Kafka Producer、Kafka Consumer相对于 Kafka Broker,都属于客户端。Kafka支持多种语言的客户端。下面就根据Java 语言客户端对Producer做个说明。
1、Producer API入门
KafkaProducer是一个发送record到Kafka Cluster的客户端API。这个类线程安全的。在应用程序中,通常的作法是:所有发往一个Kafka Cluster的线程使用同一个Producer对象.。如果你的程序要给多个Cluster发送消息,则需要使用多个Producer。

ProducerRecord说明
从上面代码里可以看出,代表要发送的消息记录类是ProducerRecord:
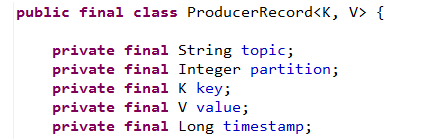
一条record通常包括5个字段:
- topic:指定该record发往哪个topic下。[Required]
- partition:指定该record发到哪个partition中。[Optional]
- key:一个key。[Optional]
- value:记录人内容。[Required]
- timestamp:时间戳。[Optional]
默认情况下:
如果用户指定了partition,那么就发往用户指定的partition。如果用户没有指定partition,那么就会根据key来决定放到哪个partition,如果key也没有指定,则由producer随机选取一个partition。
在Producer端,如果用户指定了timestamp,则record使用用户指定的时间,如果用户没有指定,则会使用producer端的当前时间。在broker端,如果配置了时间戳采用createtime方式,则使用producer传给Broker的record中的timestramp时间,如果指定为logappendtime,则在broker写入到Log文件时会重写该时间。
2、异步发送流程
2.1、用户线程调用send方法将record放到BufferPool中
可能在之前的kafka-client版本中,还支持同步方式发送消息记录。不过在我看的版本(0.10.0.0)中,已经不再支持同步方式发送了。当用户使用KafkaProducer#send()发送record时,执行流程是:
1、由interceptor chain对ProducerRecord做发送前的处理
拦截器接口是:ProducerInterceport,用户可以自定义自己的拦截器实现。

该拦截器链,在Producer对象初始化时初始化,之后不会再变了。所以呢,拦截器链中的拦截器都是公用的(意思是针对所有发送的消息是相同的拦截逻辑),如果要自定义拦截器的话,这个是需要注意的。
ProducerInterceptor有两个方法:
- onSend: KafkaProducer#send 调用时就会执行此方法。
- onAcknowledgement:发送失败,或者发送成功(broker 通知producer代表发送成功)时都会调用该方法。
此阶段执行的就是onSend方法。
2、阻塞方式获取到broker cluster 上broker cluster的信息
采用RPC方式获取到的broker信息,由一个MetaData类封装。它包括了broker cluster的必要信息,譬如有:所有的broker信息(idhostport等)、所有的topic名称、每一个topic对应的partition情况(id、leader node、replica nodes、ISR nodes等)。
虽然该过程是阻塞的,但并不是每发送一个record都会通过RPC方式来获取的。Metadata会在Producer端缓存,只有在record中指定的topic不存在时、或者MetaData轮询周期到时才会执行。
3、对record中key、value进行序列化
这个没有什么可说的。内置了基于String、Integer、Long、Double、Bytes、ByteBuffer、ByteArray的序列化工具。
4、为record设置partition属性
前面说过,创建ProducerRecord时,partition是Optional的。所以如果用户创建record时,没有指定partition属性。则由partition计算工具(Partitioner 接口)来计算出partition。这个计算方式可以自定义。Kafka Producer 提供了内置的实现:
- 如果提供了Key值,会根据key序列化后的字节数组的hashcode进行取模运算。
- 如果没有提供key,则采用迭代方式(其实取到的值并非完美的迭代,而是类似于随机数)。
5、校验record的长度是否超出阈值
MAX_REQUEST_SIZE_CONFIG=”max.request.size”
BUFFER_MEMORY_CONFIG=”buffer.memory”
超出任何一项就会抛出异常。
6、为record设置timestamp
如果用户创建ProducerRecord时没有指定timestamp,设置为producer的当前时间。
其实在java client中,设计了一个Time接口,专门用于设置这个时间的。内置了一个实现SystemTime,这里将record timestamp设置为当前时间,就是由SystemTime来完成的。所以如果希望在kafka producer java client中使用其它的时间,可以自定义Time的实现。
7、将该record压缩后放到BufferPool中
这一步是由RecordAccumulator来完成的。RecordAccumulator中为每一个topic维护了一个双端队列Deque<RecordBatch>,队列中的元素是RecordBatch(RecordBatch则由多个record压缩而成)。RecordAccumulator要做的就是将record压缩后放到与之topic关联的那个Deque的最后面。
关于record的压缩方式,kafka producer在支持了几种方式:
- ·NONE:就是不压缩。
- ·GZIP:压缩率为50%
- ·SNAPPY:压缩率为50%
- ·LZ4:压缩率为50%
在将record放到Deque中最后一个RecordBatch中的过程如下:如果最后一个recordbatch可以放的下就放,放不下就新建一个RecordBatch。
RecordBatch实际上是存储于BufferPool中,所以这个过程实际上是把record放在BufferPool中。在创建BufferPool之初,会指定BufferPool的总大小,BufferPool中每一个RecordBatch的大小等等配置。
8、唤醒发送模块
执行到上一步时,KafkaProducer#sender的处理基本算是完毕。这一步的目的就是唤醒NIO Selector。
此外,在上述步骤2~8,不论哪一步出现问题,都会抛出异常。而抛出异常时,就会被KafkaProducer捕获到,然后交由Sensor(传感器)进行处理。而Sensor通常会调用第1步中提到的interceptor chain 执行onAcknowledgement告知用户。


@Override public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { // intercept the record, which can be potentially modified; this method does not throw exceptions ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); return doSend(interceptedRecord, callback); } private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) { TopicPartition tp = null; try { throwIfProducerClosed(); // first make sure the metadata for the topic is available ClusterAndWaitTime clusterAndWaitTime; try { clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs); } catch (KafkaException e) { if (metadata.isClosed()) throw new KafkaException("Producer closed while send in progress", e); throw e; } long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs); Cluster cluster = clusterAndWaitTime.cluster; byte[] serializedKey; try { serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key()); } catch (ClassCastException cce) { throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() + " specified in key.serializer", cce); } byte[] serializedValue; try { serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value()); } catch (ClassCastException cce) { throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() + " specified in value.serializer", cce); } int partition = partition(record, serializedKey, serializedValue, cluster); tp = new TopicPartition(record.topic(), partition); setReadOnly(record.headers()); Header[] headers = record.headers().toArray(); int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(), compressionType, serializedKey, serializedValue, headers); ensureValidRecordSize(serializedSize); long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp(); log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition); // producer callback will make sure to call both 'callback' and interceptor callback Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp); if (transactionManager != null && transactionManager.isTransactional()) transactionManager.maybeAddPartitionToTransaction(tp); RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs); if (result.batchIsFull || result.newBatchCreated) { log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition) this.sender.wakeup(); } return result.future; // handling exceptions and record the errors; // for API exceptions return them in the future, // for other exceptions throw directly } catch (ApiException e) { log.debug("Exception occurred during message send:", e); if (callback != null) callback.onCompletion(null, e); this.errors.record(); this.interceptors.onSendError(record, tp, e); return new FutureFailure(e); } catch (InterruptedException e) { this.errors.record(); this.interceptors.onSendError(record, tp, e); throw new InterruptException(e); } catch (BufferExhaustedException e) { this.errors.record(); this.metrics.sensor("buffer-exhausted-records").record(); this.interceptors.onSendError(record, tp, e); throw e; } catch (KafkaException e) { this.errors.record(); this.interceptors.onSendError(record, tp, e); throw e; } catch (Exception e) { // we notify interceptor about all exceptions, since onSend is called before anything else in this method this.interceptors.onSendError(record, tp, e); throw e; } }
2.2、发送调度
KafkaProducer#sender只是将record放到BufferPool中,并没有将record发出去,而发送调度,则是由另外一个线程(Sender)来完成的。
Sender的执行过程如下:
1、取出就绪的record
这一步是检查要发送的record是否就绪:根据KafkaProducer维护的Metadata检查要每一个record要发往的Leader node是否存在。如果有不存在的,就设置为需要更新,并且这样的record认为还未就绪。以保证可以发到相关partition的leader node。
2、 取出RecordBatch,并过滤掉过期的RecordBatch
对于过期的RecordBatch,会通过Sensor通知Interceptor发送失败。
3、为要发送的RecordBatch创建请求
一个RecordBatch一个ClientRequest。
4、保留请求并发送
把请求对象保留到一个inFlightRequest 集合中。这个集合中存放的是正在发送的请求,是一个topic到Deque的Map。当发送成功,或者失败都会移除。
5、处理发送结果
如果发送失败,会尝试retry。并由Sensor调度Interceptor。
如果发送成功,会由Sensor调度Interceptor。
3、Producer实现说明
从上述处理流程中,可以看到在java client中的一些设计:
1、Interceptor Chain:用于自定义插件的接口。
2、MetaData:producer 按需以及定期的发送请求获取最新的Cluster状态信息。Producer根据这个信息可以直接将record batch发送到相关partition的Leader中。也就是在客户端完成Load balance。
3、Partitioner:分区选择工具,选择发送到哪些分区,结合Metadata,完成Load balance。
4、RecordBatch:在客户端对record压缩进RecordBatch,然后一个RecordBatch发一次。这样可以减少IO操作的次数,提高性能。
5、异步方式发送:提高用户应用性能。
4、Producer Configuration
更多Producer客户端配置参数,参照 org.apache.kafka.clients.producer.ProducerConfig
·bootstrap.servers
用于配置cluster中borker的host/port对。可以配置一项或者多项,不需要将cluster中所有实例都配置上。因为它会自动发现所有的broker。
如果要配置多项,格式是:host1:port1,host2:port2,host3:port3….
·key.serializer、value.serializer
配置序列化类名。指定的这些类都要实现Serializer接口。
·acks
为了确保message record被broker成功接收。Kafka Producer会要求Broker确认请求(发送RecordBatch的请求)完成情况。
对于message接收情况的确认,Kafka Broker支持了三种情形:1、不需要确认;2)leader接收到就确认;3)等所有可用的follower复制完毕进行确认。可以看出,这三种情况代表不同的确认级别。在Java Producer Client中,对三种情形都做了支持,上述三种情形分别对应了三个配置项:0、1、-1。其实还有一个值是all,它其实就是-1。
Kafka Producer Java Client 是如何支持这三种确认呢?
1、在为RecordBatch创建请求时,acks的值会被封装为请求头的一部分。
2、发送请求后(接收到Broker响应前),立即判断是否需要确认该请求是否完成(即该RecordBatch是否被Broker成功接收),判断依据是acks的值是否是0。如果是0,即不需要进行确认。那么就认定该请求成功完成。既然认定是成功,那么就不会进行retry了。
如果值不是0,就要等待Broker的响应了。根据响应情况,来判断请求是否成功完成。
该配置项默认值是1,即leader接收后就响应。
·buffer.memory
BufferPool Size,也就是等待发送的Record的空间大小。默认值是:33554432,即32MB。
配置项的单位是byte,范围是:[0,….]
·compression.type
Kafka提供了多种压缩类型,可选值有4个: none, gzip, snappy, lz4。默认值是none。
·retries
重试次数,值范围[0, Integer.Max]。如果是0,即便失败,也不会进行重发。
如果允许重试(即retries>0),但max.in.flight.requests.per.connection 没有设置成1。这种情况下,就可能会出现records的顺序改变的现象。例如:一个prodcuder client的sender线程在一次轮询中,如果有两个recordbatch都要发送到同一个partition中,此时它们肯定是发往同一个broker的,并且是用的同一个TCP connection。如果出现RecordBatch1先发,但是发送失败,RecordBatch2紧接着RecordBatch1发送,它是发送成功的。然后RecordBatch1会进行重发。这样一来,就出现了broker接收到的顺序是RecordBatch2先于RecordBatch1的情况。
·batch.size
RecordBatch的最大容量。默认值是16384(16KB)。
·client.id
逻辑名,client给broker发请求是会用到。默认值是:””。
·connections.max.idle.ms
Connection的最大空闲时间。默认值是540000 (9 min)
·linger.ms
延迟。默认值:0,即不延迟。
·max.block.ms
当需要的metadata未到达之前(例如要发送的record的topic,在Client中还没有相关记录时),执行KafkaProducer#send时,内部处理会等待MetaData的到达。这是个阻塞的操作。为了防止无限等待,设置这个阻塞时间是必要的。范围:[0, Long.MAX]
max.request.size
最大请求长度,在将record压缩到RecordBatch之前会进行校验。超过这个大小会抛出异常。
·partitioner.class
用于自定义partitioner算法。默认值是:
org.apache.kafka.clients.producer.internals.DefaultPartitioner
·receive.buffer.byte
TCP receiver buffer的大小。取值范围:[-1, …]。这个配置项的默认值是32768(即 32KB)。
如果设置为-1,则会采用操作系统的默认值。
·request.timeout.ms
最大请求时长。因为发起请求后,会等待broker的响应,如果超过这个时间就认为请求失败。
·timeout.ms
这个时间配置的是follower到leader的ack超时时间。这个时间和producer发送的请求的网络无关。
·block.on.buffer.full
当bufferPool用完后,如果client还在使用KafkaProducer发送record,要么是BufferPool拒绝接收,要么是抛出异常。
这个配置是默认值是false,也就是当bufferpool满时,不会抛出BufferExhaustException,而是根据max.block.ms进行阻塞,如果超时抛出TimeoutExcpetion。
如果这个属性值是true,则会把max.block.ms值设置为Long.MAX。另外该配置为true时,metadata.fetch.time.ms将不会生效了。
·interceptor.classes
自定义拦截器类。默认情况下没有指定任何的interceptor。
·max.in.flight.requests.per.connection
每个连接中处于发送状态的请求数的最大值。默认值是5。范围是[1, Integer.MAX]
·metric.reporters
MetricReporter的实现类。默认情况下,会自动的注册JmxReporter。
·metrics.num.samples
计算metric时的采样数。默认值是2。范围:[1,Integer.MAX]
·metrics.sample.window.ms
采样的时间窗口。默认值是30000(30s)。范围:[0, Long.MAX]
参照:
https://www.cnblogs.com/f1194361820/p/6048429.html