一、前言
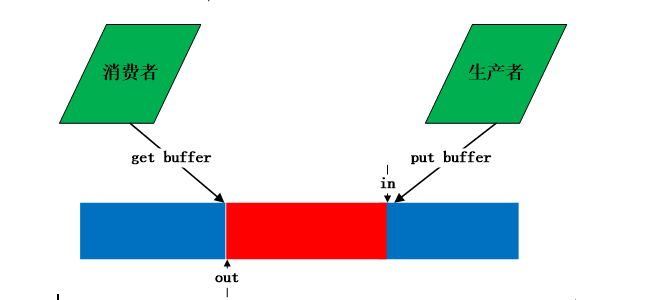
缓冲区在文件系统中经常用到,通过缓冲区缓解cpu读写内存和读写磁盘的速度。例如一个进程A产生数据发给另外一个进程B,进程B需要对进程A传的数据进行处理并写入文件,如果B没有处理完,则A要延迟发送。为了保证进程A减少等待时间,可以在A和B之间采用一个缓冲区,A每次将数据存放在缓冲区中,B每次冲缓冲区中取。这是典型的生产者和消费者模型,缓冲区中数据满足FIFO特性,因此可以采用队列进行实现。Linux内核的kfifo正好是一个环形队列,可以用来当作环形缓冲区。生产者与消费者使用缓冲区如下图所示:
二、kfifo概述
| 源代码版本 | 2.6.32.63 |
| kfifo的头文件 | include/linux/kfifo.h |
| kfifo的源文件 | kernel/kfifo.c |
kfifo是一种"First In First Out"数据结构,它采用了前面提到的环形缓冲区来实现,提供一个无边界的字节流服务。采用环形缓冲区的好处是,当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝提高效率。更重要的是,kfifo采用并行无锁技术,kfifo实现的单生产者/单消费者模式的共享队列是不需要加锁同步的。
struct kfifo { unsigned char *buffer; /* the buffer holding the data : 用于存放数据的缓存 */ unsigned int size; /* the size of the allocated buffer : 空间的大小,在初化时将它向上扩展成2的幂,为了高效的进行与操作取余,后面会详解 */ unsigned int in; /* data is added at offset (in % size) unsigned int out; /* data is extracted from off. (out % size) :一起构成一个循环队列。 in指向buffer中队头,而且out指向buffer中的队尾 */ spinlock_t *lock; /* protects concurrent modifications :如果使用不能保证任何时间最多只有一个读线程和写线程,需要使用该lock实施同步*/*/ };
它的结构图:
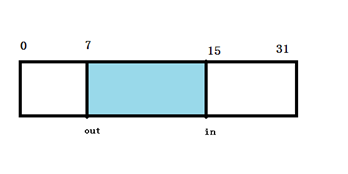
这看起来与普通的环形缓冲区没有什么差别,但是让人叹为观止的地方就是它巧妙的用 in 和 out 的关系和特性,处理各种操作,下面我们来详细分析。
三、kfifo内存分配和初始化
首先,看一个很有趣的函数,判断一个数是否为2的次幂,按照一般的思路,求一个数n是否为2的次幂的方法为看 n % 2 是否等于0, 我们知道“取模运算”的效率并没有 “位运算” 的效率高,有兴趣的同学可以自己做下实验。下面再验证一下这样取2的模的正确性,若n为2的次幂,则n和n-1的二进制各个位肯定不同 (如8(1000)和7(0111)),&出来的结果肯定是0;如果n不为2的次幂,则各个位肯定有相同的 (如7(0111) 和6(0110)),&出来结果肯定为0。是不是很巧妙?
bool is_power_of_2(unsigned long n) { return (n != 0 && ((n & (n - 1)) == 0)); }
再看下kfifo内存分配和初始化的代码,前面提到kfifo总是对size进行2次幂的圆整,这样的好处不言而喻,可以将kfifo->size取模运算可以转化为与运算,如下:
kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
/* 创建队列 */ struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size, gfp_t gfp_mask, spinlock_t *lock) { struct kfifo *fifo; /* size must be a power of 2 :判断是否为2的幂*/ BUG_ON(!is_power_of_2(size)); fifo = kmalloc(sizeof(struct kfifo), gfp_mask); if (!fifo) return ERR_PTR(-ENOMEM); fifo->buffer = buffer; fifo->size = size; fifo->in = fifo->out = 0; fifo->lock = lock; return fifo; } /* 分配空间 */ struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock) { unsigned char *buffer; struct kfifo *ret; if (!is_power_of_2(size)) { /* 判断是否为2的幂 */ BUG_ON(size > 0x80000000); size = roundup_pow_of_two(size); /* 如果不是则向上扩展成2的幂 */ } buffer = kmalloc(size, gfp_mask); if (!buffer) return ERR_PTR(-ENOMEM); ret = kfifo_init(buffer, size, gfp_mask, lock); if (IS_ERR(ret)) kfree(buffer); return ret; }
四、kfifo并发无锁奥秘---内存屏障
为什么kfifo实现的单生产者/单消费者的共享队列是不需要加锁同步的呢?天底下没有免费的午餐,下面就来看看kfifo实现并发无锁的奥秘。
程序在运行时内存实际的访问顺序和程序代码编写的访问顺序不一定一致,这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。内存乱序访问主要发生在两个阶段:
(1)编译时,编译器优化导致内存乱序访问(指令重排)
(2)运行时,多 CPU 间交互引起内存乱序访问
很多时候,编译器和 CPU 引起内存乱序访问不会带来什么问题,但一些特殊情况下,程序逻辑的正确性依赖于内存访问顺序,这时候内存乱序访问会带来逻辑上的错误。
(1)编译时内存乱序访问:在编译时,编译器对代码做出优化时可能改变实际执行指令的顺序(例如 gcc 下 O2 或 O3 都会改变实际执行指令的顺序):
// test.cpp int x, y, r; void f() { x = r; y = 1; }
编译器优化的结果可能导致 y = 1 在 x = r 之前执行完成。
(2)运行时内存乱序访问:在运行时,CPU 虽然会乱序执行指令,但是在单个 CPU 的上,硬件能够保证程序执行时所有的内存访问操作看起来像是按程序代码编写的顺序执行的。CPU执行指令分:取址、译码等等,为了更快的执行指令,CPU采取了流水线的执行方式,编译器在编译代码时为了使指令更适合CPU的流水线执行方式以及多CPU执行,原本的指令就会出现乱序的情况。在乱序执行时,一个处理器真正执行指令的顺序由可用的输入数据决定,而非程序员编写的顺序。
// thread 1 while (!ok); do(x); // thread 2 x = 42; ok = 1;
此段代码中,ok 初始化为 0,线程 1 等待 ok 被设置为 1 后执行 do 函数。假如线程 2 对内存的写操作乱序执行,也就是 x 赋值后于 ok 赋值完成,那么 do 函数接受的实参就很可能出乎程序员的意料,不为 42!
软件可通过读写屏障强制内存访问次序。读写屏障像一堵墙,所有在设置读写屏障之前发起的内存访问,必须先于在设置屏障之后发起的内存访问之前完成,确保内存访问按程序的顺序完成。Linux内核提供的内存屏障API函数说明如下:
mb() 适用于多处理器和单处理器的内存屏障。
rmb() 适用于多处理器和单处理器的读内存屏障。
wmb() 适用于多处理器和单处理器的写内存屏障。
smp_mb() 适用于多处理器的内存屏障。
smp_rmb() 适用于多处理器的读内存屏障。
smp_wmb() 适用于多处理器的写内存屏障。
内存屏障(Memory barrier)可用于多处理器和单处理器系统,如果仅用于多处理器系统,就使用smp_xxx函数,在单处理器系统上,它们什么都不要。Memory barrier 能够让 CPU 或编译器在内存访问上有序,一个 Memory barrier 之前的内存访问操作必定先于其之后的完成:
// thread 1 while (!ok); do(x); // thread 2 x = 42; ok = 1; smp_wmb();
这样就能保证thread1在判断ok为1时,x一定已经设置为42了。
五、kfifo的入队 __kfifo_put和出队__kfifo_get操作
__kfifo_put是入队操作,它先将数据放入buffer中,然后移动in的位置,其源代码如下:
1 unsigned int __kfifo_put(struct kfifo *fifo, 2 const unsigned char *buffer, unsigned int len) 3 { 4 unsigned int l; 5 6 len = min(len, fifo->size - fifo->in + fifo->out); 7 8 /* 9 * Ensure that we sample the fifo->out index -before- we 10 * start putting bytes into the kfifo. 11 */ 12 13 smp_mb(); 14 15 /* first put the data starting from fifo->in to buffer end */ 16 l = min(len, fifo->size - (fifo->in & (fifo->size - 1))); 17 memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l); 18 19 /* then put the rest (if any) at the beginning of the buffer */ 20 memcpy(fifo->buffer, buffer + l, len - l); 21 22 /* 23 * Ensure that we add the bytes to the kfifo -before- 24 * we update the fifo->in index. 25 */ 26 27 smp_wmb(); 28 29 fifo->in += len; 30 31 return len; 32 }
6行,环形缓冲区的剩余容量为fifo->size - fifo->in + fifo->out,让写入的长度取len和剩余容量中较小的,避免写越界;
13行,加内存屏障,保证在开始放入数据之前,fifo->out取到正确的值(另一个CPU可能正在改写out值)
16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1),所以fifo->size - (fifo->in & (fifo->size - 1)) 即位 fifo->in 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为需要拷贝l 字节到fifo->buffer + fifo->in的位置上。
17行,拷贝l 字节到fifo->buffer + fifo->in的位置上,如果l = len,则已拷贝完成,第20行len – l 为0,将不执行,如果l = fifo->size - (fifo->in & (fifo->size - 1)) ,则第20行还需要把剩下的 len – l 长度拷贝到buffer的头部。
27行,加写内存屏障,保证in 加之前,memcpy的字节已经全部写入buffer,如果不加内存屏障,可能数据还没写完,另一个CPU就来读数据,读到的缓冲区内的数据不完全,因为读数据是通过 in – out 来判断的。
9行,注意这里 只是用了 fifo->in += len而未取模,这就是kfifo的设计精妙之处,这里用到了unsigned int的溢出性质,当in 持续增加到溢出时又会被置为0,这样就节省了每次in向前增加都要取模的性能,锱铢必较,精益求精,让人不得不佩服。
__kfifo_get是出队操作,它从buffer中取出数据,然后移动out的位置,其源代码如下:
unsigned int __kfifo_get(struct kfifo *fifo, unsigned char *buffer, unsigned int len) { unsigned int l; len = min(len, fifo->in - fifo->out); /* * Ensure that we sample the fifo->in index -before- we * start removing bytes from the kfifo. */ smp_rmb(); /* first get the data from fifo->out until the end of the buffer */ l = min(len, fifo->size - (fifo->out & (fifo->size - 1))); memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l); /* then get the rest (if any) from the beginning of the buffer */ memcpy(buffer + l, fifo->buffer, len - l); /* * Ensure that we remove the bytes from the kfifo -before- * we update the fifo->out index. */ smp_mb(); fifo->out += len; return len; }
6行,可去读的长度为fifo->in – fifo->out,让读的长度取len和剩余容量中较小的,避免读越界;
13行,加读内存屏障,保证在开始取数据之前,fifo->in取到正确的值(另一个CPU可能正在改写in值)
16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->out % kfifo->size 可以转化为 kfifo->out & (kfifo->size – 1),所以fifo->size - (fifo->out & (fifo->size - 1)) 即位 fifo->out 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为从fifo->buffer + fifo->in到末尾所要去读的长度。
17行,从fifo->buffer + fifo->out的位置开始读取l长度,如果l = len,则已读取完成,第20行len – l 为0,将不执行,如果l =fifo->size - (fifo->out & (fifo->size - 1)) ,则第20行还需从buffer头部读取 len – l 长。
27行,加内存屏障,保证在修改out前,已经从buffer中取走了数据,如果不加屏障,可能先执行了增加out的操作,数据还没取完,令一个CPU可能已经往buffer写数据,将数据破坏,因为写数据是通过fifo->size - (fifo->in & (fifo->size - 1))来判断的 。
29行,注意这里 只是用了 fifo->out += len 也未取模,同样unsigned int的溢出性质,当out 持续增加到溢出时又会被置为0,如果in先溢出,出现 in < out 的情况,那么 in – out 为负数(又将溢出),in – out 的值还是为buffer中数据的长度。
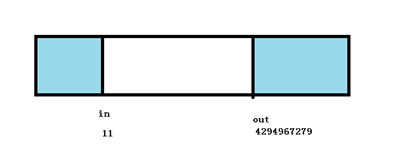
这里图解一下 in 先溢出的情况,size = 64, 写入前 in = 4294967291, out = 4294967279 ,数据 in – out = 12;

写入 数据16个字节,则 in + 16 = 4294967307,溢出为 11,此时 in – out = –4294967268,溢出为28,数据长度仍然正确, 由此可见,在这种特殊情况下,这种计算仍然正确,是不是让人叹为观止,妙不可言?
六、扩展
kfifo设计精巧,妙不可言,但主要为内核提供服务,内存屏障函数也主要为内核提供服务,并未开放出来,但是我们学习到了这种设计巧妙之处,就可以依葫芦画瓢,写出自己的并发无锁环形缓冲区,这将在下篇文章中给出,至于内存屏障函数的问题,好在gcc 4.2以上的版本都内置提供__sync_synchronize()这类的函数,效果相差不多。
转自《眉目传情之匠心独运的kfifo》