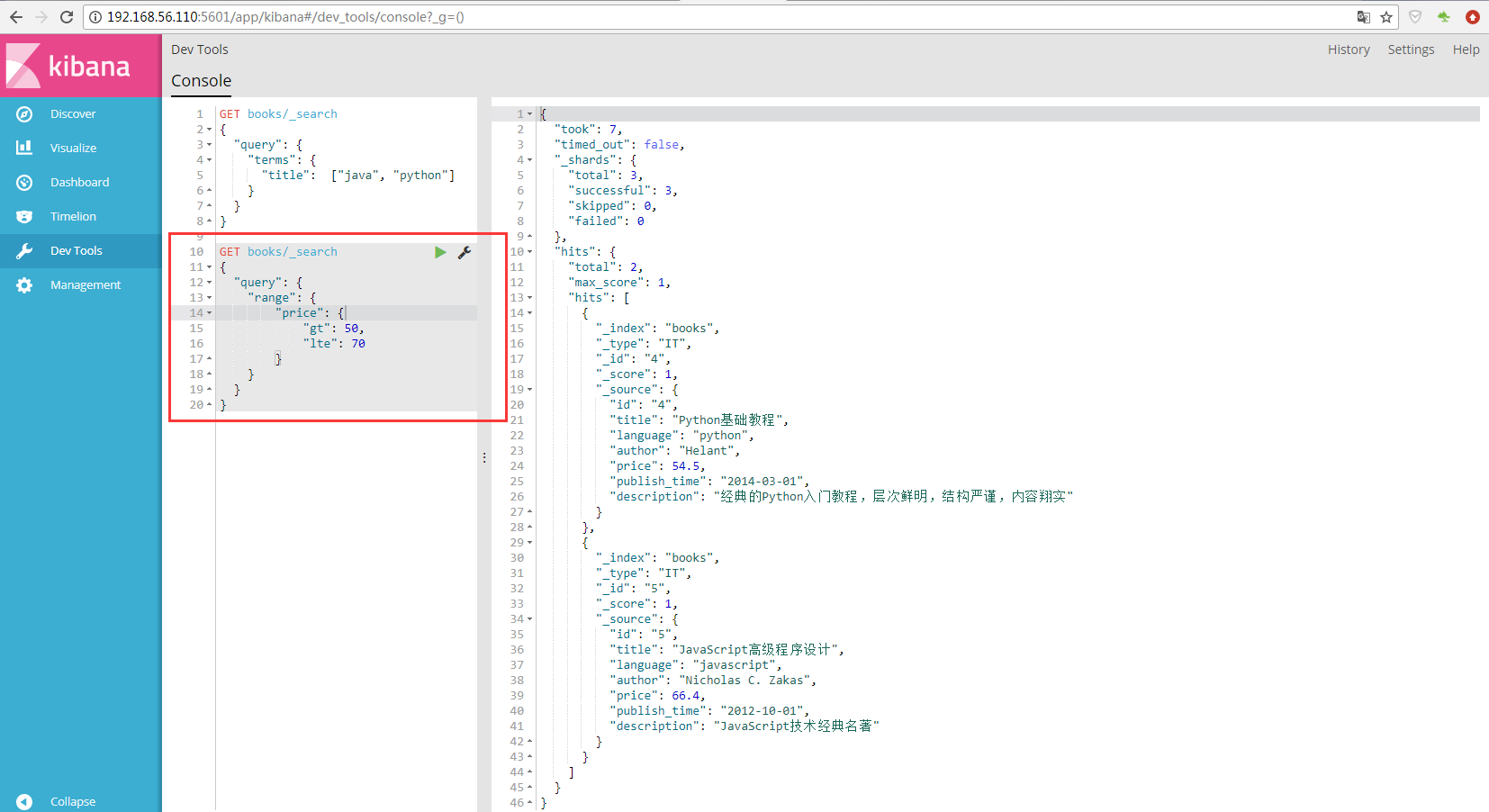
存在值查询
Find documents where the field specified contains any non-null value.
exists 查询会返回字段中至少有一个非空值的文档。
前缀查询
Find documents where the field specified contains terms which begin with the exact prefix specified.
prefix 查询用于查询某个字段中含有以给定前缀关键词的文档,如下:
GET books/_search { "query": { "prefix": { "description": "win" } } }
返回结果如下:
{ "took": 11, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 1, "hits": [ { "_index": "books", "_type": "IT", "_id": "3", "_score": 1, "_source": { "id": "3", "title": "Python科学计算", "language": "python", "author": "张若愚", "price": 81.4, "publish_time": "2016-05-01", "description": "零基础学python,光盘中作者独家整合开发winPython运行环境,涵盖了Python各个扩展库" } } ] } }
通配符查询
Find documents where the field specified contains terms which match the pattern specified, where the pattern supports single character wildcards (?) and multi-character wildcards (*).
查找指定的字段包含与指定的模式匹配的术语,其中模式支持单字符通配符(?)多字符通配符(*)。? 用来匹配一个任意字符,* 用来匹配零个或者多个字符。
GET books/_search { "query": { "wildcard": { "author": "张若*" } } }
正则表达式查询
Find documents where the field specified contains terms which match the regular expression specified.
GET books/_search { "query": { "regexp": { "author": "H[0-9a-zA-Z].+" } } }
如上,查找 author 字段中,以 H 开头,然后包含任意长度数字及大小写字母的作者名称。
模糊查询
Find documents where the field specified contains terms which are fuzzily similar to the specified term. Fuzziness is measured as a Levenshtein edit distance of 1 or 2.
如用户误将 "javascript" 输入成 "javascritp",也可以查询到文档。
类型查询
Find documents of the specified type.
type query 用于查询具有指定类型的文档。例如查询 Elasticsearch 中 type 为 IT 的文档,如下:
GET books/_search { "query": { "type": { "value": "IT" } } }
id 查询
Find documents with the specified type and IDs.
ids query 用于查询具有指定 id 的文档。类型是可选的,也可以省略。注意,此处的 id 指的是 _uid(Note, this query uses the _uid field)。
GET books/_search { "query": { "ids": { "type": "IT", "values": ["1", "3"] } } }
2.4 复合查询
复合查询官方文档地址:Compound queries
复合查询就是把一些简单查询组合在一起实现更复杂的查询需求,除此之外复合查询还可以控制另外一个查询的行为。
在这一组中包含的查询有:
常量评分查询
A query which wraps another query, but executes it in filter context. All matching documents are given the same "constant" _score.
如下查询 title 字段中包含 java 的文档,且设置所有文档的评分均为 1.2
GET books/_search { "query": { "constant_score": { "filter": { "term": { "title": "java" } }, "boost": 1.2 } } }
布尔查询
The default query for combining multiple leaf or compound query clauses, as must, should, must_not, or filter clauses. The must and should clauses have their scores combined — the more matching clauses, the better — while the must_not and filter clauses are executed in filter context.
bool 查询可以把任意多个简单查询组合在一起,使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,每个选项都可以出现0次到多次。filter 和 must 一样,但是 filter 不评分,只起到过滤作用。
GET books/_search { "query": { "bool": { "minimum_should_match": 1, "must": [ {"match": { "title": "java" }} ], "should": [ {"match": { "description": "虚拟机" }} ], "filter": { "term": { "title": "程序" } }, "must_not": { "range": { "price": {"gte": 70} } } } } }
A query which accepts multiple queries, and returns any documents which match any of the query clauses. While the bool query combines the scores from all matching queries, the dis_max query uses the score of the single best- matching query clause.
Modify the scores returned by the main query with functions to take into account factors like popularity, recency, distance, or custom algorithms implemented with scripting.
Return documents which match a positive query, but reduce the score of documents which also match a negative query.
boosting query 可将匹配的结果降级处理,包括三个部分:positive、nagative 和 negative_boost。
positive,包含所返回文档得分不会被改变的查询;
negative,返回的文档得分将被降低;
negative_boost,包含用来降低negative部分查询得分的加权值。
2.5 连接查询
Documents may contain fields of type nested. These fields are used to index arrays of objects, where each object can be queried (with the nested query) as an independent document.
文档中可能包含嵌套类型的字段。这些字段用于索引一些对象数组,其中可以将每个对象(以嵌套查询)查询为独立文档。
has_child and has_parent queries
A join field relationship can exist between documents within a single index. The has_child query returns parent documents whose child documents match the specified query, while the has_parent query returns child documents whose parent document matches the specified query.
父子关系可以存在单个的索引的两个类型的文档之间。has_child 查询将返回其子文档的能满组特定查询的父文档,而 has_parent 则返回其福文档能满足特定查询的子文档。
2.6 位置查询
Elasticsearch 支持两种类型的地理数据,可以对经纬度地理位置点 geo_point 类型和点、线、圆、多边形、多边形等地理位置形状 geo_shape 类型的数据进行搜索。
Find document with geo-shapes which either intersect, are contained by, or do not intersect with the specified geo-shape.
geo_shape query 用于查询 geo_shape 类型的地理数据,地理形状之间的关系有相交、包含、不想交三种。注意,在 geo_shape 类型中的点,是经度在前纬度在后。
Finds documents with geo-points that fall into the specified rectangle.
geo_bounding_box query 用于查找落入指定的矩形内的地理坐标。
Finds document with geo-points within the specified distance of a central point.
geo_distance query 可以查找一个中心点指定范围内的地理点文档。注意,在 geo_point 类型中的点,是纬度在前经度在后。例如,查找距离天津 200km 以内的城市,搜索结果中会返回北京,如下:
创建索引:
PUT /geos
{
"mappings": {
"city": {
"properties": {
"pin": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}
}
}
}
创建 geos.json 文档数据:
{"index":{ "_index": "geos", "_type": "city", "_id": "1" }}
{"pin":{"name":"北京","location":"39.9088145109,116.3973999023"}}
{"index":{ "_index": "geos", "_type": "city", "_id": "2" }}
{"pin":{"name":"乌鲁木齐","location":"43.8266300000,87.6168800000"}}
{"index":{ "_index": "geos", "_type": "city", "_id": "3" }}
{"pin":{"name":"西安","location":"34.3412700000,108.9398400000"}}
{"index":{ "_index": "geos", "_type": "city", "_id": "4" }}
{"pin":{"name":"郑州","location":"34.7447157466,113.6587142944"}}
{"index":{ "_index": "geos", "_type": "city", "_id": "5" }}
{"pin":{"name":"杭州","location":"30.2294080260,120.1492309570"}}
{"index":{ "_index": "geos", "_type": "city", "_id": "6" }}
{"pin":{"name":"济南","location":"36.6518400000,117.1200900000"}}
批量导入数据:
curl -XPOST "http://192.168.56.110:9200/_bulk?pretty" --data-binary @geos.json
查询:
GET geos/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"pin.location": {
"lat": 39.0851000000,
"lon": 117.1993700000
}
}
}
}
}
}
返回结果展示:
{
"took": 23,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "geos",
"_type": "city",
"_id": "1",
"_score": 1,
"_source": {
"pin": {
"name": "北京",
"location": "39.9088145109,116.3973999023"
}
}
}
]
}
}
Find documents with geo-points within the specified polygon.
geo_polygon_query 用于查找在指定多边形内的地理点。
2.7 特殊查询
This query finds documents which are similar to the specified text, document, or collection of documents.
此查询查找与指定文本、文档或文档集合相似的文档,通常用于近似文本的推荐等场景。
This query allows a script to act as a filter. Also see the function_score query.
使用脚本进行查询。
This query finds queries that are stored as documents that match with the specified document.
A query that accepts other queries as json or yaml string.
2.8 搜索高亮
在上面的演示中,我们知道 Elasticsearch 默认会用 <em></em>标签来标记关键字。
自定义高亮片段
如果我们想使用自定义标签,在高亮属性中给需要高亮的片段加上 pre_tags 和 post_tags 即可。
##自定义高亮 GET books/_search { "query": { "match": { "title": "java思想" } }, "highlight": { "fields": { "title": { "pre_tags": ["<strong>"], "post_tags": ["</strong>"] } } } }
返回结果如下:
{ "took": 47, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1.3862944, "hits": [ { "_index": "books", "_type": "IT", "_id": "1", "_score": 1.3862944, "_source": { "id": "1", "title": "Java编程思想", "language": "java", "author": "Bruce Eckel", "price": 70.2, "publish_time": "2007-10-01", "description": "Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。" }, "highlight": { "title": [ "<strong>Java</strong>编程<strong>思想</strong>" ] } }, { "_index": "books", "_type": "IT", "_id": "2", "_score": 0.9130229, "_source": { "id": "2", "title": "Java程序性能优化", "language": "java", "author": "葛一鸣", "price": 46.5, "publish_time": "2012-08-01", "description": "让你的Java程序更快、更稳定。深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法" }, "highlight": { "title": [ "<strong>Java</strong>程序性能优化" ] } } ] } }
多字段高亮
比如在搜索 title 字段的时候,我们期望 description 字段中的关键字也高亮显示,这时需要把 require_field_match 属性的取值设置为 false。require_field_match 属性的默认值为 true,只会高亮显示匹配的字段。多字段高亮如下:
##多字段高亮 GET books/_search { "query": { "match": { "title": "java思想" } }, "highlight": { "require_field_match": false, "fields": { "title": {}, "description": {} } } }
返回结果如下:
{ "took": 29, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1.3862944, "hits": [ { "_index": "books", "_type": "IT", "_id": "1", "_score": 1.3862944, "_source": { "id": "1", "title": "Java编程思想", "language": "java", "author": "Bruce Eckel", "price": 70.2, "publish_time": "2007-10-01", "description": "Java学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。" }, "highlight": { "description": [ "<em>Java</em>学习必读经典,殿堂级著作!赢得了全球程序员的广泛赞誉。" ], "title": [ "<em>Java</em>编程<em>思想</em>" ] } }, { "_index": "books", "_type": "IT", "_id": "2", "_score": 0.9130229, "_source": { "id": "2", "title": "Java程序性能优化", "language": "java", "author": "葛一鸣", "price": 46.5, "publish_time": "2012-08-01", "description": "让你的Java程序更快、更稳定。深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法" }, "highlight": { "description": [ "让你的<em>Java</em>程序更快、更稳定。深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法" ], "title": [ "<em>Java</em>程序性能优化" ] } } ] } }
多种高亮器性能分析
查看高亮器官网文档:Highlighting
Elasticsearch 提供了三种高亮器,分别是默认的 highlighter 高亮器、postings-highlighter 高亮器和 fast_vector_highlighter 高亮器。
默认的 highlighter 是最基本的高亮器。highlighter 高亮器实现高亮功能需要对 _source 中保存的原始文档进行二次分析,其速度在三种高亮器里面最慢,优点是不需要额外的存储空间。
postings-highlighter 高亮器实现高亮功能不需要二次分析,但是需要在字段的映射中设置 index_options 参数的取值为 offsets,即保存关键词的偏移量,速度快于默认的 highlighter 高亮器。
PUT /example { "mappings": { "doc": { "properties": { "comment": { "type": "text", "index_options": "offsets" } } } } }
fast_vector_highlighter 高亮器实现高亮功能速度最快,但是需要在字段的映射中设置 term_vector 参数的取值为 with_positions_offsets,即关键词的位置和偏移信息,占用的存储空间最大,是典型的空间换时间的做法。
PUT /example { "mappings": { "doc": { "properties": { "comment": { "type": "text", "term_vector": "with_positions_offsets" } } } } }
2.9 搜索排序
默认排序
Elasticsearch 是按照查询和文档的相关度进行排序的,默认按评分降序排序,如下:
##默认排序 GET books/_search { "query": { "term": { "title": "java" } } }
等价于:
##默认排序 GET books/_search { "query": { "term": { "title": "java" } }, "sort": [ {"_score": {"order": "asc"}} ] }
对于 match_all query 而言,由于只返回所有文档,不需要评分,文档的顺序为添加文档的顺序。
通过 size 属性设置返回的文档条数,如下:
##只取top-10 GET books/_search { "size": 10, "query": { "term": { "title": "java" } } }
多字段排序
和 SQL 类型,Elasticsearch 也支持多字段排序。例如先按价格降序排序,价格相等的按照出版年份升序排序,如下:
##多字段排序 GET books/_search { "sort": [ {"price": {"order": "desc"}}, {"year": {"order": "asc"}} ] }