某个生产数据库(oracle)中单表记录了上亿的车辆定位数据,应用系统的轨迹回放功能已出现明显的加载卡顿现象(优化了索引,查询指定车辆一段时间内的定位数据,差不多也需要15秒左右)。考虑到常规分表的方案治标不治本、同时也是为其他更大量级数据项目积累经验,我们决定尝试使用hbase来存储定位数据。要做的第一步就是需要将数据导入到hbase里。由于我们已经建立了CDH环境,且之前已经通过里面的streamset套件成功实现了kafka定位数据导入到hive,故一开始的决定是继续使用streamset来完成数据导入。然而这种方案折腾了很久也没走通,也是各种坑(踩坑参考这个帖子:https://blog.csdn.net/JJBOOM425/article/details/108093283),且受运行环境限制我们没法对oracle进行基础配置,最后不得不转而考虑使用kettle。
环境说明:
——Kettle8.3,windows客户端
——源数据库:Oracle11g
——目标数据库:CDH6.3.2、HBase2.1.0,集群5个节点
(说明:kettle现在已经不叫这个名字了,官方的名字是pentaho data integration。kettle的版本与支持的cdh版本是有对应关系的,如果下载错了,那里面对应的插件驱动可能版本不对导致各种错误。官方说明目前kettle8.3只支持cdh6.1、6.2,我们的是cdh6.3,还好最后实测是支持的。还好还好,嘿嘿)
首先在kettle里新建一个转换,先在输入下添加一个表输入,用来获取oracle中的数据;然后在bigdata下添加一个hbase output,用来接收oracle数据,写入hbase。
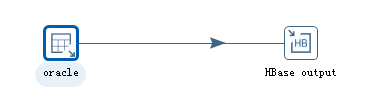
具体配置如下:
1、表输入
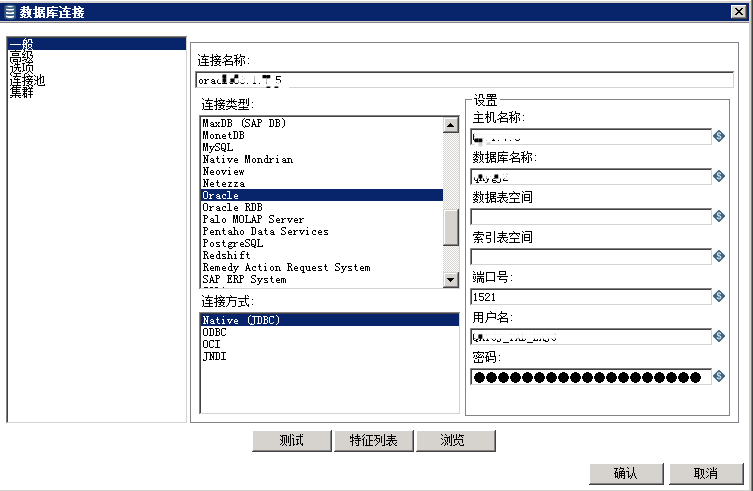
jdbc链接配置好:
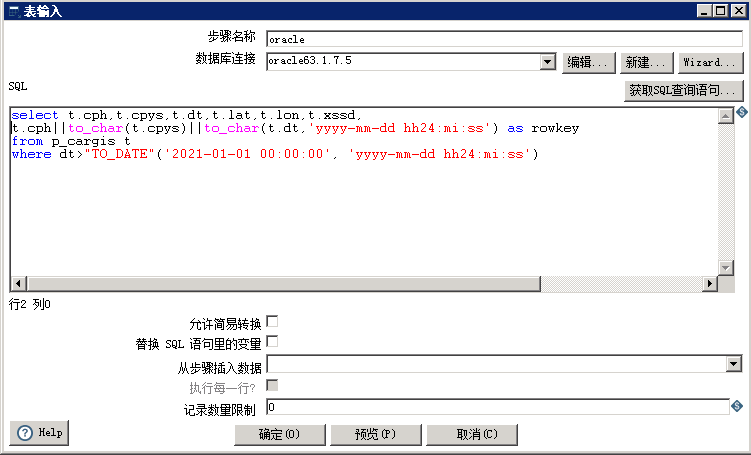
sql语句,因为是测试用,所以将2021年1月1号之后的数据都取过来。实际要用的时候,应该是获取增量数据。后续再完善。注意这里取数的时候,用车牌号+车牌颜色+定位记录的时间3个字段组成了一个名为‘rowkey’的字段,用来作为hbase表中的RowKey。下面在hbase配置中还会说明。
2、hbase output:
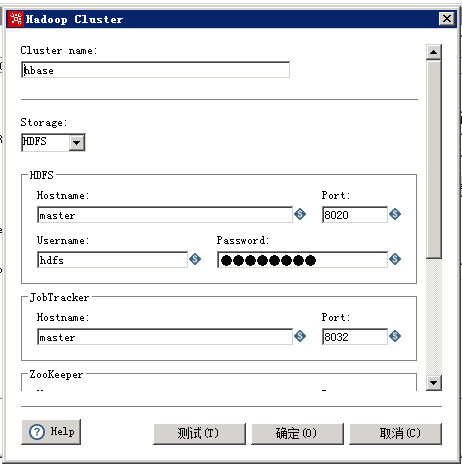
首先新建hadoop cluster的链接配置。这个过程很多坑。
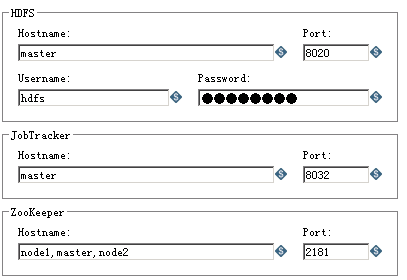
kettle会默认给出hadoop中服务的hostname、port,如果你没有改过,那恭喜你,直接就能用。这一块根据cdh中的实际配置来填写就好。其中我理解hdfs、jobtracker、zookeeper这3项是必须的,其他的oozie、kafka没必要。
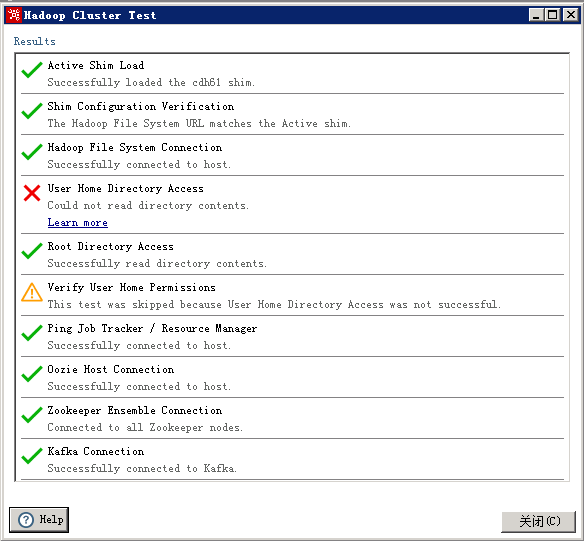
配置完成后测试一下看看结果(那个user home directory access测试没通过,不影响。oozie、kafka也不影响)。如果你看到下图恭喜你连通性OK了。如果红叉,一个个改吧。
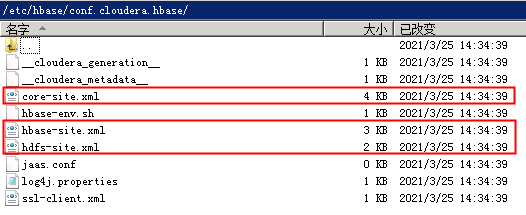
接着你需要去服务器上找一些必要的配置文件,kettle要用到它们。你需要去服务器master节点上找到这个文件,一般是在 /etc/hbase/conf.cloudera.hbase/ 下。参照其他帖子,同时还有几个配置文件需要copy。如下图所示,可以把红框里这6个文件都copy到本机目录先保存。
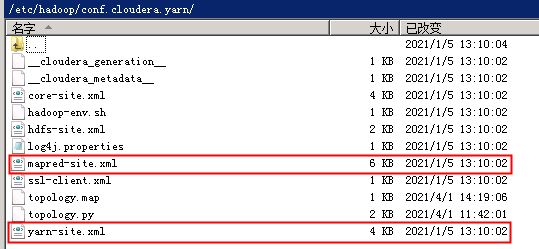
之后将这6个xml配置文件copy到kettle的pluginspentaho-big-data-pluginhadoop-configurationscdh61 目录下。
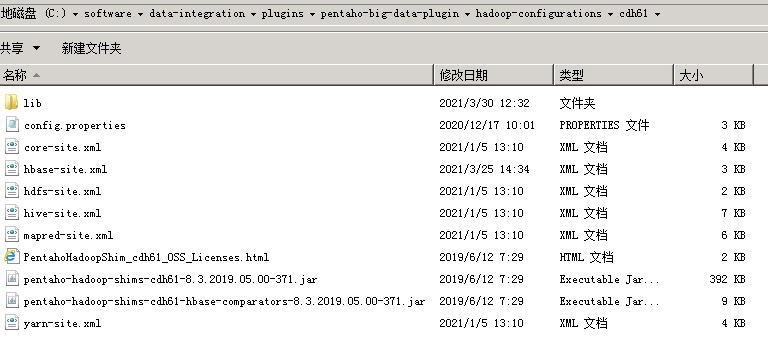
进入lib目录,将client、pmr目录中的驱动全部copy放到lib目录下。
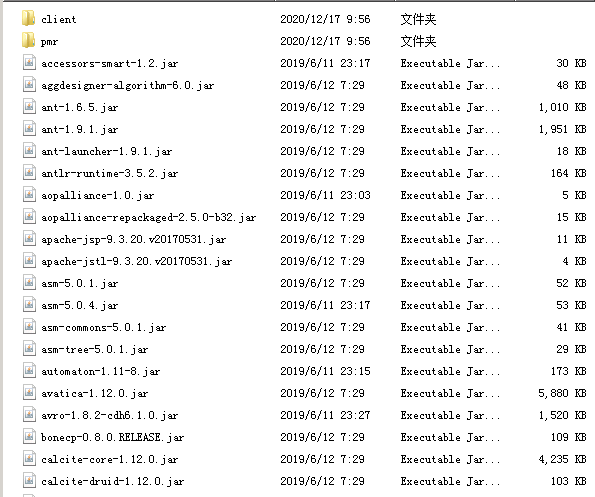
接着修改pentaho-big-data-plugin目录下的plugin.properties文件,将active.hadoop.configuration设置为cdh61,跟你上面那个目录名保持一致,这样kettle就知道生效的配置文件跟驱动在哪个目录下了。
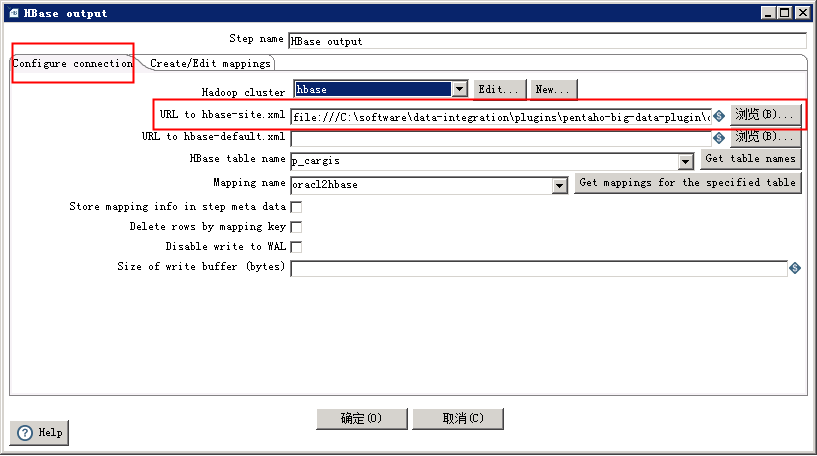
再回到hbase output的主界面,在configure connection中,浏览添加hbase-site.xml文件。注意因为是windows环境,你需要在前面手工添加file:///
切换到crate/edit mappings,点击get table names,如果一切顺利的话,你应该能在下拉列表里选择数据导入目标表(hbase中的表创建这一步可以通过hbase shell手工完成,此处略)。注意,你自己手写表名是无效的,如果get table names没有,或者出错,那就慢慢找原因吧,我在这一步卡了好久。我的经验,多半是因为xml文件的版本不对,或者文件位置没放对,或者改了kettle配置没重启等原因导致的(前提是kettle与cdh的版本是对应的,否则免谈,或者你自己去下载对应的驱动jar包)。
按照我标注的顺序操作吧。其中第4步中,将key标记为Y,这个就是hbase表中的Rowkey。第5步中选择string类型,我们是按照车牌号+车牌颜色+时间组成字符串来作为rowkey,在后续的实际应用系统中,也是通过这个rowkey来快速查询定位数据。hbase的rowkey设计是个关键因素,需要结合实际的查询场景来设计。
保存完这个mapping,没有意外的话,kettle会将这个配置信息,作为一张表的数据写入hbase里。
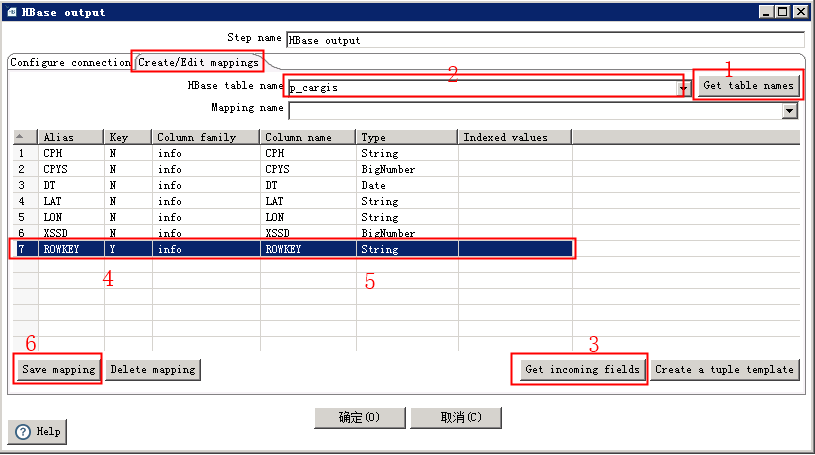
再回到前面的页签,分别通过get table names 和 get mappings for the specified table来或者hbase的表名跟映射名。注意还是手写无效哦。到此,全部配置就结束了。
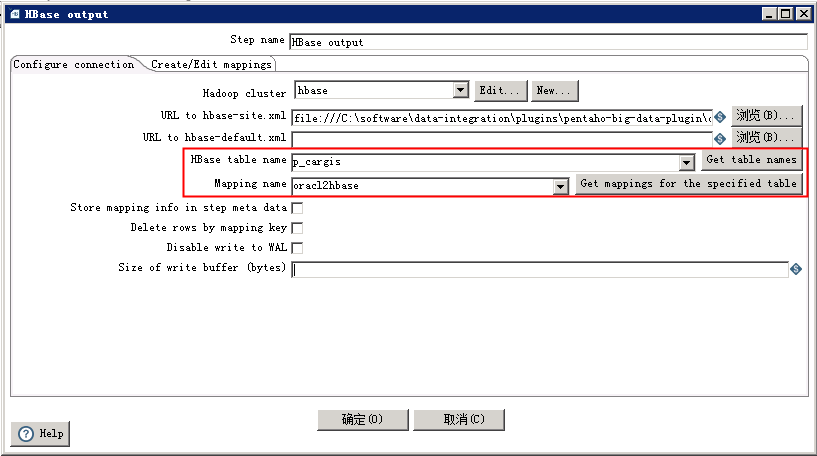
跑起来吧:
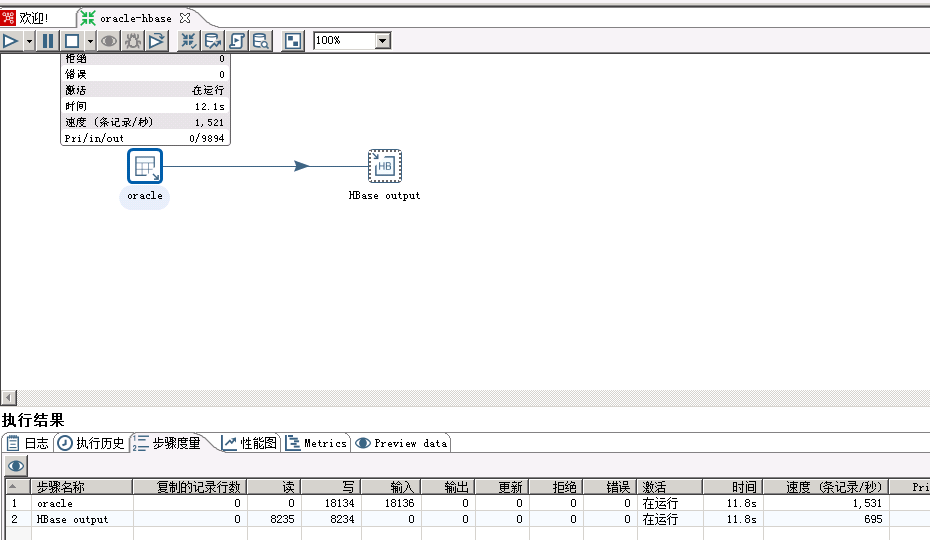
不容易啊,终于跑起来了。最后附上生产环境真实的配置图:
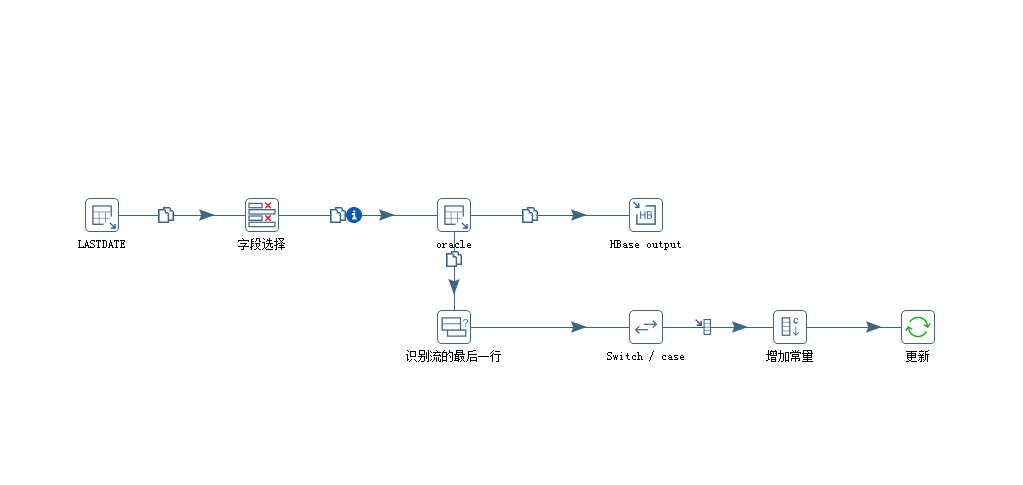
kettle作业设置略。