1 随机森林
bagging的好处是降低各个子分类器的variance,而决策树又是对数据敏感的算法,variance比较大。因此我们很自然地就把bagging用到了决策树。也就是基本的随机森林算法:

随机森林的好处是:
(1)每棵树并行化学习,非常有效率
(2)继承了CART的好处
(3)弥补了决策树variance大的缺点。

扩展的随机森林(这部分没怎么听懂):
2 OOB错误
在做bagging时,每一轮bootstrap都会有一些数据没有被抽到,这些数据没有参与到当前这个小g的训练,称为out-of-bag(OOB)数据:
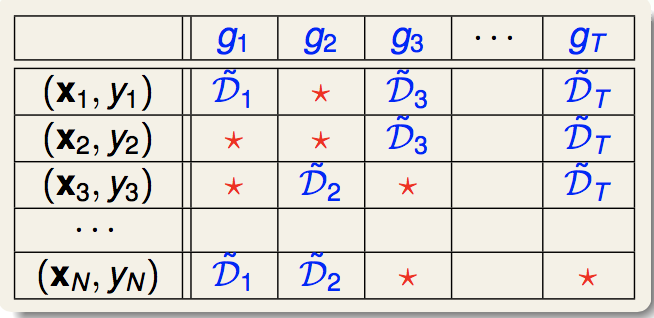
其中红星就是OOB数据。
所谓OOB错误,就是类似于留一交叉验证。以每个数据作为单样本验证集,所有以这个数据为OOB的小g作一个平均,称为G-,计算G-在这个验证数据上的error。OOB错误就是对所有这些G-错误的平均:

因此,我们可以不用划分训练集和验证集,通过计算OOB错误,就能选择不同参数的随机森林:

实际中,OOB错误对于衡量大G的表现相当的准确。
3 特征选择
做特征选择的好处是:1使后续的训练更有效率;2去掉了很多噪声特征,提高了模型的泛化能力;3可解释性。

特征选择的方式一般是求解特征的重要性。然后选出重要性最高的前K个特征来。
对于线性模型,可直接根据学出的权重来判断该特征是否重要:

随机森林也可以做特征选择。特征i的重要性如下计算:
![]()
其中红色部分,是把验证数据的特征i加入噪声,这里是把所有对于当前的小g OOB的数据的特征i进行重新排列,然后计算打乱后的验证集的OOB。这种重排列方式的优点是,可以大致维持原来特征i的分布,也被称为permutation test 。之所以可以用这个方式来计算特征i的重要性是因为,若给特征i加上噪声后,G的OOB验证误差有很大改变,则说明该特征对于样本的分类结果影响很大,也就是重要性越大。

这边遗留一个问题,其他的模型,通过划分训练集和验证集,做permutation test,不也是能做特征选择吗?
4
这边给一个图,左边是单个决策树,右边是随机森林。可以看出,在有噪声的情况下,随机森林这种使用多颗树投票的机制,可以抵消掉一些噪声,防止过拟合:
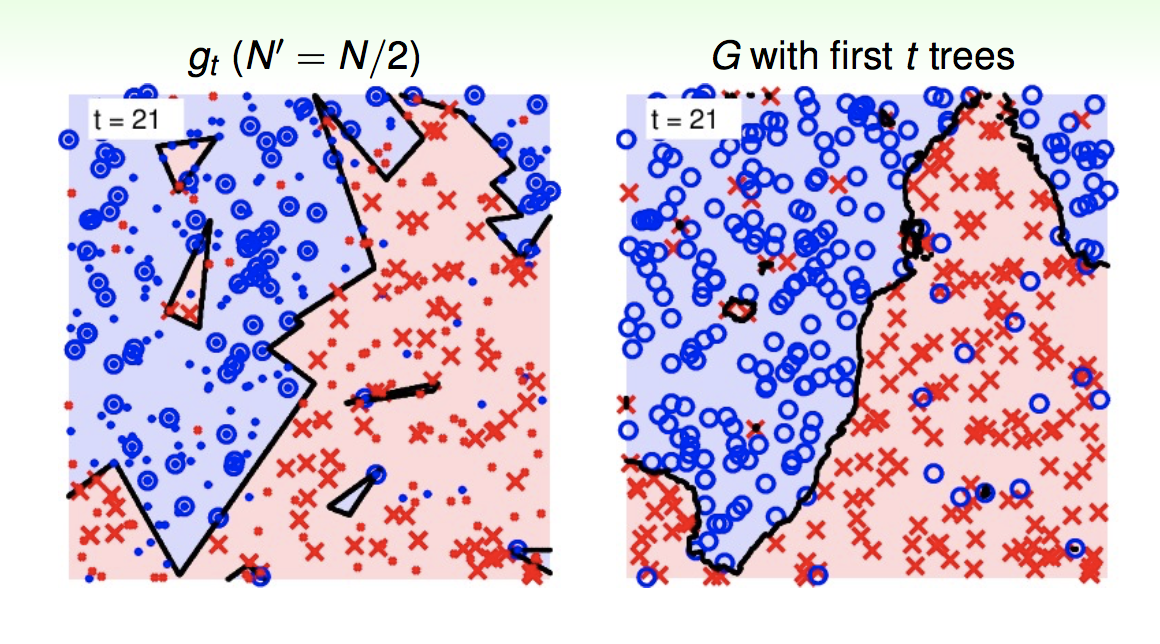
最后一个问题是,随机森林一般取多少颗树?
理论上是越多越好。实际上,要看当前G的效果是否会由于多加或少加一颗树稳定,如果不稳定,就要继续增加树的数量。不然就够了。