在多核编程中一直会存在一个问题: 多核cpu 抢占一个资源??
为什么会出现这样的情况呢?说白了就是资源是共享的!!
所以在多核编程设计过程中 一般都是少用global全局变量多用局部local 变量
或者说需要考虑cache 的一致性
- 自旋锁,不休眠,无进程上下文切换开销,可以用在中断上下文和临界区小的场合;
- 信号量,会休眠,支持同时多个并发体进入临界区,可以用在可能休眠或者长的临界区的场合;
- 互斥量,类似与信号量,但只支持同时只有一个并发体进入临界区;
- 读写锁,支持读并发,写写/读写间互斥,读会延迟写,对读友好,适用读侧重场合;
- 顺序锁,支持读并发,写写/读写间互斥,写会延迟读,对写友好,适用写侧重场合;
锁技术虽然能有效地提供并行执行下的竞态保护,但锁的并行可扩展性很差,无法充分发挥多核的性能优势
原子技术
原子技术主要是解决cache和内存不一致性和乱序执行对原子访问的破坏问题。Linux kernel中主要的原子原语有:
- ACCESS_ONCE()、READ_ONCE() and WRITE_ONCE():禁止编译器对数据访问的优化,强制从内存而不是缓存中获取数据;
- barrier():乱序访问内存屏障,限制编译器的乱序优化;
- smb_wmb():写内存屏障,刷新store buffer,同时限制编译器和CPU的乱序优化;
- smb_rmb():读内存屏障,刷新invalidate queue,同时限制编译器和CPU的乱序优化;
- smb_mb():读写内存屏障,同时刷新store buffer和invalidate queue,同时限制编译器和CPU的乱序优化;
- atomic_inc()/atomic_read()等:整型原子操作;
kernel作为系统软件,实现受硬件影响很大,不同硬件有不同的内存模型,因此,不同于高级语言,Linux kernel的原子原语语义并没有一个统一模型。
比如在SMP的ARM64 CPU上,barrier、smb_wmb、smb_rmb的实现与smb_mb都是一样的,都是volatile ("" ::: "memory")。
atomic_inc()原语为了保证原子性,需要对cache进行刷新,而缓存行在多核体系下传播相当耗时,其多核下的并行性能可能有点差。
无锁技术
原子技术,是无锁技术中的一种,除此之外,无锁技术还包括RCU Hazard pointer 无锁队列 kfifio 等。值得一提的是,这些无锁技术都基于内存屏障实现的
- 1、Hazard pointer主要用于对象的生命周期管理,类似引用计数,但比引用计数有更好的并行可扩展性;内存回收问题是如何允许被删除节点的内存被释放,同时还保证没有线程访问被释放的内存,以及如何以一种无锁的方式做到这一点,之前的方法有:无锁引用计数、线程的时间戳方法
无锁算法中释放内存的难点在于当线程释放了一块内存后,是无法获知是否有别的线程也同时持有该块内存的指针并需要访问!!
因此解决这个难点的一个直接想法就是,在每个线程获取了一个关键内存的指针后,该线程将设置一个标志,表明"我正在操作这个关键数据,你们谁都别给我随便就释放了"。当然,这个标志需要放在一个公共区域,使得任何线程都可以去读。当另一个线程想要释放一块内存时,它就去把每个线程的标志都看一下,看看是否有别的线程也在操作这块内存,从而决定是否马上释放该内存:如果有别的线程在操作该内存,则暂时不释放,等下次。
- 建立一个全局数组 HP hp[N],数组中的元素为指针,称为 Hazard pointer,数组的大小为线程的数目,即每个线程拥有一个 HP。
- 约定每个线程只能修改自己的 HP,而不允许修改别的线程的 HP,但可以去读别的线程的 HP 值。
- 当线程尝试去访问一个关键数据节点时,它得先把该节点的指针赋给自己的 HP,即告诉别人不要释放这个节点。
- 每个线程维护一个私有链表(free list),当该线程准备释放一个节点时,把该节点放入自己的链表中,当链表数目达到一个设定数目 R 后,遍历该链表把能释放的节点通通释放。
- 当一个线程要释放某个节点时,它需要检查全局的 HP 数组,确定如果没有任何一个线程的 HP 值与当前节点的指针相同,则释放之,否则不释放,仍旧把该节点放回自己的链表中。
HP 算法主要用在实现无锁的队列上,因此前面的具体步骤其实基于以下几个假设:
- 队列上的元素任何时候,只可能被其中一个线程成功地从队列上取下来,因此每个线程的 free list 中的元素肯定是唯一的。
- 线程在操作无锁队列时,任何时候基本只需要处理一个节点,因此每个线程只需要一个 HP 就够了,如果有特殊需求,当然 HP 的数目也可以相应扩展。
- 对于某个节点来说,多个线程同时持有该节点的指针这个现象,在时间上是非常短暂有限的,只有当这几个线程同时尝试去取下该节点,它们才可能同时持有该节点的指针,一旦某个线程成功地将节点取下,其它线程很快就会发现,并尝试继续去操作下一下节点,而后续再来取节点的线程则不再可能获得已经不在无琐队列上的节点的指针,因此:当某个线程尝试去检查其它线程的 HP 时,它只需要将 HP 数组遍历一遍就够了,不用担心各线程 HP 值的变化。
关于Hazard pointer 目前用的比较少 就不研究了!! 上述为网络转载
- 2、RCU适用的场景很多,其可以替代:读写锁、引用计数、垃圾回收器、等待事物结束等,而且有更好的并行扩展性。RCU也有一些不适用的场景,如写侧重;临界区长;临界区内休眠等场景。
无锁原语也只能解决读端的并行可扩展性问题,写端的并行可扩展性只能通过数据分割技术来解决, 也就是减少竞争资源的粒度
数据分割
分割数据结构,减少共享数据,是解决并行可扩展性的根本办法。对分割友好(即并行友好)的数据结构有
- 数组
- 哈希表
- 基树(Radix Tree)/稀疏数组
- 跳跃列表(skip list)
除了使用合适的数据结构外,合理的分割指导规则也很重要:
- 读写分割:以读为主的数据与以写为主的数据分开;
- 路径分割:按独立的代码执行路径来分割数据;
- 专项分割:把经常更新的数据绑定到指定的CPU/线程中;
- 所有权分割:按CPU/线程个数对数据结构进行分割,把数据分割到per-cpu/per-thread中;
per-cpu 以及raidx-tree
per-cpu根据CPU的个数,在内存中生成多份拷贝,并且能够根据变量名和CPU编号,正确的对各个CPU的变量进行寻址
per-cpu 创建时在每个cpu上都有一份拷贝,这样cpu在存取自己的percpu变量时无需考虑多核上的并发问题,只需考虑本cpu上的并发即可(如本地cpu中断),当然还要保证当前task在存取percpu变量时不能被调度到其他cpu上;
内核会为每个cpu分配用于内核静态percpu变量的static区域、用于分配模块静态percpu变量的reserved区域以及第一块用于分配动态percpu变量的dynamic区域。
获取当前cpu的percpu变量的接口中(get_cpu_var和get_cpu_ptr宏),会禁止当前cpu的抢占(ps spinlock 也会disable 抢占)以防止当前task在存取percpu变量的过程中被迁移到其他cpu上,因此在使用完percpu变量后,需要调用相关接口(put_cpu_var和put_cpu_ptr宏)开启当前cpu抢占
定义的静态percpu变量会被放到percpu相关的section中,如.data..percpu ,这些section定义如下: /* 传入的cacheline为L1_CACHE_BYTES,即与L1 cacheline size对齐,以此解决伪共享问题 */ #define PERCPU_INPUT(cacheline) __per_cpu_start = .; *(.data..percpu..first) . = ALIGN(PAGE_SIZE); *(.data..percpu..page_aligned) . = ALIGN(cacheline); *(.data..percpu..read_mostly) . = ALIGN(cacheline); *(.data..percpu) *(.data..percpu..shared_aligned) PERCPU_DECRYPTED_SECTION __per_cpu_end = .; 这些原始静态percpu变量位置处于__per_cpu_start和__per_cpu_end地址之间
内核模块中使用静态percpu的方法与内核中一模一样,但为何实现方法不同呢?
模块中定义的静态percpu变量在编译后存在与ko文件的percpu相关section中:
percpu_test.ko: file format elf64-littleaarch64 -- 8 .data..percpu 00000004 0000000000000000 0000000000000000 0000043c 2**2 CONTENTS, ALLOC, LOAD, DATA
在使用insmod等工具将该模块动态加载到内核中运行时,不可能插入到内核静态的percpu相关section中,因为这些section位于init数据段,在内核初始化完成后会被回收;就算能插入到section中,也错过了拷贝流程(数据段copy到ram中)。
因此,在percpu初始化阶段,会模块静态percpu变量分配了reserved区域内存,在内核模块加载过程中,会动态的从pcpu_reserved_chunk中分配对应大小的内存区,然后将模块中的原始percpu变量拷贝到分配的区域中;在模块释放时,会动态的从pcpu_reserved_chunk回收这部分内存,以备其他模块使用,加载模块部分的大致实现流程如下
load_module /* 第一步,找到.data..percpu */ --> err = setup_load_info(info, flags); --> info->index.pcpu = find_pcpusec(info); --> find_sec(info, ".data..percpu"); /* 第二步,分配percpu内存 */ err = percpu_modalloc(mod, info); --> mod->percpu = __alloc_reserved_percpu(pcpusec->sh_size, align); /* reserved设置为ture,即从reserved chunk进行分配 */ --> pcpu_alloc(size, align, true, GFP_KERNEL); /* 第三步,将模块.data..percpu section中的静态percpu变量拷贝到分配的percpu内存中 */ err = post_relocation(mod, info); --> percpu_modcopy(mod, (void *)info->sechdrs[info->index.pcpu].sh_addr, info->sechdrs[info->index.pcpu].sh_size); /* 遍历所有active状态的cpu */ --> for_each_possible_cpu(cpu) memcpy(per_cpu_ptr(mod->percpu, cpu), from, size);
动态percpu变量
在percpu初始化阶段,为动态percpu变量也分配了percpu的内存区域,使用pcpu_first_chunk进行管理,并插入了哈希表pcpu_slot[slot]中;内核调用alloc_percpu宏分配动态percpu变量时,会遍历哈希表pcpu_slot[slot]中的chunk,此时即会找到pcpu_first_chunk,并从中分配一个合适的内存区,流程与本文第三节中的pcpu_reserved_chunk完全一致。
那么当pcpu_first_chunk管理的percpu的内存区域耗尽时,该如何处理呢?
内核会动态的创建一个新的chunk,并从vmalloc区域中分配新chunk管理的percpu的虚拟内存区域:
/* * Must be an lvalue. Since @var must be a simple identifier, * we force a syntax error here if it isn't. */ #define get_cpu_var(var) (*({ preempt_disable(); this_cpu_ptr(&var); })) /* * The weird & is necessary because sparse considers (void)(var) to be * a direct dereference of percpu variable (var). */ #define put_cpu_var(var) do { (void)&(var); preempt_enable(); } while (0)
即相当于percpu变量指针ptr加上__my_cpu_offset,__my_cpu_offset宏即是从当前cpu的tpidr_el1、tpidr_el2寄存器中取出此前设置的__per_cpu_offset[cpu]值,实现如下:
/* arch/arm64/include/asm/percpu.h */ static inline unsigned long __my_cpu_offset(void) { unsigned long off; /* * We want to allow caching the value, so avoid using volatile and * instead use a fake stack read to hazard against barrier(). */ asm(ALTERNATIVE("mrs %0, tpidr_el1", "mrs %0, tpidr_el2", ARM64_HAS_VIRT_HOST_EXTN) : "=r" (off) : "Q" (*(const unsigned long *)current_stack_pointer)); return off; } #define __my_cpu_offset __my_cpu_offset()
因此返回的当前cpu的percpu变量副本地址即为:
ptr + delta + pcpu_unit_offsets[cpu]
从图五可直观的看出返回的是静态percpu变量(ptr)在对应cpu上的副本地址
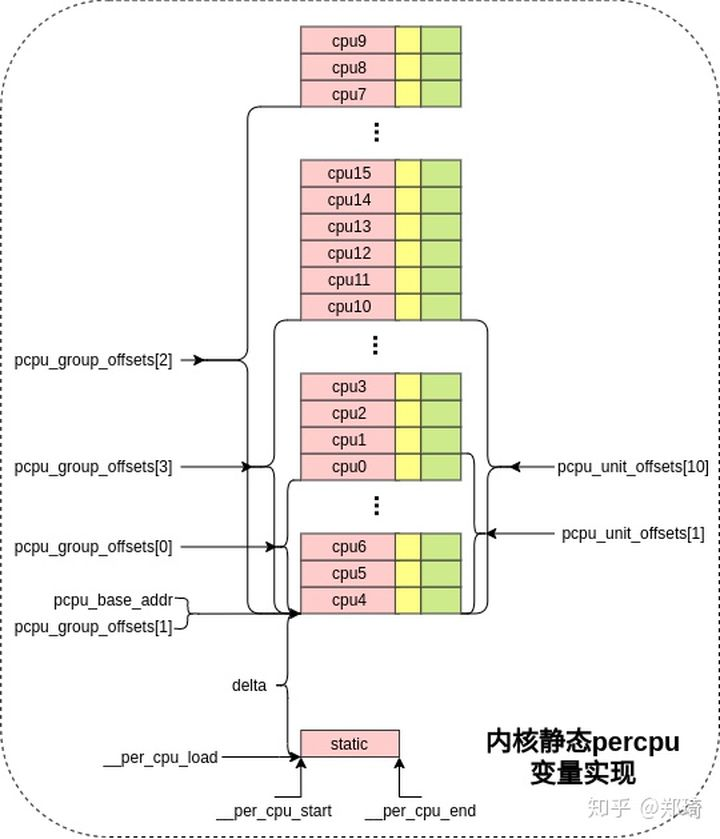
转载:https://zhuanlan.zhihu.com/p/260986194
1、静态声明和定义Per-CPU变量的API如下表所示:
| 声明和定义Per-CPU变量的API | 描述 |
| DECLARE_PER_CPU(type, name) DEFINE_PER_CPU(type, name) |
普通的、没有特殊要求的per cpu变量定义接口函数。没有对齐的要求 |
|
DECLARE_PER_CPU_FIRST(type, name) DEFINE_PER_CPU_FIRST(type, name) |
通过该API定义的per cpu变量位于整个per cpu相关section的最前面。 |
|
DECLARE_PER_CPU_SHARED_ALIGNED(type, name) DEFINE_PER_CPU_SHARED_ALIGNED(type, name) |
通过该API定义的per cpu变量在SMP的情况下会对齐到L1 cache line ,对于UP,不需要对齐到cachine line |
|
DECLARE_PER_CPU_ALIGNED(type, name) DEFINE_PER_CPU_ALIGNED(type, name) |
无论SMP或者UP,都是需要对齐到L1 cache line |
|
DECLARE_PER_CPU_PAGE_ALIGNED(type, name) DEFINE_PER_CPU_PAGE_ALIGNED(type, name) |
为定义page aligned per cpu变量而设定的API接口 |
|
DECLARE_PER_CPU_READ_MOSTLY(type, name) DEFINE_PER_CPU_READ_MOSTLY(type, name) |
通过该API定义的per cpu变量是read mostly的 |
这些定义使用在不同的场合,主要的factor包括:
-该变量在section中的位置
-该变量的对齐方式
-该变量对SMP和UP的处理不同
-访问per cpu的形态
例如:如果你准备定义的per cpu变量是要求按照page对齐的,那么在定义该per cpu变量的时候需要使用DECLARE_PER_CPU_PAGE_ALIGNED。如果只要求在SMP的情况下对齐到cache line,那么使用DECLARE_PER_CPU_SHARED_ALIGNED来定义该per cpu变量。
2、访问静态声明和定义Per-CPU变量的API
静态定义的per cpu变量不能象普通变量那样进行访问,需要使用特定的接口函数,具体如下:
get_cpu_var(var)
put_cpu_var(var)
上面这两个接口函数已经内嵌了锁的机制(preempt disable),用户可以直接调用该接口进行本CPU上该变量副本的访问。如果用户确认当前的执行环境已经是preempt disable(例如持有spinlock),那么可以使用lock-free版本的Per-CPU变量的API:__get_cpu_var。
3、动态分配Per-CPU变量的API如下表所示:
| 动态分配和释放Per-CPU变量的API | 描述 |
| alloc_percpu(type) | 分配类型是type的per cpu变量,返回per cpu变量的地址(注意:不是各个CPU上的副本) |
| void free_percpu(void __percpu *ptr) | 释放ptr指向的per cpu变量空间 |
4、访问动态分配Per-CPU变量的API如下表所示:
| 访问Per-CPU变量的API | 描述 |
| get_cpu_ptr | 这个接口是和访问静态Per-CPU变量的get_cpu_var接口是类似的,当然,这个接口是for 动态分配Per-CPU变量 |
| put_cpu_ptr | 同上 |
| per_cpu_ptr(ptr, cpu) | 根据per cpu变量的地址和cpu number,返回指定CPU number上该per cpu变量的地址 |
目前内核中有很多动态的per-cpu 变量:比如网络内核中 tcp流量统计;
net->mib.tcp_statistics = alloc_percpu(struct tcp_mib); #define TCP_INC_STATS(net, field) SNMP_INC_STATS((net)->mib.tcp_statistics, field) #define __TCP_INC_STATS(net, field) __SNMP_INC_STATS((net)->mib.tcp_statistics, field) #define TCP_DEC_STATS(net, field) SNMP_DEC_STATS((net)->mib.tcp_statistics, field) #define TCP_ADD_STATS(net, field, val) SNMP_ADD_STATS((net)->mib.tcp_statistics, field, val) /输出tcp 流量统计 for_each 所有的变量 f (snmp4_tcp_list[i].entry == TCP_MIB_MAXCONN) seq_printf(seq, " %ld", snmp_fold_field(net->mib.tcp_statistics, snmp4_tcp_list[i].entry)); unsigned long snmp_fold_field(void __percpu *mib, int offt) { unsigned long res = 0; int i; for_each_possible_cpu(i) res += snmp_get_cpu_field(mib, i, offt); return res; }
per-cpu 变量虽然能保护变量被多个core 访问,但是它并不能保护同一核心上异步事件的访问,如ISR,deferred functions。在这样的情况下,同步原语还是需要的。
所以存在:TCP_INC_STATS __TCP_INC_STATS 两个宏定义的区别 也就是 this_cpu_inc / __this_cpu_inc 的区别
其中 this 开头版本的是带抢占/中断保护的,可以在任意上下文中使用; __this 开头版本的是不带抢占/中断保护的,要么每 CPU 变量不能在中断上下文或者可抢占上下文中使用,要么调用者负责保护;
对于radix 下次有机会再看
转载自:https://zhuanlan.zhihu.com/p/260986194