https://switch-router.gitee.io/blog/sk-sndbuf/
最近遇到一个问题,简化模型如下:

Client 创建一个 TCP 的 socket,并通过 SO_SNDBUF 选项设置它的发送缓冲区大小为 4096 字节,连接到 Server 后,每 1 秒发送一个 TCP 数据段长度为 1024 的报文。Server 端不调用 recv()。预期的结果分为以下几个阶段:
Phase 1. Server 端的 socket 接收缓冲区未满,所以尽管 Server 不会 recv(),但依然能对 Client 发出的报文回复 ACK; Phase 2. Server 端的 socket 接收缓冲区被填满了,向 Client 端通告零窗口(Zero Window)。Client 端待发送的数据开始累积在 socket 的发送缓冲区; Phase 3. Client 端的 socket 的发送缓冲区满了,用户进程阻塞在 send() 上。
实际执行时,表现出来的现象也”基本”符合预期。不过当我们在 Client 端通过 ss -nt 不时监控 TCP 连接的发送队列长度时,发现这个值竟然从 0 最终增长到 14480,它轻松地超了之前设置的 SO_SNDBUF 值(4096)
# ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 1024 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 2048 192.168.183.130:52454 192.168.183.130:14465
......
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 13312 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 14336 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 14480 192.168.183.130:52454 192.168.183.130:14465
有必要解释一下这里的 Send-Q 的含义。我们知道,TCP 是的发送过程是受到滑动窗口限制。
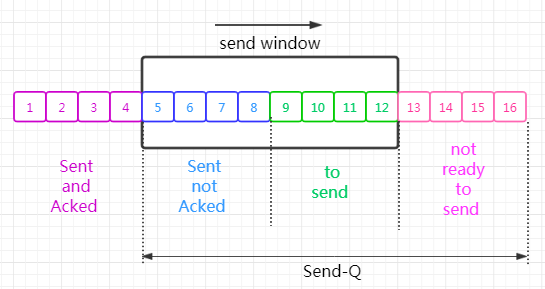
这里的 Send-Q 就是发送端滑动窗口的左边沿到所有未发送的报文的总长度。
那么为什么这个值超过了 SO_SNDBUF 呢?
双倍 SO_SNDBUF
当用户通过 SO_SNDBUF 选项设置套接字发送缓冲区时,内核将其记录在 sk->sk_sndbuf 中。
@sock.c: sock_setsockopt
.....
case SO_SNDBUF:
.....
sk->sk_sndbuf = mat_x(u32, val * 2, SOCK_MIN_SNDBUF)
注意,内核在这里玩了一个小 trick,它在 sk->sk_sndbuf 记录的的不是用户设置的 val, 而是 val 的两倍!
也就是说,当 Client 设置 4096 时,内核记录的是 8192 !
那么,为什么内核需要这么做呢? 我认为是因为内核用 sk_buff 保存用户数据有额外的开销,比如 sk_buff 结构本身、以及 skb_shared_info 结构,还有 L2、L3、L4 层的首部大小.这些额外开销自然会占据发送方的内存缓冲区,但却不应该是用户需要 care 的,所以内核在这里将这个值翻个倍,保证即使有一半的内存用来存放额外开销,也能保证用户的数据有足够内存存放。
但是,问题现象还不能解释,因为即使是 8192 字节的发送缓冲区内存全部用来存放用户数据(额外开销为 0,当然这是不可能的),也达不到 Send-Q 最后达到的 14480 。
sk_wmem_queued
既然设置了 sk->sk_sndbuf, 那么内核就会在发包时检查当前的发送缓冲区已使用内存值是否超过了这个限制,前者使用 sk->wmem_queued 保存。
需要注意的是,sk->wmem_queued = 待发送数据占用的内存 + 额外开销占用的内存,所以它应该大于 Send-Q
@sock.h
bool sk_stream_memory_free(const struct sock* sk)
{
if (sk->sk_wmem_queued >= sk->sk_sndbuf) // 如果当前 sk_wmem_queued 超过 sk_sndbuf,则返回 false,表示内存不够了
return false;
.....
}
sk->wmem_queued 是不断变化的,对 TCP socket 来说,当内核将 skb 塞入发送队列后,这个值增加 skb->truesize (truesize 正如其名,是指包含了额外开销后的报文总大小);而当该报文被 ACK 后,这个值减小 skb->truesize。
tcp_sendmsg
以上都是铺垫,让我们来看看 tcp_sendmsg 是怎么做的。总的来说内核会根据发送队列(write queue)是否有待发送的报文,决定创建新的 sk_buff 还是 **将用户数据追加(append)到 write queue 的最后一个sk_buff **
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
mss_now = tcp_send_mss(sk, &size_goal, flags);
// code committed
while (msg_data_left(msg)) {
int copy = 0;
int max = size_goal;
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
......
copy = max - skb->len;
}
if (copy <= 0) {
/* case 1: alloc new skb */
new_segment:
if (!sk_stream_memory_free(sk))
goto wait_for_sndbuf; // 如果发送缓冲区满了 就阻塞进程 然后睡眠
skb = sk_stream_alloc_skb(sk,
select_size(sk, sg),
sk->sk_allocation,
skb_queue_empty(&sk->sk_write_queue));
}
......
/* case 2: copy msg to last skb */
......
}
Case 1.创建新的 sk_buff
在我们这个问题中,Client 在 Phase 1 是不会累积 sk_buff 的。也就是说,这时每个用户发送的报文都会通过 sk_stream_alloc_skb 创建新的 sk_buff。在这之前,内核会检查发送缓冲区内存是否已经超过限制,而在Phase 1 ,内核也能通过这个检查。
static inline bool sk_stream_memory_free(const struct sock* sk)
{
if (sk-?sk_wmem_queued >= sk->sk_sndbuf)
return false;
......
}
Case 2.将用户数据追加到最后一个 sk_buff
而在进入 Phase 2 后,Client 的发送缓冲区已经有了累积的 sk_buff,这时,内核就会尝试将用户数据(msg中的内容)追加到 write queue 的最后一个 sk_buff。需要注意的是,这种搭便车的数据也是有大小限制的,它用 copy 表示
@tcp_sendmsg
int max = size_goal;
copy = max - skb->len;
这里的 size_goal 表示该 sk_buff 最多能容纳的用户数据,减去已经使用的 skb->len, 剩下的就是还可以追加的数据长度。
那么 size_goal 是如何计算的呢?
tcp_sendmsg
|-- tcp_send_mss
|-- tcp_xmit_size_goal
static unsigned int tcp_xmit_size_goal(struct sock* sk, u32 mss_now, int large_allowed)
{
if (!large_allowed || !sk_can_gso(sk))
return mss_now;
.....
size_goal = tp->gso_segs * mss_now;
.....
return max(size_goal, mss_now);
}
继续追踪下去,可以看到,size_goal 跟使用的网卡是否使能了 GSO 功能有关。
- GSO Enable: size_goal = tp->gso_segs * mss_now
- GSO Disable: size_goal = mss_now
在我的实验环境中,TCP 连接的有效 mss_now 是 1448 字节,用 systemtap 加了探测点后,发现 size_goal 为 14480 字节!是 mss_now 的整整 10 倍。
所以当 Clinet 进入 Phase 2 时,tcp_sendmsg 计算出 copy = 14480 - 1024 = 13456 字节。
可是最后一个 sk_buff 真的能装这么多吗?
在实验环境中,Phase 1 阶段创建的 sk_buff ,其 skb->len = 1024, skb->truesize = 4372 (4096 + 256,这个值的详细来源请看 sk_stream_alloc_skb)
这样看上去,这个 sk_buff 也容纳不下 14480 啊。
再继续看内核的实现,再 skb_copy_to_page_nocache() 拷贝之前,会进行 sk_wmem_schedule()
tcp_sendmsg
{
/* case 2: copy msg to last skb */
......
if (!sk_wmem_schedule(sk, copy))
goto wait_for_memory;
err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
pfrag->page,
pfrag->offset,
copy);
}
而在 sk_wmem_schedule 内部,会进行 sk_buff 的扩容(增大可以存放的用户数据长度).
tcp_sendmsg
|--sk_wmem_schedule
|-- __sk_mem_schedule
__sk_mem_schedule(struct sock* sk, int size, int kind)
{
sk->sk_forward_alloc += amt * SK_MEM_QUANTUM;
allocated = sk_memory_allocated_add(sk, amt, &parent_status);
......
// 后面有一堆检查,比如如果系统内存足够,就不去看他是否超过 sk_sndbuf
}
通过这种方式,内核可以让 sk->wmem_queued 在超过 sk->sndbuf 的限制。
我并不觉得这样是优雅而合理的行为,因为它让用户设置的 SO_SNDBUF 形同虚设!那么我可以增么修改呢?
- 关掉网卡 GSO 特性
- 修改内核代码, 将检查发送缓冲区限制移动到 while 循环的开头。
while (msg_data_left(msg)) {
int copy = 0;
int max = size_goal;
+ if (!sk_stream_memory_free(sk))
+ goto wait_for_sndbuf;
skb = tcp_write_queue_tail(sk);
if (tcp_send_head(sk)) {
if (skb->ip_summed == CHECKSUM_NONE)
max = mss_now;
copy = max - skb->len;
}
if (copy <= 0) {
new_segment:
/* Allocate new segment. If the interface is SG,
* allocate skb fitting to single page.
*/
- if (!sk_stream_memory_free(sk))
- goto wait_for_sndbuf;