struct tcp_sock {//在 inet_connection_sock 基础上增加了 滑动窗口 拥塞控制算法等tcp 专有 属性
/* inet_connection_sock has to be the first member of tcp_sock */
struct inet_connection_sock inet_conn;
u16 tcp_header_len; /* Bytes of tcp header to send */
u16 gso_segs; /* Max number of segs per GSO packet */
/*
* Header prediction flags
* 0x5?10 << 16 + snd_wnd in net byte order
*/
__be32 pred_flags;/*首部预测标志 在接收到 syn 跟新窗口 等时设置此标志 ,
此标志和时间戳 序号等 用于判断执行 快速还是慢速路径*/
/*
* RFC793 variables by their proper names. This means you can
* read the code and the spec side by side (and laugh ...)
* See RFC793 and RFC1122. The RFC writes these in capitals.
*/
u64 bytes_received; /* RFC4898 tcpEStatsAppHCThruOctetsReceived
* sum(delta(rcv_nxt)), or how many bytes
* were acked.
*/
u32 segs_in; /* RFC4898 tcpEStatsPerfSegsIn
* total number of segments in.
*/
u32 rcv_nxt; /* What we want to receive next 等待接收的下一个序列号 */
u32 copied_seq; /* Head of yet unread data */
/* rcv_nxt on last window update sent最早接收但没有确认的序号, 也就是接收窗口的左端,
在发送ack的时候, rcv_nxt更新 因此rcv_wup 更新比rcv_nxt 滞后一些 */
u32 rcv_wup;
u32 snd_nxt; /* Next sequence we send 等待发送的下一个序列号 */
u32 segs_out; /* RFC4898 tcpEStatsPerfSegsOut
* The total number of segments sent.
*/
u64 bytes_acked; /* RFC4898 tcpEStatsAppHCThruOctetsAcked
* sum(delta(snd_una)), or how many bytes
* were acked.
*/
struct u64_stats_sync syncp; /* protects 64bit vars (cf tcp_get_info()) */
u32 snd_una; /* First byte we want an ack for 最早一个未被确认的序号 */
u32 snd_sml; /* Last byte of the most recently transmitted small packet 最近发送一个小于mss的最后 一个字节序列号
在成功发送, 如果报文小于mss,跟新这个字段 主要用来判断是否启用 nagle 算法*/
u32 rcv_tstamp; /* timestamp of last received ACK (for keepalives) 最近一次收到ack的时间 用于 tcp 保活*/
u32 lsndtime; /* timestamp of last sent data packet (for restart window) 最近一次发送 数据包时间*/
u32 last_oow_ack_time; /* timestamp of last out-of-window ACK */
u32 tsoffset; /* timestamp offset */
struct list_head tsq_node; /* anchor in tsq_tasklet.head list */
unsigned long tsq_flags;
/* Data for direct copy to user cp 数据到用户进程的控制块 有用户缓存以及其长度 prequeue 队列 其内存*/
struct {
struct sk_buff_head prequeue // tcp 段 缓冲到此队列 知道进程主动读取才真正的处理;
struct task_struct *task;
struct msghdr *msg;
int memory;// prequeue 当前消耗的内存
int len;// 用户缓存中 当前可以使用的缓存大小
} ucopy;
u32 snd_wl1; /* Sequence for window update记录跟新发送窗口的那个ack 段号 用来判断是否 需要跟新窗口
如果后续收到ack大于snd_wll 则表示需要更新 窗口*/
u32 snd_wnd; /* The window we expect to receive 接收方 提供的窗口大小 也就是发送方窗口大小 */
u32 max_window; /* Maximal window ever seen from peer 接收方通告的最大窗口 */
u32 mss_cache; /* Cached effective mss, not including SACKS 发送方当前有效的mss*/
u32 window_clamp; /* Maximal window to advertise 滑动窗口最大值 */
u32 rcv_ssthresh; /* Current window clamp 当前接收窗口的阈值 */
/* Information of the most recently (s)acked skb */
struct tcp_rack {
struct skb_mstamp mstamp; /* (Re)sent time of the skb */
u8 advanced; /* mstamp advanced since last lost marking */
u8 reord; /* reordering detected */
} rack;
u16 advmss; /* Advertised MSS本端能接收的 MSS 上限,在建立时用来通告对方 */
u8 unused;
u8 nonagle : 4,/* Disable Nagle algorithm? 是否 开启 ngnagle 算法 */
thin_lto : 1,/* Use linear timeouts for thin streams */
thin_dupack : 1,/* Fast retransmit on first dupack */
repair : 1,
frto : 1;/* F-RTO (RFC5682) activated in CA_Loss */
u8 repair_queue;
u8 do_early_retrans:1,/* Enable RFC5827 early-retransmit */
syn_data:1, /* SYN includes data */
syn_fastopen:1, /* SYN includes Fast Open option */
syn_fastopen_exp:1,/* SYN includes Fast Open exp. option */
syn_data_acked:1,/* data in SYN is acked by SYN-ACK */
save_syn:1, /* Save headers of SYN packet */
is_cwnd_limited:1;/* forward progress limited by snd_cwnd? */
u32 tlp_high_seq; /* snd_nxt at the time of TLP retransmit. */
/* RTT measurement */
u32 srtt_us; /* smoothed round trip time << 3 in usecs 平滑rtt*/
u32 mdev_us; /* medium deviation rtt平均偏差 */
u32 mdev_max_us; /* maximal mdev for the last rtt period rtt平均偏差最大值 */
u32 rttvar_us; /* smoothed mdev_max */
u32 rtt_seq; /* sequence number to update rttvar 记录SND.UNA 计算rto 时比较SND.NUA是否已经给更新
如果SND.UNA 跟新,则需要同时跟新rttval*/
struct rtt_meas {
u32 rtt, ts; /* RTT in usec and sampling time in jiffies. */
} rtt_min[3];
u32 packets_out; /* Packets which are "in flight"发送出去 没有被ack的数 (SND.NEXT -SND.UNA )*/
u32 retrans_out; /* Retransmitted packets out 重传还未得到确认的tcp数 重传并且还未得到确认的 TCP 段的数目*/
u32 max_packets_out; /* max packets_out in last window */
u32 max_packets_seq; /* right edge of max_packets_out flight */
u16 urg_data; /* Saved octet of OOB data and control flags 存放紧急数据以及控制标示 */
u8 ecn_flags; /* ECN status bits. */
u8 keepalive_probes; /* num of allowed keep alive probes 保活探测次数上限 */
u32 reordering; /* Packet reordering metric. tp->reordering = sock_net(sk)->ipv4.sysctl_tcp_reordering;三个重复ACK报文时,触发快速重传 */
u32 snd_up; /* Urgent pointer 紧急数据指针 带外数据的序号 */
/*
* Options received (usually on last packet, some only on SYN packets).
*/
struct tcp_options_received rx_opt;
/*
* Slow start and congestion control (see also Nagle, and Karn & Partridge)
*/
u32 snd_ssthresh; /* Slow start size threshold 拥塞控制 满启动阈值 */
u32 snd_cwnd; /* Sending congestion window 当前拥塞窗口大小 ---发送的拥塞窗口 */
u32 snd_cwnd_cnt; /* Linear increase counter 自从上次调整拥塞窗口后 到目前位置接收到的
总ack段数 如果该字段为0 表示调整拥塞窗口但是没有收到ack,调整拥塞窗口之后 收到ack段就回让
snd_cwnd_cnt 加1 */
u32 snd_cwnd_clamp; /* Do not allow snd_cwnd to grow above this snd_cwnd 的最大值*/
u32 snd_cwnd_used;//记录已经从队列发送而没有被ack的段数
u32 snd_cwnd_stamp;//记录最近一次检验cwnd 的时间; 拥塞期间 每次会检验cwnd而调节拥塞窗口 ,
//在非拥塞期间,为了防止应用层序造成拥塞窗口失效 因此在发送后 有必要检测cwnd
u32 prior_cwnd; /* Congestion window at start of Recovery.在进入 Recovery 状态时的拥塞窗口 */
u32 prr_delivered; /* Number of newly delivered packets to在恢复阶段给接收者新发送包的数量
* receiver in Recovery. */
u32 prr_out; /* Total number of pkts sent during Recovery.在恢复阶段一共发送的包的数量 */
u32 rcv_wnd; /* Current receiver window 当前接收窗口的大小 */
u32 write_seq; /* Tail(+1) of data held in tcp send buffer 已加入发送队列中的最后一个字节序号*/
u32 notsent_lowat; /* TCP_NOTSENT_LOWAT */
u32 pushed_seq; /* Last pushed seq, required to talk to windows */
u32 lost_out; /* Lost packets丢失的数据报 */
u32 sacked_out; /* SACK'd packets启用 SACK 时,通过 SACK 的 TCP 选项标识已接收到的段的数量。
不启用 SACK 时,标识接收到的重复确认的次数,该值在接收到确认新数据段时被清除。 */
u32 fackets_out; /* FACK'd packets FACK'd packets 记录 SND.UNA 与 (SACK 选项中目前接收方收到的段中最高序号段) 之间的段数。FACK
用 SACK 选项来计算丢失在网络中上的段数 lost_out=fackets_out-sacked_out left_out=fackets_out fackets_out = sack_out + lost_out*/
/* from STCP, retrans queue hinting */
struct sk_buff* lost_skb_hint; /*在重传队列中, 缓存下次要标志的段*/
struct sk_buff *retransmit_skb_hint;/* 表示将要重传的起始包*/
/* OOO segments go in this list. Note that socket lock must be held,
* as we do not use sk_buff_head lock.
*/
struct sk_buff_head out_of_order_queue;
/* SACKs data, these 2 need to be together (see tcp_options_write) */
struct tcp_sack_block duplicate_sack[1]; /* D-SACK block */
struct tcp_sack_block selective_acks[4]; /* The SACKS themselves*/
struct tcp_sack_block recv_sack_cache[4];
struct sk_buff *highest_sack; /* skb just after the highest最大sack序列号
* skb with SACKed bit set
* (validity guaranteed only if
* sacked_out > 0)
*/
int lost_cnt_hint;/* 已经标志了多少个段 */
u32 retransmit_high; /* L-bits may be on up to this seqno 表示将要重传的起始包 */
u32 prior_ssthresh; /* ssthresh saved at recovery start表示前一个snd_ssthresh得大小 */
u32 high_seq; /* snd_nxt at onset of congestion拥塞开始时,snd_nxt的大----开始拥塞的时候下一个要发送的序号字节*/
u32 retrans_stamp; /* Timestamp of the last retransmit,
* also used in SYN-SENT to remember stamp of
* the first SYN. */
u32 undo_marker; /* snd_una upon a new recovery episode. 在使用 F-RTO 算法进行发送超时处理,或进入 Recovery 进行重传,
或进入 Loss 开始慢启动时,记录当时 SND.UNA, 标记重传起始点。它是检测是否可以进行拥塞控制撤销的条件之一,一般在完成
拥塞撤销操作或进入拥塞控制 Loss 状态后会清零。*/
int undo_retrans; /* number of undoable retransmissions. 在恢复拥塞控制之前可进行撤销的重传段数。
在进入 FTRO 算法或 拥塞状态 Loss 时,清零,在重传时计数,是检测是否可以进行拥塞撤销的条件之一。*/
u32 total_retrans; /* Total retransmits for entire connection */
u32 urg_seq; /* Seq of received urgent pointer 紧急数据的序号 所在段的序号和紧急指针相加获得*/
unsigned int keepalive_time; /* time before keep alive takes place */
unsigned int keepalive_intvl; /* time interval between keep alive probes */
int linger2;
/* Receiver side RTT estimation */
struct {
u32 rtt;
u32 seq;
u32 time;
} rcv_rtt_est;
/* Receiver queue space */
struct {
int space;
u32 seq;
u32 time;
} rcvq_space;
/* TCP-specific MTU probe information. */
struct {
u32 probe_seq_start;
u32 probe_seq_end;
} mtu_probe;
u32 mtu_info; /* We received an ICMP_FRAG_NEEDED / ICMPV6_PKT_TOOBIG
* while socket was owned by user.
*/
#ifdef CONFIG_TCP_MD5SIG
/* TCP AF-Specific parts; only used by MD5 Signature support so far */
const struct tcp_sock_af_ops *af_specific;
/* TCP MD5 Signature Option information */
struct tcp_md5sig_info __rcu *md5sig_info;
#endif
/* TCP fastopen related information */
struct tcp_fastopen_request *fastopen_req;
/* fastopen_rsk points to request_sock that resulted in this big
* socket. Used to retransmit SYNACKs etc.
*/
struct request_sock *fastopen_rsk;
u32 *saved_syn;
};
tcp_sock 是在inet_connection_sock结构的基础上扩展了滑动窗口协议、 拥塞控制算法等一些 TCP 的专有属
接收端在检测数据包乱序是否超过乱序阀值(默认为3,在proc的tcp_reordering里可配置)是会用到fack_out和sacked_out,针对这两个的含义如下图所示,fack_out表示收到最大sack到snd_una间的大小,sacked_out表示接收方sack到的包个数;
接收端在检测数据包乱序是否超过乱序阀值(默认为3,在proc的tcp_reordering里可配置)是会用到fack_out和sacked_out,针对这两个的含义如下图所示,fack_out表示收到最大sack到snd_una间的大小,sacked_out表示接收方sack到的包个数;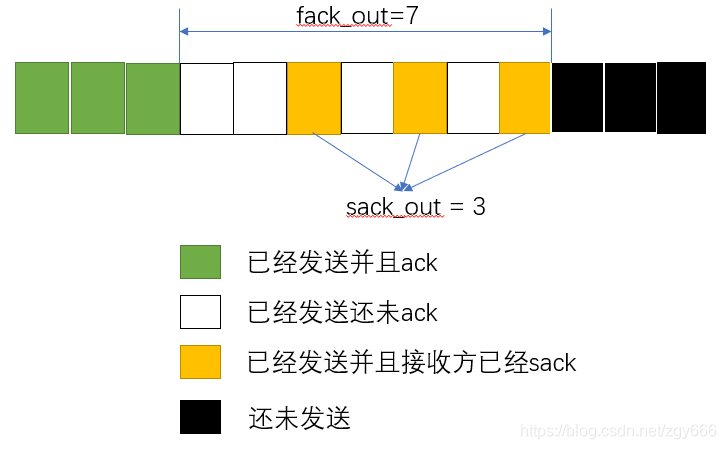
tcp_skb_cb结构体用于将每个 TCP 包中的控制信息传递给发送封包的代码
/* This is what the send packet queuing engine uses to pass * TCP per-packet control information to the transmission code. * We also store the host-order sequence numbers in here too. * This is 44 bytes if IPV6 is enabled. * If this grows please adjust skbuff.h:skbuff->cb[xxx] size appropriately. */ struct tcp_skb_cb { __u32 seq; /* Starting sequence number *起始序号 */ __u32 end_seq; /* SEQ + FIN + SYN + datalen */ union { /* Note : tcp_tw_isn is used in input path only * (isn chosen by tcp_timewait_state_process()) * * tcp_gso_segs/size are used in write queue only, * cf tcp_skb_pcount()/tcp_skb_mss() */ __u32 tcp_tw_isn; struct { u16 tcp_gso_segs; u16 tcp_gso_size; }; }; __u8 tcp_flags; /* TCP header flags. (tcp[13]) */ __u8 sacked; /* State flags for SACK/FACK. */ #define TCPCB_SACKED_ACKED 0x01 /* SKB ACK'd by a SACK block SKB 被确认了 ----被 SACK 块 ACK'd 也就是SACK块已经给出了skb数据缓冲区中的段回答信息 */ #define TCPCB_SACKED_RETRANS 0x02 /* SKB retransmitted 数据段被重传 */ #define TCPCB_LOST 0x04 /* SKB is lost 数据段已经丢失 */ #define TCPCB_TAGBITS 0x07 /* All tag bits TCPCB_TAGBITS = TCPCB_SACKED_ACKED | TCPCB_SACKED_RESTRANS | TCPCB_LOST */ #define TCPCB_REPAIRED 0x10 /* SKB repaired (no skb_mstamp) */ #define TCPCB_EVER_RETRANS 0x80 /* Ever retransmitted frame 指明数据段以前是否重传过 */ #define TCPCB_RETRANS (TCPCB_SACKED_RETRANS|TCPCB_EVER_RETRANS| \ TCPCB_REPAIRED) __u8 ip_dsfield; /* IPv4 tos or IPv6 dsfield */ /* 1 byte hole */ __u32 ack_seq; /* Sequence number ACK'd ACK 的序号 */ union { struct inet_skb_parm h4; #if IS_ENABLED(CONFIG_IPV6) struct inet6_skb_parm h6; #endif
inet_connection_sock 它是所有面向传输控制块的表示。其在inet_sock的基础上,增加了有关连接,确认,重传等成
/** inet_connection_sock - INET connection oriented sock * * @icsk_accept_queue: FIFO of established children * @icsk_bind_hash: Bind node * @icsk_timeout: Timeout * @icsk_retransmit_timer: Resend (no ack) * @icsk_rto: Retransmit timeout * @icsk_pmtu_cookie Last pmtu seen by socket * @icsk_ca_ops Pluggable congestion control hook * @icsk_af_ops Operations which are AF_INET{4,6} specific * @icsk_ca_state: Congestion control state * @icsk_retransmits: Number of unrecovered [RTO] timeouts * @icsk_pending: Scheduled timer event * @icsk_backoff: Backoff * @icsk_syn_retries: Number of allowed SYN (or equivalent) retries * @icsk_probes_out: unanswered 0 window probes * @icsk_ext_hdr_len: Network protocol overhead (IP/IPv6 options) * @icsk_ack: Delayed ACK control data * @icsk_mtup; MTU probing control data */ struct inet_connection_sock { /* inet_sock has to be the first member! */ struct inet_sock icsk_inet; //inet_connection_sock common struct struct request_sock_queue icsk_accept_queue; //tcp newsk 存放新的链接sock 等待accept 读取 struct inet_bind_bucket *icsk_bind_hash;//指向与之bind的信息 unsigned long icsk_timeout;//数据包超时时间-- 重传 tv_off --通常为 jiffies+ icsk_rto 后 进行重传 struct timer_list icsk_retransmit_timer; // 通过icsk_pengding 来区分重传定时器和持续定时器 struct timer_list icsk_delack_timer;// 延时发送ack 定时器 __u32 icsk_rto;// 重传超时时间 初始值为 TCP_TIMEOUT_INIT 根据网络情况动态计算 __u32 icsk_pmtu_cookie; //最后一次更新的路径MTU const struct tcp_congestion_ops *icsk_ca_ops; const struct inet_connection_sock_af_ops *icsk_af_ops; unsigned int (*icsk_sync_mss)(struct sock *sk, u32 pmtu); __u8 icsk_ca_state:6,// 拥塞状态 icsk_ca_setsockopt:1, icsk_ca_dst_locked:1; __u8 icsk_retransmits;// 超时重传的次数 __u8 icsk_pending; //标志定时器事件 ICSK_TIME_EARLY_RETRANS 等可选值 表示 重传定时 持续定时器 保活定时器等 __u8 icsk_backoff;// 计算持续定时器 下一个设定值的指数 退避算法指数 __u8 icsk_syn_retries; // 建立tcp 允许 重传 syn syn+ack的次数 __u8 icsk_probes_out;// 持续定时等 周期性发出未被确认的tcp seg 数目 __u16 icsk_ext_hdr_len; struct { __u8 pending; /* ACK is pending 标示 需要确认发送的 紧急程度 和状态 */ __u8 quick; /* Scheduled number of quick acks在快速发送确认模式中 */ __u8 pingpong; /* The session is interactive 启用禁用 快速确认模式 1 ---标示延时发送ack 0 标示快速发送ack */ __u8 blocked; /* Delayed ACK was blocked by socket lock 软中断 用户进程 不能同时own sk 如果sk 被 user 拥有, 延时ack 定时器被触发,此时不应该发送ack, blocked 为1;标示 如果有机会就需要立即发送,所以当接收的数据被cp到user 后 就可以立即发送ack */ __u32 ato; /* Predicted tick of soft clock 延时确认的估值 */ unsigned long timeout; /* Currently scheduled timeout当前延时确认时间 超时后立即发送ack */ __u32 lrcvtime; /* timestamp of last received data packet 最近一次接收到数据包时间*/ __u16 last_seg_size; /* Size of last incoming segment最后一个接收到段的长度 用来计算rcv_mss */ __u16 rcv_mss; /* MSS used for delayed ACK decisions 由最近接收的段计算出MSS */ } icsk_ack; // 延时确认控制块 struct { int enabled;// 是否开启路径MTU /* Range of MTUs to search */ int search_high; int search_low; /* Information on the current probe当前mtu 探测的长度 用于判断mtu是否完成 初始值为0. */ int probe_size; u32 probe_timestamp; } icsk_mtup; u32 icsk_user_timeout; u64 icsk_ca_priv[64 / sizeof(u64)]; #define ICSK_CA_PRIV_SIZE (8 * sizeof(u64)) };
2、in_flight的计算
协议的中对于拥塞控制一般都是基于字节的描述,即cwnd表示允许TCP发送多少bytes的数据,而Linux中的拥塞控制是基于数据包做的实现,cwnd表示允许TCP发送多少个数据包。因此对于in_flight,Linux也是以数据包维护的,注意我这里说的in_flight并不是RFC5681中的FlightSize,而是RFC6675中的Pipe。RFC5681是拥塞控制的一个基本协议,而RFC6675则是SACK增强版本的拥塞控制,自然linux需要采用RFC6675中的方案。Pipe表示TCP发送端对于还在网络中传输的数据量的估算。in_flight表示目前还在网络中传输的数据包的个数。linux中以in_flight状态变量表示in_flight,进行拥塞控制的时候,如果in_flight>=cwnd的,就表示拥塞窗口不允许在额外发送数据包了。
如果对于下面的in_flight计算过程还是不懂那么请参考RFC6675中的SetPipe ()过程。另外如果要进一步理解linux拥塞控制的代码实现,强烈建议一定要读懂RFC6675。
in_flight = packets_out - left_out + retrans_out
packets_out:表示在SND.NXT和SND.UNA之间一共发送出去了多少个数据包
retrans_out:是重传的TCP报文的个数
left_out:表示已经离开网络但是没有被ack number确认接收的,它包含两部分
left_out = sacked_out + lost_out
sacked_out:这个表示乱序到达接收端的数据包,因此没有被ack number确认,当使能SACK的时候,该变量就是SACK反馈确认的数据包的个数,当没有使能SACK的时候,该变量为接收到的dup ACK的个数。我们之前介绍快速重传的时候说过,接收端收到乱序数据包的时候会立即反馈ACK,因此可以使用dup ACK来估计乱序到达接收端的数据包的总数
lost_out:被网络丢失的数据包的个数,这个变量在快速重传场景下是启发式估计的,正是不同的估计方式区分了不同的算法,目前linux有两种方法来估计lost_out
-
FACK:lost_out = fackets_out - sacked_out 从而 left_out = fackets_out,即在FACK下,所有在ack number和 most forward SACK之间的数据包,如果没有被SACK确认接收那么就被认定为在网络传输中发生丢失。FACK的相关信息请参考前面重传部分文章的介绍
-
NewReno:当拥塞控制进入Recovery状态的时候,假设一个数据包发生了丢失,当收到一个partial ACK的时候,则假设又有额外一个数据包发生了丢失。
而在RTO超时场景下,TCP进入Loss状态,linux则会认为所有发出去的数据包都丢失了,因此lost_out = packets_out,in_flight = retrans_out。
Linux进行拥塞控制判断是否允许发送TCP报文的时候就是根据in_flight是否小于cwnd来判断的。当in_flight<cwnd的时候说明拥塞控制允许发送这个报文,否则拥塞控制不允许发送这个报文。而流量控制中对于awnd的判断,则是根据当前报文最后一个byte的数据对应的系列号是否超过对端的接收窗口来判断的。
SACK 重传
-
未启用 SACK 时,TCP 重复 ACK 定义为收到连续相同的 ACK seq。[RFC5681]
-
启用 SACK 时,携带 SACK 的 ACK 也被认为重复 ACK。[RFC6675]
SACK下的特殊处理过程
SACK下的拥塞控制处理是linux中拥塞控制的实现依据,再次强调一遍RFC6675的重要性,linux中拥塞控制主体框架的实现是与RFC6675一致的,所以如果要理解linux中拥塞控制的实现,强烈建议看一下RFC6675。我这里给出RFC6675中SACK处理的2个关键点,下面的描述实际上不太严谨,严谨定义请参考RFC6675。
1、SACK下对于dup ACK的定义简单说是指反馈了新的SACK信息,也就是说SACK下ack number不同的ACK报文如果携带了新的SACK信息那么也是dup ACK,这是与SACK关闭场景下dup ACK的重大区别,这种场景下的示例请参考SACK重传的介绍文章。另外这一点也意味着在Disorder状态下,cwnd实际上是可以更新的。
2、SACK下会维护一个scoreboard,它可以标记出那些数据包已经lost需要重传,SACK下可以根据SACK信息,同时把多个数据包标记为lost。而在SACK关闭的时候,因为dup ACK不带有SACK信息,数据发送端收到dup ACK数量到达dupthresh的时候只能标记一个数据包为lost状态。实际上SACK把选择TCP待发送数据包的过程(如选择发送新的未发送数据还是发送重传数据?如果发送重传数据时候有多个数据包被标记为lost那么选择那个数据包来重传?)和拥塞控制解耦了。
3、SACK下引入了Pipe变量来表示目前还在网络中传输的数据量的估计值,这个是和linux实现中in_flight的含义一致的,关于in_flight和Pipe变量我在前面已经给出过比较详细的介绍,这里不再重复了。
至于发送端切换进入Recovery状态的处理以及从Recovery切换出来时候cwnd和ssthresh的更新处理与SACK关系场景是一致的,具体过程请参考前文。
二、Limited transmit
这里要介绍的limited transmit并不是SACK下特有的处理过程,在SACK关闭场景下也是一样的处理思路,之所以放在这里介绍,只是想把介绍内容分散开避免在一篇文章中介绍太多内容。
limited transmit中文字面意思就是受限传输,由RFC3042定义,在RFC5681和RFC6675中都有提及,limited transmit的主要目的是当发送窗口比较小的时候同样能有效的触发快速重传。例如dupthresh=3,发送窗口大小为3的时候,如果第一个数据包丢失,那么发送端只能收到两个dup ACK,按照传统快速重传算法的要求并不能触发快速重传,dup ACK意味着接收端收到了新的数据包,如果允许发送端收到dup ACK的时候发送新数据包,那么新发送的数据包就会触发足够的dup ACK从而触发快速重传(这里没有仅考虑传统的快速重传并没有考虑ER或者thin stream下的重传)。这种允许发送端在收到dup ACK时候发送新数据包的行为就是limited transmit,RFC3042限制limited transmit传输的最大数据包的个数不能超过(dupthresh-1)。实际上对应到Linux的实现,limited transmit就是对应TCP拥塞控制的Disorder状态的。
但是limited transmit不能解决的一种场景就是收到dup ACK的时候没有新的待发送的数据,此时就不足以触发传统形式的快速重传,这时候ER和thin stream重传就可以派上用途了。
3.3 Early Retransmit for TCP(ER 机制)
要解决的问题: 当无法收到足够的 dupack 时,TCP 标准的 Fast Retransmit 机制无法被触发,只能等待 RTO 超时才能进行丢包的重传。而 RTO 超时不管是时间等待代价,还是性能损耗代价都很大。
解决方法: 检测出无法收到足够 dupack 的场景,进而降低 dupack threshold 来触发快速重传。从而避免等待 RTO 超时重传,对性能造成较大的损耗。
总结出现 dupack 不够的情况:a. cwnd 较小 b. 发送窗口里大量的数据包都被丢失了 c.在数据发送的尾端发生丢包时
但是,上面各种极端的 case 有共同的特点:m. 无法产生足够的 dupack n.没有新的数据包可以发送进入网络,ER 机制就是在判断条件 m 和 n 都成立后,选择降低触发 Fast Retransmit 的阈值,来避免只能通过 RTO 超时重传的问题。
3.4 TCP Tail Loss Probe(TLP 算法)
ER 算法解决了 dupack 较少时无法触发快速重传的问题,但当发生尾丢包时,由于尾包后没有更多数据包,也就无法触发 dupack。TLP 算法通过发送一个 loss probe 包,以产生足够的 SACK/FACK 数据包来触发重传。TLP 算法会在 TCP 还是 Open 态时设置一个 Probetimeout(PTO),当链路中有未被确认的数据包,同时在 PTO 时间内未收到任何 ACK,则会触发 PTO 超时处理机制。TLP 会选择传输序号最大的一个数据包作为 tail loss probe 包,这个序号最大的包可能是一个可以发送的新的数据包,也可能是一个重传包。TLP 通过这样一个 tail loss probe 包,如果能够收到相应的 ACK,则会触发 FR 机制,而不是 RTO 机制。
3.5 伪超时与重传
在很多情况下,即使没有出现数据丢失也可能引发重传。这种不必要的重传称为伪重传,其主要造成原因是伪超时,即过早判定超时,其他因素如包失序、包重复,或 ACK 丢失也可能导致该现象。在实际 RTT 显著增长,超过当前 RTO 时,可能出现伪超时。在下层协议性能变化较大的环境中(如无线环境),这种情况出现得比较多。
TCP 为处理伪超时问题提出了许多方法。这些方法通常包含检测算法与响应算法。检测算法用于判断某个超时或基于计时器的重传是否真实,一旦认定出现伪超时则执行响应算法,用于撤销或减轻该超时带来的影响。检测算法包含 DSACK 、Eifel 检测算法、迁移 RTO 恢复算法(F-RTO) 三种。
3.5.1 DSACK 扩展
DSACK 的主要目的是判断何时的重传是不必要的,并了解网络中的其他事项。通过 DSACK 发送端至少可以推断是否发生了包失序、 ACK 丢失、包重复或伪重传。D-SACK 使用了 SACK 的第一个段来做标志, a. 如果 SACK 的第一个段的范围被 ACK 所覆盖,那么就是 D-SACK。b.如果 SACK 的第一个段的范围被 SACK 的第二个段覆盖,那么就是 D-SACK。RFC2883]没有具体规定发送端对 DSACK 怎样处理。[RFC3708]给出了一种实验算法,利用 DSACK 来检测伪重传,响应算法可采用 Eifel 响应算法。
3.5.2 Eifel 检测算法 [RFC3522]
实验性的 Eifel 检测算法利用了 TCP 的 TSOPT 来检测伪重传。在发生超时重传后,Eifel 算法等待接收下一个 ACK,若为针对第一次传输(即原始传输)的确认,则判定该重传是伪重传。
与 DSACK 的比较:利用 Eifel 检测算法能比仅采用 DSACK更早检测到伪重传行为,因为它判断伪重传的 ACK 是在启动丢失恢复之前生成的。相反, DSACK 只有在重复报文段到达接收端后才能发送,并且在 DSACK 返回至发送端后才能有所响应。及早检测伪重传更为有利,它能使发送端有效避免“回退 N”行为。
3.5.3 迁移 RTO 恢复算法(F-RTO)
前移 RTO 恢复(Forward-RTO Recovery,F-RTO)[RFC5682]是检测伪重传的标准算法。它不需要任何 TCP 选项,因此只要在发送端实现该方法后,即使针对不支持 TSOPT 的接收端也能有效地工作。该算法只检测由重传计时器超时引发的伪重传,对之前提到的其他原因引起的伪重传则无法判断。
F-RTO 的工作原理如下:1. F-RTO 会修改 TCP 的行为,在超时重传后收到第一个 ACK 时,TCP 会发送新(非重传)数据,之后再响应后一个到达的 ACK。2.如果其中有一个为重复 ACK,则认为此次重传没问题。3. 如果这两个都不是重复 ACK,则表示该重传是伪重传。4.重复 ACK 是在接收端收到失序的报文段产生的。这种方法比较直观。如果新数据的传输得到了相应的 ACK,就使得接收端窗口前移。如果新数据的发送导致了重复 ACK,那么接收端至少有一个或更多的空缺。这两种情况下,接收新数据都不会影响整体数据的传输性能。