- 1.C++与C的差异
- 1.15 动态申请内存耗尽
- 1.20 const
- 1.21 判断系统是多少位系统
- 1.33 virtual 是如何实现多态的?
- 1.34 面向对象三大特性
- 1.35 重载 ,重写 ,重定义
- 1.36 一个空类的对象占的字节数
- 1.37 内联函数是否参数检查
- 1.38 析构函数与虚函数
- 1.40 c++模板编程的理解
- 1.41 函数模板与类模板
- 1.41 运算符重载
- 1.42 基类的析构函数为什么必须是虚函数?
- 1.43 c++的左值与右值
- 1.44 数组名是指针,指向数组中第一个元素
- 1.45 计算机字长与指针所占存储空间的大小
- 1.46 构造函数
- 1.47 常见的排序方式
- 1.48 c/c++程序的内存分配
- 1.49
- 1.5 对于return 语句的理解
- 1.51 拷贝构造函数与return
- 1.52 操作符号的优先级
- 1.53 位运算
- 1.54 编写算法统计输入字符串中不同字符出现的频率
- 1.60 设计模式
- 1.61
- 1.62 字符串逆序
- 1.63 统计一个输入字符串中中不同字符出现的频率
- 1.64 假设以数组sequ[m]存放循环队列的元素,同时设变量rear和quelen分别指示循环队列中的队尾元素的位置和队列中内含元素的个数,试给出判别次循环队列中的堆满条件,并写出相应的入队和出队的算法;(这个是数据结果)
- 1.64 十六进制数转十进制数
- 1.65 假设以数组Q[m]存放循环队列中的元素,同时以rear和length分别指示环形队列中的队
- 1.66 递归求和以及求均值
- 1.66 已知head为单链表的表头指针,链表中存储的都是整型数据,实现下列运算的算法:(1) 求链表中的最大值(2)求链表中的结点个数(3)求所有整数的平均值
1.C++与C的差异
1.1 C与c++中的struct的差异
a. C++语言将struct当成类来处理的,所以C++的struct可以包含C++类的所有东西,例如构造函数,析构函数,友元等,C++的struct和C++类唯一不同就是 struct成员默认的是public, C++默认private。
b. 由于C++中的struct是抽象数据类型,所以可以继承也可以实现多态,只是因为有了class 一般不用它。
c. C语言struct不是类,不可以有函数,也不能使用类的特征例如public等关键字 ,是一些变量的集合体,可以封装数据却不可以隐藏数据。
d. +C语言中:struct是用户自定义数据类型(UDT);C++中struct是抽象数据类型(ADT),所以下面代码:
struct HE a; //C语言 变量方式
HE a; //C++语言 变量
1.2 C++中class与struct的区别与联系
a. 默认访问权限不同,C++中的class成员的默认属性是private ,而struct默认属性是public。
b.struct 可以定义相应结构所需的成员函数以及成员变量以及函数,可以有private ,public属性,protected 属性。
d.使用场景:.1,从此后只使用 class 定义类(一般的); 2,struct 只用来表示变量的集合(一般的),代表一个结构体;
c。使用方式:C++ 中的类支持声明和实现的分离,意义在于分两个角度来看待类,一个是声明的角度、一个是实现的角度: 1,在头文件中声明 1,类的使用方式; 2,在源文件中实现类; 1,类的实现细节;
1.3如何判断一段程序是c++还是c编译的?
#ifdef __cplusplus
cout<<"c++";
#else
cout<<"c";
#endif
1.4 c与c++ 不同之处
a. C是一种面向过程的语言。
b。c++是面向对象的程序语言。其具有封装,继承,多态等面向对象的特性。
1.5 指针与引用的区别
a. 指针是本身存储的所指向的对象的地址,而引用只是引用对象的别名。通过sizeof可以获取指针的存储空间的大小,而sizeof引用的话获取的引用对象的存储空间的大小。
b.指针在初始化可为空,指针指向的对象可以改变,而引用则不能为空,必须和引用对象绑定,而且之后不能改变。
1.6 sizeof
int id(sizeof(unsigned long))
1.7 static 的作用域
某一个文件中定义的静态的变量,则它的作用域是整个文件。与之相对的的是extern
在a.h的头文件中定义了一个静态的全局变量x,不同文件的函数fun1和fun3会为每个包含该头文件的cpp都创建一个全局变量,但他们都是独立的,只在该cpp文件共享该变量。所以一般定义static全局变量时,都把它放在原文件中而不是头文件,从而避免多个源文件共享,就不会给其他模块造成不必要的信息污染。
1.8 c++ 中值传递的三种方式
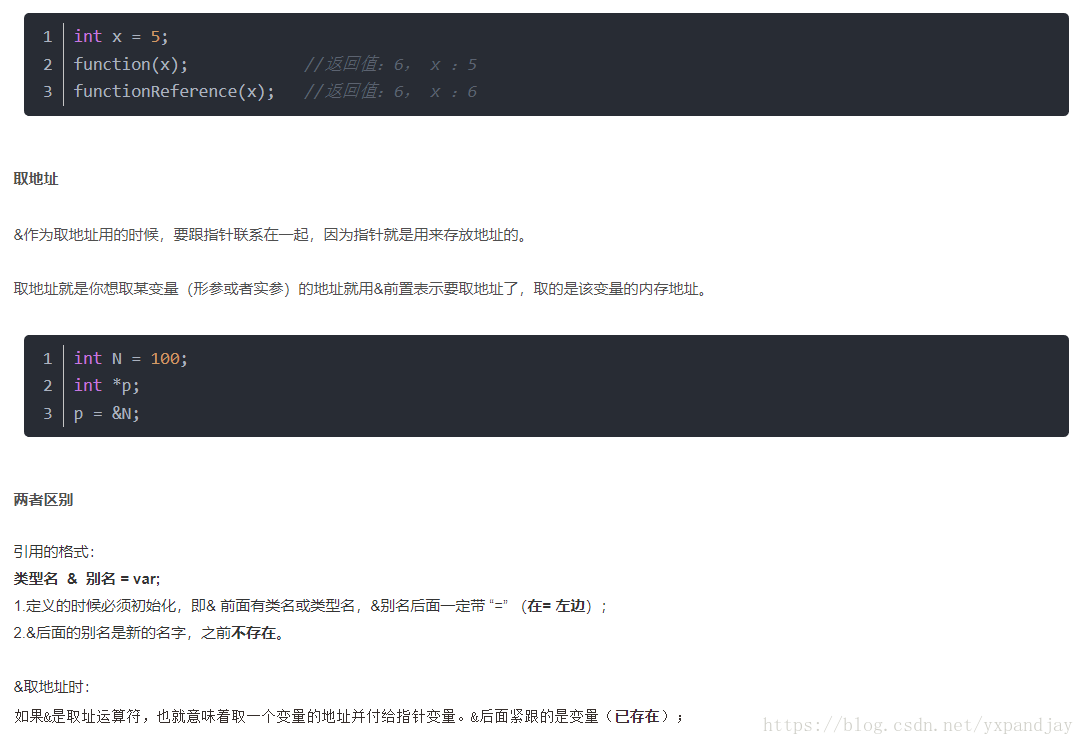
1.9 inline 函数
inline函数仅仅是一个对编译器的建议,所以最后能否真正内联,看编译器的意思,它如果认为函数不复杂,能在调用点展开,就会真正内联,并不是说声明了内联就会内联,声明内联只是一个建议而已。
1.10 virtual与inline

1.11 Debug和Release的区别
Debug:调试版本,包括调试信息,所以其容量一般来说比Release大很多,并且不进行任何的优化(优化会使得调试信息复杂化,因为源代码和生成的指令之间关系会更复杂),以便于程序员进行调试。
Debug模式下生成两个文件:除了.exe或者.dll文件外,还有一个.pdb文件,该文件记录了代码中断点等调试信息。
Release:发布版本,不对源代码进行调试,编译时对应用程序的速度进行优化,使得程序在代码大小和运行速度上都是最优的(调试信息可以在单独的PDB文件中生成)。
Release模式下生成一个文件.exe或.dll文件
1.12 assert
assert的作用是先计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行。
用法总结与注意事项:
1)在函数开始处检验传入参数的合法性
2)每个assert只检验一个条件,因为同时检验多个条件时,如果断言失败,无法直观的判断是哪个条件失败
3)不能使用改变环境的语句,因为assert只在DEBUG个生效,如果这么做,会使用程序在真正运行时遇到问题,
4)assert和后面的语句应空一行,以形成逻辑和视觉上的一致感。
5)有的地方,assert不能代替条件过滤。
assert是用来避免显而易见的错误的,而不是处理异常的。一个非常简单的使用assert的规律就是,在方法或者函数的最开始使用,如果在方法的中间使用则需要慎重考虑是否是应该的。方法的最开始还没开始一个功能过程,在一个功能过程执行中出现的问题几乎都是异常。
1.13 const 与#define

1.14 malloc/free 与 new delete
前者是c语言的库函数,后者是c++运算符号
1.15 动态申请内存耗尽

1.20 const
const 放在函数后样的函数叫常成员函数。常成员函数可以理解为是一个“只读”函数,它既不能更改数据成员的值,也不能调用那些能引起数据成员值变化的成员函数,只能调用const成员函数。
修饰变量,说明该变量不可以被改变;
修饰指针,分为指向常量的指针和指针常量;
常量引用,经常用于形参类型,即避免了拷贝,又避免了函数对值的修改;
修饰成员函数,说明该成员函数内不能修改成员变量。
// 类
class A { private: const int a; // 常对象成员,只能在初始化列表赋值
public:
// 构造函数
// 类
class A
{
private:
const int a; // 常对象成员,只能在初始化列表赋值
public:
// 构造函数
A() : a(0) { };
A(int x) : a(x) { }; // 初始化列表
// const可用于对重载函数的区分
int getValue(); // 普通成员函数
int getValue() const; // 常成员函数,不得修改类中的任何数据成员的值
};
void function()
{
// 对象
A b; // 普通对象,可以调用全部成员函数、更新常成员变量
const A a; // 常对象,只能调用常成员函数
const A *p = &a; // 常指针
const A &q = a; // 常引用
// 指针
char greeting[] = "Hello";
char* p1 = greeting; // 指针变量,指向字符数组变量
const char* p2 = greeting; // 指针变量,指向字符数组常量
char* const p3 = greeting; // 常指针,指向字符数组变量
const char* const p4 = greeting; // 常指针,指向字符数组常量
}
// 函数
void function1(const int Var); // 传递过来的参数在函数内不可变
void function2(const char* Var); // 参数指针所指内容为常量
void function3(char* const Var); // 参数指针为常指针
void function4(const int& Var); // 引用参数在函数内为常量
// 函数返回值
const int function5(); // 返回一个常数
const int* function6(); // 返回一个指向常量的指针变量,使用:const int *p = function6();
int* const function7(); // 返回一个指向变量的常指针,使用:int* const p = function7();
1.21 判断系统是多少位系统
定义一个指针,并通过sizeof计算指针占的字节数
#define OS_BITS (((int)((ptrdiff_t *)0 + 1)) << 3)
1.22

1.23

1.24 实参与形参

1.25 计算精度误差

1.26 堆和栈
1.heap是堆,stack是栈。
2.stack的空间由操作系统自动分配和释放,heap的空间是手动申请和释放的,heap常用new关键字来分配。
3.stack空间有限,heap的空间是很大的自由区。
1.27 explicit与protected
explicit关键字只需用于类内的单参数构造函数前面。由于无参数的构造函数和多参数的构造函数总是显示调用,这种情况在构造函数前加explicit无意义。 google的c++规范中提到explicit的优点是可以避免不合时宜的类型变换,缺点无。所以google约定所有单参数的构造函数都必须是显示的,只有极少数情况下拷贝构造函数可以不声明称explicit。例如作为其他类的透明包装器的类。 effective c++中说:被声明为explicit的构造函数通常比其non-explicit兄弟更受欢迎。因为它们禁止编译器执行非预期(往往也不被期望)的类型转换。除非我有一个好理由允许构造函数被用于隐式类型转换,否则我会把它声明为explicit,鼓励大家遵循相同的政策
1.28 浅拷贝与内存泄漏 ,深拷贝
1.30 数组名作为参数与int 作为参数的区别

1.31 程序的可读性与可维护性-变量

1.32 const 的用法

1.33 virtual 是如何实现多态的?

1.34 面向对象三大特性

1.35 重载 ,重写 ,重定义

1.36 一个空类的对象占的字节数

1.37 内联函数是否参数检查

1.38 析构函数与虚函数
析构函数是特殊的类函数,没有返回类型,没有参数,不能随意调用,也没有重载。在类对象生命期结束的时候,由系统自动调用释放在构造函数中分配的资源。这种在运行时,能依据其类型确认调用那个函数的能力称为多态性,或称迟后联编。另: 析构函数一般在对象撤消前做收尾工作,比如回收内存等工作
)在基类用virtual声明成员函数为虚函数,这样便可以在派生类中重新定义该函数,
2)在派生类中重新定义此函数,要求函数名、函数类型、函数参数个数和类型全部与基类的虚函数相同,并根据派生类的需要重新定义函数体;
3)定义一个指向基类对象的指针变量,并使得它指向同一类中需要调用函数的对象
4)通过该指针可调用此虚函数,此时调用的就是指针变量指向的对象同名函数。通过虚函数与指向基类对象的指针变量的配合使用。就能方便调用同一类族种不同的类的同名函数,只要先用基类指针指向即可。

1.40 c++模板编程的理解

1.41 函数模板与类模板

1.41 运算符重载
1.42 基类的析构函数为什么必须是虚函数?




1.43 c++的左值与右值
左值:用的是对象的身份
右值:用的是对象的值(内存)
decltype:当其作用于表达式时,如果求值结果是左值,那么返回一个引用
如果求值结果是右值,那么返回正常
int*p =new int(3);
int m = 3;
int &q = m;
decltype(p) dclp; //解引用运算生成左值,所以结果是int&
decltype(&q) dclq; //取地址生成右值
左值必须为常量
1.44 数组名是指针,指向数组中第一个元素
//一般ADarray是数组名,也就是数组首地址,i是偏移量,所以上面这个表达式也就是数组第i个元素的值
unsigned short array[] = { 1,2,3,4,5,6,7 };
int i = 3;
cout << *(array + i);
1.45 计算机字长与指针所占存储空间的大小
机器字长是指计算机进行一次整数运算所能处理的二进制数据的位数(整数运算即定点整数运算)。因为计算机中数的表示有定点数和浮点数之分,定点数又有定点整数和定点小数之分,这里所说的整数运算即定点整数运算。机器字长也就是运算器进行定点数运算的字长,通常也是CPU内部数据通路的宽度。
1.46 构造函数

1.47 常见的排序方式
1.48 c/c++程序的内存分配
一、一个C/C++编译的程序占用内存分为以下几个部分:
栈区(stack):由编译器自动分配与释放,存放为运行时函数分配的局部变量、函数参数、返回数据、返回地址等。其操作类似于数据结构中的栈。
堆区(heap):一般由程序员自动分配,如果程序员没有释放,程序结束时可能有OS回收。其分配类似于链表。
全局区(静态区static):存放全局变量、静态数据、常量。程序结束后由系统释放。全局区分为已初始化全局区(data)和未初始化全局区(bss)。
常量区(文字常量区):存放常量字符串,程序结束后有系统释放。
代码区:存放函数体(类成员函数和全局区)的二进制代码。
1.49
a++是先赋值后运算的。也就是说a++在这里a还是原来的数,++a就是后赋值的得出在1的基础上加1结果为2
1.5 对于return 语句的理解

1.51 拷贝构造函数与return

1.52 操作符号的优先级
输出操作符号的优先级别高于条件操作符号

1.53 位运算
1.54 编写算法统计输入字符串中不同字符出现的频率
注意防错
输入变量字符串
输出欸一个字符出现的频率 指针数组
1.60 设计模式
1.61
1.62 字符串逆序
char a[50];
cout << "please input a string:";
cin >> a;
int k = 0;
k = strlen(a);
cout << "Reverse order: ";
for (; k >= 0; k--) {
cout << a[k];
}
cout << endl;
return 0;
1.63 统计一个输入字符串中中不同字符出现的频率
#include <vector>
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main()
{
map<char, int> m_Count;
string str;
cout << "请输入字符串!!" << endl;
getline(cin, str);
//相当于字典
for (size_t i = 0; i < str.size(); ++i)
{
m_Count[str[i]]++;
}
map<char, int>::iterator iter;
for (iter = m_Count.begin(); iter != m_Count.end(); ++iter)
{
cout << iter->first << ":" << iter->second << endl;
}
return 0;
}
1.64 假设以数组sequ[m]存放循环队列的元素,同时设变量rear和quelen分别指示循环队列中的队尾元素的位置和队列中内含元素的个数,试给出判别次循环队列中的堆满条件,并写出相应的入队和出队的算法;(这个是数据结果)
(rear+1)%m == (rear-quelen+m)%m
入队算法
void EnQueue(ElemType sequ[], ElemType value)
{
if((rear+1)%m == (rear-quelen+m)%m)
{
printf("队列满!");
return;
}
rear = (rear+1)%m;
sequ[rear] = value;
quelen++;
}
出队算法
void DeQueue(ElemType sequ[], ElemType *value)
{
if(quelen == 0)
{printf("队列空!");
return;
}
*value = sequ[rear];
rear = (rear-1+m)%m;quelen--;
}
1.64 十六进制数转十进制数
//编写一个函数,函数接收一个字符串, 是由十六进制数组成的一组字符串,
//函数的功能是把接到的这组字符串转换成十进制数字.并将十进制数字返回
#include <iostream>
using namespace std;
// 十六进制字符串的最大长度
#define MAX_HEX_STR_LEN 8
bool hexToDec(char shex[], int & idec)
{
size_t i = 0, len = 0;
int mid = 0;
len = strlen(shex);
if (len > MAX_HEX_STR_LEN) {
return false;
}
idec = 0;
for (i = 0; i < len; i++) {
mid = 0;
if (shex[i] >= '0' && shex[i] <= '9') {
mid = shex[i] - '0';
}
else if (shex[i] >= 'a' && shex[i] <= 'f') {
mid = shex[i] - 'a' + 10;
}
else if (shex[i] >= 'A' && shex[i] <= 'F') {
mid = shex[i] - 'A' + 10;
}
else {
return false;
}
// 移位表示变为2的n次方倍
mid <<= ((len - i - 1) << 2);
idec += mid;
}
return true;
}
1.65 假设以数组Q[m]存放循环队列中的元素,同时以rear和length分别指示环形队列中的队
1.66 递归求和以及求均值
#include<iostream>
using namespace std;
int get_array_max(int arr[], int n)
{
if (n == 1) {
return arr[0];
}
else {
return arr[n - 1] > get_array_max(arr, n - 1) ? arr[n - 1] :
get_array_max(arr, n - 1);
}
}
int get_array_max(int arr[], int n) {
if (n == 1) {
return arr[0];
}
else {
return arr[n - 1] < get_array_max(arr, n - 1) ? arr[n - 1] :
get_array_max(arr, n - 1);
}
}
int get_array_sum(int arr[], int n, int step) {
if (step == n) {
return 0;
}
return arr[step] + get_array_sum(arr, n, step + 1);
}
int main()
{
int arr[4] = { 1,3,4,5 };
int max=get_array_max(arr, 4);
}
1.66 已知head为单链表的表头指针,链表中存储的都是整型数据,实现下列运算的算法:(1) 求链表中的最大值(2)求链表中的结点个数(3)求所有整数的平均值
#include<iostream>
#include<algorithm>
using namespace std;
class ListNode
{
public:
int val;
ListNode* next;
ListNode(int x) : val(x), next(NULL) {}
};
class Solution {
public:
//f(n)=max(f(n-1),an)
int getMax(ListNode* head, int Max)
{
if (head == NULL)
{
return Max;
}
else
{
return max(getMax(head->next, Max), head->val);
}
}
//f(n)=f(n-1)+1
int getSize(ListNode* head)
{
if (head == NULL)
{
return 0;
}
else
{
return(getSize(head->next) + 1);
}
}
//f(n)=(f(n-1)*(n-1)+an)/n
float getAverage(ListNode* head,int n)
{
if (head == NULL)
return 0;
else
{
return (float)(getAverage(head->next,n-1) * (n - 1) + head->val) / n;
}
}
};