目前已经发现cps 打不上去,top中sys偏高, perf 以及strace 发现时accpet频繁的系统调用!
整体分析过程见:48核cps性能低于8核-debug cps
业务分析:
对于epoll的分析见之前文章:epoll 基本分析1 epoll基本分析2 惊群唤醒
结论:
epoll ET模式下存在惊群- thundering herd 现象:
1、对于进程间共享epoll实例,并且使用ET模式注册了同一个监听套接字,当第一个连接到达时,唤醒进程A,进程A在accept时候第二个连接达到,唤醒进程B,然后进程A醒来 通过循环进行accept了两条连接,最后进程B accept失败。
多进程共用一个epfd监听listen_fd:ep_poll_callback 处理方式将会导致多个进程都睡眠在同一epfd的等待队列,而对应listen_fd的等待队列则只有一个任务。如果事件到来则会调用此任务回调函数,接着只会唤醒休眠在epfd等待队列中的一个进程。至于为何此处会有惊群,原因在于在LT的方式下会将已就绪的事件再次添加到就绪链表,同时唤醒epfd等待队列额外的一个进程,原因在于LT是事件就绪不处理会一直通知
2、对于每个进程单独拥有epoll实例,但是共同注册同一个监听套接字,即使是ET模式,也会产生惊群,原因和示例1 一样 是因为会唤醒所有的进程;目前有的内核加了
EPOLLEXCLUSIVE 只唤醒一个进程!! 这个是linux 4.5 引入的!
多进程拥有各自的epfd监听同一listen_fd:ep_poll_callback处理方式将导致各个进程睡眠在各自的epfd的等待队列,
而对于listen_fd的等待队列则会有多个任务。这样就导致事件到来时将会唤醒任务,从而导致多个进程都被唤醒,从而导致惊群???
参考:https://lwn.net/Articles/667087/
https://netdev.vger.kernel.narkive.com/RWScCeSc/patch-net-next-epoll-add-epollexclusive-support
https://lwn.net/Articles/632590/
https://github.com/torvalds/linux/commit/df0108c5da561c66c333bb46bfe3c1fc65905898
EPOLLEXCLUSIVE比SO_REUSEPORT:
从CPU负载均衡角度来讲,EPOLLEXCLUSIVE比SO_REUSEPORT有可能更好一点 , 毕竟 reuseport 分配的时候不知道 用户态worker的繁忙情况,比如work1一直都在做gzip等任务非常耗cpu,但是内核通过hash 将新建立的socket分配到work1 来accept,此时work1 一直忙于处理别的事件,就回出现饿死现象,同时如果内核hash某个新的socket 到一个listen_fd上,此时这个listen_fd被关闭, 那么这个listen_fd 上等待accept的fd就回被drop!!那怎样处理?? 目前看到相关资料说的是ebpf 中的SO_ATTACH_REUSEPORT_EBPF可以解决此问题!
EPOLLEXCLUSIVE: 当内核fd readable时候, 会只唤醒一个进程,对于忙的work 此时可以不需要epoll_ctl add 进去。但是压力不大的时候可能导致链接只会在少数的worker上,毕竟链表尾部没有机会出来!。
epoll则不一样,在我们使用epoll_ctl的EPOLL_CTL_ADD时,将会在对应socket的等待队列添加一个任务,任务的回调函数将是ep_poll_callback;
此函数的作用:将就绪事件添加到任务所对应进程的就绪链表中,同时唤醒在另外一个等待队列(也就是epoll_fd的等待队列)睡眠的进程---
---->当使用epoll_ctl的EPOLL_CTL_ADD时会将任务添加到listen_fd的等待队列,没有设置WQ_FLAG_EXCLUSIVE。listen_fd的等待队列将有多个进程的 任务。
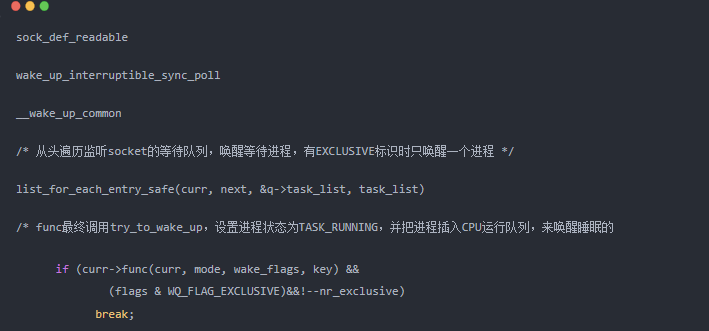
当事件到来时将从等待队列挨个调用其callback(见 sock_def_readable--- 在wake的时候没有 exclusive 标志会遍历链表哦).
那么将导致每个进程的就绪链表将都添加就绪事件同时都被从等待队列唤醒。无论是LT还是ET都会造成惊群!!


static void sock_def_readable(struct sock *sk) { struct socket_wq *wq; rcu_read_lock(); wq = rcu_dereference(sk->sk_wq); if (wq_has_sleeper(wq)) wake_up_interruptible_sync_poll(&wq->wait, POLLIN | POLLPRI | POLLRDNORM | POLLRDBAND); sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN); rcu_read_unlock(); } #define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL) #define wake_up_nr(x, nr) __wake_up(x, TASK_NORMAL, nr, NULL) #define wake_up_all(x) __wake_up(x, TASK_NORMAL, 0, NULL) #define wake_up_locked(x) __wake_up_locked((x), TASK_NORMAL, 1) #define wake_up_all_locked(x) __wake_up_locked((x), TASK_NORMAL, 0) #define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)------------ #define wake_up_interruptible_nr(x, nr) __wake_up(x, TASK_INTERRUPTIBLE, nr, NULL) #define wake_up_interruptible_all(x) __wake_up(x, TASK_INTERRUPTIBLE, 0, NULL) ---->__wake_up_common #define wake_up_interruptible_sync(x) __wake_up_sync((x), TASK_INTERRUPTIBLE, 1) static void __wake_up_common(wait_queue_head_t *q, unsigned int mode, int nr_exclusive, int wake_flags, void *key) { wait_queue_t *curr, *next; list_for_each_entry_safe(curr, next, &q->task_list, task_list) { unsigned flags = curr->flags; if (curr->func(curr, mode, wake_flags, key) && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive) break; } }
目前大部分情况下:使用listen + fork 模型也就是拥有独有的ep_fd,但是共享listen_fd;使用epoll时,是在epoll_wait()返回后,发现监听socket有可读事件,才调用accept(),
由于epoll_wait()是LIFO,导致多个子进程在accept新连接时,也变成了LIFO。
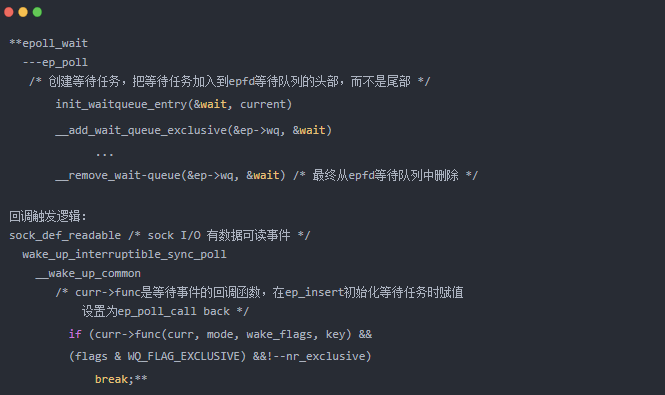
PS:---按道理说也是只唤醒一个,但是唤醒A进程后,还有新的事件来,就回唤醒队列里面的B进程;同时记住 没有WQ_FLAG_EXCLUSIVE标志的话, 不会去执行break 跳出哦
epoll_ctl ADD描述符时设置 EPOLLEXCLUSIVE 标识

所以:__wake_up_common遍历链表时,只有func返回1时并WQ_FLAG_EXCLUSIVE设置了才会只遍历1个任务
那么有没有func返回0的情况产生呢? 我们来查看ep_poll_callback什么时候返回0。
------------当进程不在epfd队列睡眠时而正在运行时将会返回0。--------------
--------------->__wake_up_common函数将继续访问下一个任务直到找到一个任务对应的进程在休眠才会 break 停止
其感知进程还在运行那么估计还在处理事件比较忙,然后找下一个进程来处理事件,不过由于是先将事件放入就绪链表,然后再找下一个进程,第二个任务同样将事件放入就绪链表并唤醒进程。可能会因为第一个进程把所有的处理完了,第二个进程无事可做了造成某些情况意义上的惊群;相比于没有此标志的情况,添加了此标志也算解决了等待队列任务全部调用了造成惊群的大问题
EPOLLEXCLUSIVE的使用必须明确一点:只适用于多个线程/进程拥有各自的epfd,然后监听同一listen_fd。
目前使用的内核中没有reuseport 以及EPOLLEXCLUSIVE 标志位!!
那我们应该怎样处理!! 在内核中加入 reuseport 还是 exclusive??
来分析一下惊群的原因以及总结一些抽象模型
1、说白了就是wake_up 以及 call_back的时候 限制条件没有处理好!!导致竞争
2、多进程场景下:默认的accept(非复用),进程加入到监听socket等待队列的尾部,唤醒时从头部开始唤醒;
epoll的accept,在epoll_wait时把进程加入到监听socket等待队列的头部,唤醒时从头部开始唤醒
我们期望的是:

然而实际上是:
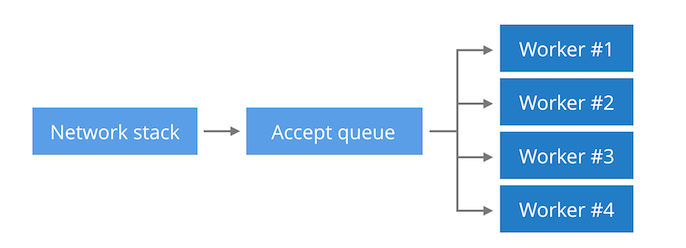
那怎么处理呢??

使用多个listen socket 对应多个线程!!
worker1 bind cpu 1 listen port :901
-----------------------------
workerN bind cpu N listen port :90N
为什么能这样处理:
原因:设备使用transparent功能 内核版本较老, 没有reuseport exclusive等功能;但是transparent 功能的使用的listen fd 可以随意添加,
所以为了防止多核cpu抢占一个listen_fd, 就设置为一个cpu bind 一个listen_fd 实现类似于 reuseport的功能
进一步抽象结果是: 多核CPU 去抢占资源导致浪费CPU,那怎样防止多核CPU去抢占竞争资源呢? 想一想编程中的 互斥原因是多进程对全局变量的访问导致,如果都是进程私有的“局部”变量,那么进程访问变量资源就不会相互干扰了!所以解决思路就是将资源变为”私有的“;此时资源比较多怎样划分呢?必然涉及到负载均衡,而且还是主动划分!! ---不像以前是被动的等待CPU来竞争!!
所以方案是:每个CPU 都有一个线程 都有一个listen_fd,相互不干扰!新的链接负载均分散列到每一个listen_fd上去!! 主动的分发资源,不是被动的等待CPU竞争!! 这不就是减少了CPU 互斥吗!!
后续面对这些问题都是一样的思路!!!毕竟大道至简 ---万物之始,大道至简,衍化至繁------去繁就简
目前优化效果: 第一次结果cps约为7w+, 远大于7k
https://blog.cloudflare.com/the-sad-state-of-linux-socket-balancing/