14.1 相关命令介绍
Redis的set实现了无序集合,集合成员唯一。set底层基于dict和intset,在学习集合命令前,需要先了解dict和intset的结构;
集合元素为字符串和数字,分别用dict和intset存储。对于单个集合,Redis实现了元素的新增、删除、遍历等操作;对于多个集合,Redis实现了集合间求交集、并集和差集等操作。
1.添加成员
sadd命令的作用是为集合添加新成员。
格式:sadd key member [member ...]
说明: 将一个或多个元素加入到集合key当中,返回加入成功的个数。
示例:>sadd testKey a b
源码分析:
函数入口在saddCommand。
{"sadd",saddCommand,-3,"wmF",0,NULL,1,1,1,0,0},
saddCommond基本的校验后,先得到一个有效的set,并将待添加元素依次添加进set:
void saddCommand(client *c) {
robj *set;
int j, added = 0;
set = lookupKeyWrite(c->db,c->argv[1]);
if (set == NULL) {
set = setTypeCreate(c->argv[2]->ptr);
dbAdd(c->db,c->argv[1],set);
} else {
if (set->type != OBJ_SET) {
addReply(c,shared.wrongtypeerr);
return;
}
}
for (j = 2; j < c->argc; j++) {
if (setTypeAdd(set,c->argv[j]->ptr)) added++;
}
...
}
源码的核心函数是setTypeAdd,由于集合底层有两种实现方式(dict和intset)'
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) { //类型
//① 当encoding方式为OBJ_ENCODING_HT时,set的底层用的是字典,将key直接添加进dict。注意的是,用dict存储集合元素时,元素值存储于字典的key中,字典的value值为null
dict *ht = subject->ptr;
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL); //字典的value值为null
return 1;
}
} else if (subject->encoding == OBJ_ENCODING_INTSET) { //INTSET类型
// ②当encoding方式为OBJ_ENCODING_INTSET时,又有两种情况:若新增的元素本身非数字(value转long long失败),需要通过setTypeConvert转化后再存储;若新增的元素本身是数字,则用intsetAdd新增元素。且当新增成功,但intset的元素个数过多(个数大于server.set_max_intset_entries时。该参数可配置,默认为512),同样会触发setType-Convert转 化:
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
uint8_t success = 0;
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
//intset转dict.
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
//value转long long失败,触发转化 intset转dict
setTypeConvert(subject,OBJ_ENCODING_HT);
//intset转dict
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
serverPanic("Unknown set encoding");
}
return 0;
}
setTypeConvert将集合的编码方式由OBJ_ENCODING_INTSET改为OBJ_ENCODING_HT。其思路是新建一个dict,遍历旧intset中的所有元素,并添加至新dict中。
void setTypeConvert(robj *setobj, int enc) {
dict *d = dictCreate(&setDictType,NULL);
dictExpand(d,intsetLen(setobj->ptr));
si = setTypeInitIterator(setobj);
while (setTypeNext(si,&element,&intele) != -1) {
element = sdsfromlonglong(intele);
serverAssert(dictAdd(d,element,NULL) == DICT_OK);
}
...
}
为了避免转化过程中发生字典的rehash操作,代码中用dictExpand主动扩容;
2.删除成员
srem命令的作用是删除集合中的指定成员。
格式:srem key member [member ...]
说明: 删除集合key中的一个或多个元素,返回删除成功的元素数量。
示例:>srem testKey testValue
源码分析: 函数入口在sremCommand。
sremCommand函数与saddCommand函数几乎一致:同样完成基本的校验后,得到一个有效的set,调用setTypeRemove方法,将待删除元素依次从set中移除
void sremCommand(client *c) {
... //参数校验
for (j = 2; j < c->argc; j++) {
if (setTypeRemove(set,c->argv[j]->ptr)) {
deleted++;
if (setTypeSize(set) == 0) {
dbDelete(c->db,c->argv[1]);
//keyremoved标识,用于最后通知notifyKeyspaceEvent。
keyremoved = 1;
break;
}
}
} ....
}
主要的移除逻辑在setTypeRemove中完成。移除时同样分OBJ_ENCODING_HT和OBJ_ENCODING_INTSET两种情况处理
int setTypeRemove(robj *setobj, sds value) {
long long llval;
if (setobj->encoding == OBJ_ENCODING_HT) {
//若encoding为OBJ_ENCODING_HT时,则调用dictDelete处理删除元素时,会检查字典容量,字典容量不足也会触发扩容操作
if (dictDelete(setobj->ptr,value) == DICT_OK) {
if (htNeedsResize(setobj->ptr)) dictResize(setobj->ptr);
return 1;
}
} else if (setobj->encoding == OBJ_ENCODING_INTSET) {
//当encoding为OBJ_ENCODING_INTSET时,调用intsetRemove处理
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
int success;
setobj->ptr = intsetRemove(setobj->ptr,llval,&success);
if (success) return 1;
}
} .....
return 0;
}
3.(随机)获取成员
随机获取集合一个或多个成员的命令。
(1)spop/srandmember命令
spop与srandmember命令都会返回一个随机元素,故统一讲解。
不同之处,spop会将该返回的元素从集合中移除,而srandmember不会。
spop命令:
说明: 删除并返回集合中的一个或多个随机元素。
格式:spop key [count]
示例:> smembers test
源码分析: 函数入口在spopCommand
处理移除并返回一个元素的逻辑:
先校验arg中的set,之后通过setTypeRandomElement返回一个随机元素,最后将该元素从集合中删除。删除时会检查集合编码,若集合encoding为OBJ_ENCODING_INTSET,则调用intsetRemove函数删除;否则调用setTypeRemove函数删除。
void spopCommand(client *c) {
robj *set, *ele, *aux;
sds sdsele;
int64_t llele;
int encoding;
//参数校验
if (c->argc == 3) {
spopWithCountCommand(c); //移除并返回多个元素的函数入口
return;
} else if (c->argc > 3) {
addReply(c,shared.syntaxerr);
return;
}
/* set不存在或类型错误则返回空 */
if ((set = lookupKeyWriteOrReply(c,c->argv[1],shared.null[c->resp]))
== NULL || checkType(c,set,OBJ_SET)) return;
/* 随机获取一个元素。当元素是数字时,返回值保存在*llele中;
当元素是字符串时,返回值保存在*sdsele中 ;
集合有intset和字典两种实现,setTypeRandomElement调用不同的随机获取函数: */
encoding = setTypeRandomElement(set,&sdsele,&llele);
/* 删除元素,获取到随机元素后,重新创建了变量ele来保存它 */
if (encoding == OBJ_ENCODING_INTSET) {
ele = createStringObjectFromLongLong(llele);
set->ptr = intsetRemove(set->ptr,llele,NULL);
} else {
ele = createStringObject(sdsele,sdslen(sdsele));
setTypeRemove(set,ele->ptr);
}
...
}
字典和inset的随机函数分别为dictGetRandomKey与intsetRandom。其中dictGetRan-domKey做了两次随机,第1次随机找到非空的bucket,bucket存放着一个链表,第2次随机返回bucket链表中的元素。
处理返回多个元素的逻辑:
函数入口在spopWithCountCommand,Redis分4种情况讨论:
① 随机元素数量 =0 ,返回空("empty list or set"):
if (count == 0) {
addReply(c,shared.emptyset[c->resp]);
return;
}
②随机元素数量 >= 集合基数 时,返回整个集合,并删除集合:
if (count >= size) {
/* 调用求并集函数,返回本集合所有元素 */
sunionDiffGenericCommand(c,c->argv+1,1,NULL,SET_OP_UNION);
/* 删除集合 */
dbDelete(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",c->argv[1],c->db->id);
}
③0< 随机元素数量< 某个临界值 , Redis循环调用random及remove函数查询并删除元素:
if (remaining*SPOP_MOVE_STRATEGY_MUL > count) {
while(count--) {
/*找出和删除*/
encoding = setTypeRandomElement(set,&sdsele,&llele);
if (encoding == OBJ_ENCODING_INTSET) {
addReplyBulkLongLong(c,llele);
objele = createStringObjectFromLongLong(llele);
set->ptr = intsetRemove(set->ptr,llele,NULL); //删除
} else {
addReplyBulkCBuffer(c,sdsele,sdslen(sdsele));
objele = createStringObject(sdsele,sdslen(sdsele));
setTypeRemove(set,sdsele); //删除
}
...
}
}
④ 某个临界值< 随机元素数量< 集合基数, Redis将"反向处理"——创建一个新的set,将"剩余"元素加入该集合,返回原集合并在删除原集合后,将新集合转化为原集合: (看上去更省时省力)
while(remaining--) {
/* 将剩余元素从原集合中删除,并写入新集合 */
encoding = setTypeRandomElement(set,&sdsele,&llele);
if (encoding == OBJ_ENCODING_INTSET) {
sdsele = sdsfromlonglong(llele);
} else {
sdsele = sdsdup(sdsele);
}
if (!newset) newset = setTypeCreate(sdsele);
setTypeAdd(newset,sdsele); //写入新集合
setTypeRemove(set,sdsele); //从原集合删除
sdsfree(sdsele);
}
/* 迭代原集合,将集合元素写入client */
setTypeIterator *si;
si = setTypeInitIterator(set);
while((encoding = setTypeNext(si,&sdsele,&llele)) != -1) {
if (encoding == OBJ_ENCODING_INTSET) {
addReplyBulkLongLong(c,llele);
objele = createStringObjectFromLongLong(llele);
} else {
addReplyBulkCBuffer(c,sdsele,sdslen(sdsele));
objele = createStringObject(sdsele,sdslen(sdsele));
} ...
}
setTypeReleaseIterator(si);
/* 新集合覆盖原集合 */
dbOverwrite(c->db,c->argv[1],newset);
}
临界值的计算公式如下 :
unsigned long remaining = size-count; //剩余元素数量 = 集合容量-返回的随机元素数量Elements left after SPOP.
if (remaining*SPOP_MOVE_STRATEGY_MUL > count) //SPOP_MOVE_STRATEGY_MUL是系数,值为5
简单来说,当返回的随机元素数量大于集合剩余元素数量的5倍时,Redis选择"反向处理"。
srandmember命令:
格式:srandmember key [count]
说明: 返回集合中的一个或多个随机元素。
示例:> smembers test
>srandmember test
源码分析:
srandmember与spop几乎一致,调用setTypeRandomElement函数,去掉了删除逻辑。
(2)smembers命令
格式:smembers key
说明: 返回集合key中的所有成员。不存在的key被视为空集合。
示例:> smembers test
源码分析: 函数入口在sinterCommand。
该操作是"多集合取交集"的一种特殊情况,即"对一个集合取交集时返回它本身"。Redis底层调用sinterGenericCommand统一处理,在14.2.1节中一并介绍;
4.查找成员
查找成员的命令是sismember,命令的作用是判断元素是否在指定集合中。
格式:sismember key member
说明: 判断member元素是否是集合key的成员,如果是返回1,否则返回0。
示例:> sadd test a b c
源码分析: 函数入口在sismemberCommand。
集合有intset和字典两种实现,对于OBJ_ENCODING_HT和OBJ_ENCODING_INTSET,分别调用dictFind及intsetFind两函数判断即可。
sismemberCommand核心调用的函数是setTypeIsMember;
int setTypeIsMember(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) {
return dictFind((dict*)subject->ptr,value) != NULL;
} else if (subject->encoding == OBJ_ENCODING_INTSET) {
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) { //string2ll,转成整型
return intsetFind((intset*)subject->ptr,llval);
}
} else {
serverPanic("Unknown set encoding");
}
return 0;
}
5.移动成员
smove命令的作用是移动元素至指定集合。
格式:smove source destination member
说明: 将member元素从source集合移动到destination集合。
示例:> smove test1set test2set "hello"
源码分析: 函数入口在smoveCommand。
函数逻辑分两部分。
①校验,考虑各种无法移动的情况。包括源集合不存在、集合类型错误、源集合与目标集合相同等情况;
②从源集合中删除元素,并将元素插入目标集合。若目标集合不存在,创建新集合后再插入。
void smoveCommand(client *c) {
robj *srcset, *dstset, *ele;
srcset = lookupKeyWrite(c->db,c->argv[1]);
dstset = lookupKeyWrite(c->db,c->argv[2]);
ele = c->argv[3];
/*源集合不存在 return 0 */
if (srcset == NULL) {
addReply(c,shared.czero);
return;
}
/* 集合类型错误. */
if (checkType(c,srcset,OBJ_SET) ||
(dstset && checkType(c,dstset,OBJ_SET))) return;
/*源集合与目标集合相同 */
if (srcset == dstset) {
addReply(c,setTypeIsMember(srcset,ele->ptr) ?
shared.cone : shared.czero);
return;
}
/* 元素不能从原集合中删除 . */
if (!setTypeRemove(srcset,ele->ptr)) {
addReply(c,shared.czero);
return;
}
notifyKeyspaceEvent(NOTIFY_SET,"srem",c->argv[1],c->db->id);
/*空时从数据库中删除src集*/
if (setTypeSize(srcset) == 0) {
dbDelete(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",c->argv[1],c->db->id);
}
/*目标集合不存在,创建新集合*/
if (!dstset) {
dstset = setTypeCreate(ele->ptr);
dbAdd(c->db,c->argv[2],dstset);
}
...
/* 将ele成功添加到dstset时,一个额外的键已更改 */
if (setTypeAdd(dstset,ele->ptr)) {
server.dirty++;
notifyKeyspaceEvent(NOTIFY_SET,"sadd",c->argv[2],c->db->id);
}
addReply(c,shared.cone);
}
6.获取基数
scard命令的作用是获取集合中的元素数量(集合基数)。
格式:scard key
说明: 返回集合key的基数(集合中元素的数量)。
示例:>scard test1
源码分析: 函数入口在scardCommand。
scardCommand函数先做基本的校验,最终调用setTypeSize函数查询基数。由于集合底层通过字典和intset实现,setTypeSize也分情况调用不同的查询函数:
unsigned long setTypeSize(const robj *subject) {
if (subject->encoding == OBJ_ENCODING_HT) {
return dictSize((const dict*)subject->ptr); //查询dict大小 h[0]和h[1] used数量之和
} else if (subject->encoding == OBJ_ENCODING_INTSET) {
return intsetLen((const intset*)subject->ptr); //查询intset大小,直接返回统计成员变量
} else {
serverPanic("Unknown set encoding");
}
}
uint32_t intsetLen(const intset *is) {
return intrev32ifbe(is->length);
}
7.遍历成员
sscan命令用于增量遍历集合元素。
格式:sscan cursor [match pattern] [count count]
说明: sscan每次执行返回少量元素和一个新的游标,该游标用于下次遍历时延续之前的遍历过程,指定游标为0时,表示开始一轮新的迭代,而当服务器返回游标值为0时,表示本轮遍历结束。
示例:> sscan test1 0
源码分析:
函数入口在sscanCommand,最终调用scanGenericCommand:
scanGenericCommand(c,set,cursor);
scanGenericCommand的函数逻辑主要分为4步:
①参数校验;
②获取本次遍历的随机元素;
③根据pattern过滤元素;
④返回相应元素。
void scanGenericCommand(client *c, robj *o, unsigned long cursor) {
/* Sep 1: Parse options. */
.....
/* Step 2: Iterate the collection. 如果是ziplist则由少量元素组成 . */
if (ht) {//hashtable类型
void *privdata[2];
/* 最大迭代数量为10倍count ,防止哈希表稀疏填充, 避免浪费时间不返回. */
long maxiterations = count*10;
privdata[0] = keys; //存放结果元素的链表
privdata[1] = o;
do { //dictscan将随机返回一个字典元素
cursor = dictScan(ht, cursor, scanCallback, NULL, privdata);
} while (cursor &&
maxiterations-- &&
listLength(keys) < (unsigned long)count);
} else if (o->type == OBJ_SET) {
//编码是inset类型
int pos = 0;
int64_t ll;
while(intsetGet(o->ptr,pos++,&ll))
//将intset的所有元素全部加入结果集,并将curosr置为0(代表本次遍历结束)
listAddNodeTail(keys,createStringObjectFromLongLong(ll));
cursor = 0;
} else if (o->type == OBJ_HASH || o->type == OBJ_ZSET) {
unsigned char *p = ziplistIndex(o->ptr,0);
unsigned char *vstr;
unsigned int vlen;
long long vll;
while(p) {
ziplistGet(p,&vstr,&vlen,&vll);
listAddNodeTail(keys,
(vstr != NULL) ? createStringObject((char*)vstr,vlen) :
createStringObjectFromLongLong(vll));
p = ziplistNext(o->ptr,p);
}
cursor = 0;
} else {
serverPanic("Not handled encoding in SCAN.");
}
/* Step 3: 过滤元素 . */
node = listFirst(keys);
while (node) {
robj *kobj = listNodeValue(node);
nextnode = listNextNode(node);
int filter = 0;
/* 过滤不匹配pattern的元素 . */
if (!filter && use_pattern) {
if (sdsEncodedObject(kobj)) {
if (!stringmatchlen(pat, patlen, kobj->ptr, sdslen(kobj->ptr), 0))
filter = 1; //不匹配,过滤
} else {
char buf[LONG_STR_SIZE];
int len;
serverAssert(kobj->encoding == OBJ_ENCODING_INT);
len = ll2string(buf,sizeof(buf),(long)kobj->ptr);
if (!stringmatchlen(pat, patlen, buf, len, 0)) filter = 1;
}
}
/* 过滤不想要的元素. */
if (!filter && o == NULL && typename){
robj* typecheck = lookupKeyReadWithFlags(c->db, kobj, LOOKUP_NOTOUCH);
char* type = getObjectTypeName(typecheck);
if (strcasecmp((char*) typename, type)) filter = 1;
}
/*过滤已过期的元素(key). */
if (!filter && o == NULL && expireIfNeeded(c->db, kobj)) filter = 1;
/* 移除被过滤的元素 */
if (filter) {
decrRefCount(kobj);
listDelNode(keys, node);
}
...
/* Step 4: 返回客户端 */
...
}
14.2 集合运算
Redis实现了集合求交集、求差集、求并集三种基本运算。
14.2.1 交集
1.sinter
sinter命令的作用是求多集合的交集。
格式:sinter key [key ...]
说明: sinter命令返回一个集合的全部成员,该集合是所有给定集合的交集。不存在的key被视为空集。当给定集合中有一个空集时,结果也为空集(根据集合运算定律)。
示例:
> sadd testset1 a b c
> sadd testset2 a b d
> sadd testset3 a e f
> sinter testset1 testset2 testset3
源码分析: 函数入口在sinterCommand。
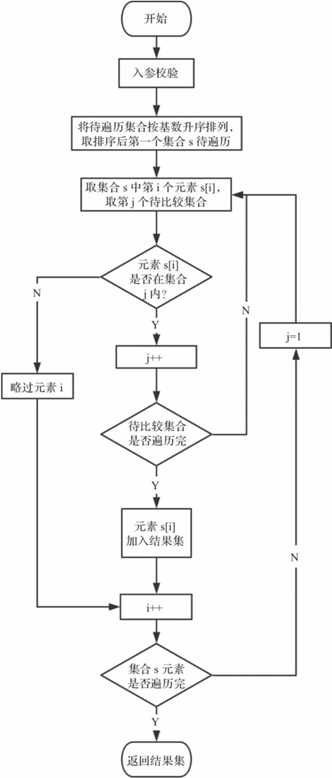
图14-1 求交集流程图
如图14-1所示,集合求交集的基本逻辑是:
先将集合按基数大小排序,以一个集合(基数最小)为标准,遍历该集合中的所有元素,依次判断该元素是否在其余所有集合中:如果不在任一集合,舍弃该元素,否则加入结果集。
排序的意义在于减小遍历元素的个数,交集不可能大于任一集合,故遍历最小集合是效率最高的。
void sinterGenericCommand(client *c, robj **setkeys,
unsigned long setnum, robj *dstkey) {
robj **sets = zmalloc(sizeof(robj*)*setnum); /所有待计算的集合数组
...
// 1)参数校验,排除空集合。函数首先校验集合是否存在或为空(为空删除),将存在且不为空的集合依次放入sets数组中:
for (j = 0; j < setnum; j++) {
robj *setobj = dstkey ?
lookupKeyWrite(c->db,setkeys[j]) :
lookupKeyRead(c->db,setkeys[j]);
if (!setobj) {
zfree(sets); //释放并删除空的key
... return;
} ...
sets[j] = setobj; //将集合放入待处理集合数组中
}
/* 2)将集合按基数从小到大排序,提升性能,以最小的为标尺,方便接下来依次比较: */
qsort(sets,setnum,sizeof(robj*),qsortCompareSetsByCardinality);
...
/* 3)遍历最小集合中的所有元素,依次判断是否在其余集合中,只要元素不在任一集合中,就不满足交集的条件,舍弃*/
si = setTypeInitIterator(sets[0]);
while((encoding = setTypeNext(si,&elesds,&intobj)) != -1) {
for (j = 1; j < setnum; j++) {
if (sets[j] == sets[0]) continue; //略过自己
if (encoding == OBJ_ENCODING_INTSET) {
/* intset with intset is simple... and fast */
if (sets[j]->encoding == OBJ_ENCODING_INTSET &&
!intsetFind((intset*)sets[j]->ptr,intobj))
{ break; // 不在则直接退出for循环,舍弃该元素, }
else if (sets[j]->encoding == OBJ_ENCODING_HT) {
elesds = sdsfromlonglong(intobj); //将int转为sdsobj
if (!setTypeIsMember(sets[j],elesds)) {
sdsfree(elesds); break;
}
sdsfree(elesds);
}
} else if (encoding == OBJ_ENCODING_HT) {
if (!setTypeIsMember(sets[j],elesds)) { break; }
}
}
/* 有当该元素在其余所有集合中都出现时,才将其加入目标集合r */
//stset中存放了最终的结果。注意在判断元素是否在集合中时,同样区分了OBJ_ENCODING_HT和OBJ_ENCODING_INTSET两种类型,调用了不同的底层方法;
if (j == setnum) {
if (!dstkey) {
if (encoding == OBJ_ENCODING_HT)
addReplyBulkCBuffer(c,elesds,sdslen(elesds));
else addReplyBulkLongLong(c,intobj);
cardinality++;
} else {
if (encoding == OBJ_ENCODING_INTSET) {
elesds = sdsfromlonglong(intobj);
setTypeAdd(dstset,elesds);
sdsfree(elesds);
} else { setTypeAdd(dstset,elesds); }
}
}
}
setTypeReleaseIterator(si);
//如果需要存储到目标集合, sinterstore命令用到
if (dstkey) {
/* 如果交集不是空集,请将结果集存储到目标中. */
int deleted = dbDelete(c->db,dstkey); //若指定集合key存在,先删除
if (setTypeSize(dstset) > 0) {
dbAdd(c->db,dstkey,dstset); ... //将返回结果写入指定集合中
} else { ... }
} else {
setDeferredSetLen(c,replylen,cardinality);
}
zfree(sets);
}
2.sinterstore
sinterstore命令与sinter命令类似,不同之处在于它将结果保存至指定集合,而不是简单返回。
格式:sinterstore destination key [key ...]
示例:
> sadd test1 a b c
> sadd test2 a b d
> sadd test3 a e f
> sinterstore test4 test1 test2 test3
> smembers test4
源码分析: sinterstore与sinter的源码处理在同一位置,只是返回前sinterstore将结果集保存。
14.2.2 并集
sunion命令的作用是求多集合的并集。
格式:sunion key [key ...]
说明: 返回一个集合的全部成员,该集合是所有给定集合的并集。不存在的key被视为空集。
源码分析:
函数入口在sunionCommand,最终调用sunionDiffGenericCommand。
求并集的基本思路是,
遍历所有集合,调用setTypeAdd将所有元素依次插入结果集,插入过程中会去重,自然得到并集。sunion和sdiff底层调用了同一函数sunionDiff-GenericCommand。
void sunionDiffGenericCommand(client *c, robj **setkeys, int setnum,
robj *dstkey, int op) {
// 校验集合,排除空集
for (j = 0; j < setnum; j++) {
robj *setobj = dstkey ?
lookupKeyWrite(c->db,setkeys[j]) :
lookupKeyRead(c->db,setkeys[j]);
if (!setobj) {
sets[j] = NULL;
continue;
}
if (checkType(c,setobj,OBJ_SET)) {
zfree(sets);
return;
}
sets[j] = setobj;
}
/* Select what DIFF algorithm to use. //这里是差集算法
sdiff为了提高性能,给出了两种策略;
策略一: 将A集合中元素在B1……Bn集合间一一查找,将查找不到的元素加入结果集。复杂度为O(M*n)。
策略二: 先将A集合加入结果集,再将B1……Bn集合中的所有元素在结果集中一一查找,将查到的元素从结果集中删除。复杂度为O(N)。
在算法选择时,大的逻辑是:如果A集合比较小,遍历A更划算;反之遍历其余集合更划算。
if (op == SET_OP_DIFF && sets[0]) {
//algo_X_work代表了该策略的权重,分值越小代表效率越高
long long algo_one_work = 0, algo_two_work = 0;
for (j = 0; j < setnum; j++) {
if (sets[j] == NULL) continue;
algo_one_work += setTypeSize(sets[0]);
algo_two_work += setTypeSize(sets[j]);
}
algo_one_work /= 2; /*算法algo_one_work效率更好,给其赋予更高的权重*/
diff_algo = (algo_one_work <= algo_two_work) ? 1 : 2;
if (diff_algo == 1 && setnum > 1) {
qsort(sets+1,setnum-1,sizeof(robj*),
qsortCompareSetsByRevCardinality);
}
}
dstset = createIntsetObject();
//这里是并集
if (op == SET_OP_UNION) {
/* 将每个集合的每个元素添加到临时集合即可。. */
for (j = 0; j < setnum; j++) {
if (!sets[j]) continue; /* 集合为空跳过 */
si = setTypeInitIterator(sets[j]);
while((ele = setTypeNextObject(si)) != NULL) {
if (setTypeAdd(dstset,ele)) cardinality++; //将元素插入结果集
sdsfree(ele);
}
setTypeReleaseIterator(si);
}
} else if (op == SET_OP_DIFF && sets[0] && diff_algo == 1) {
/* 策略一源码 *
si = setTypeInitIterator(sets[0]);
while((ele = setTypeNextObject(si)) != NULL) {
for (j = 1; j < setnum; j++) {
if (!sets[j]) continue; /*集合为空则跳过. */
if (sets[j] == sets[0]) break; /* 比较集合是它本身,则跳过! */
if (setTypeIsMember(sets[j],ele)) break; //元素在比较集合中,抛弃该元素
}
if (j == setnum) {
/* 全部比较完成后,元素依然存在,则该元素为差集元素. */
setTypeAdd(dstset,ele);
cardinality++;
}
sdsfree(ele);
}
setTypeReleaseIterator(si);
} else if (op == SET_OP_DIFF && sets[0] && diff_algo == 2) {
/* 策略二源码 */
for (j = 0; j < setnum; j++) {
if (!sets[j]) continue; /*集合为空则跳过 */
si = setTypeInitIterator(sets[j]);
while((ele = setTypeNextObject(si)) != NULL) {
if (j == 0) { //j=0是A数组
if (setTypeAdd(dstset,ele)) cardinality++; //先将A集合加入结果集
} else {
//将在A集合中,且在其余集合中的元素从结果集中移除
if (setTypeRemove(dstset,ele)) cardinality--;
}
sdsfree(ele);
}
setTypeReleaseIterator(si);
if (cardinality == 0) break;
}
}
/* Output the content of the resulting set, if not in STORE mode */
if (!dstkey) {
addReplySetLen(c,cardinality);
si = setTypeInitIterator(dstset);
while((ele = setTypeNextObject(si)) != NULL) {
addReplyBulkCBuffer(c,ele,sdslen(ele));
sdsfree(ele);
}
setTypeReleaseIterator(si);
server.lazyfree_lazy_server_del ? freeObjAsync(dstset) :
decrRefCount(dstset);
} else {
/* If we have a target key where to store the resulting set
* create this key with the result set inside */
int deleted = dbDelete(c->db,dstkey);
if (setTypeSize(dstset) > 0) {
dbAdd(c->db,dstkey,dstset);
addReplyLongLong(c,setTypeSize(dstset));
notifyKeyspaceEvent(NOTIFY_SET,
op == SET_OP_UNION ? "sunionstore" : "sdiffstore",
dstkey,c->db->id);
} else {
decrRefCount(dstset);
addReply(c,shared.czero);
if (deleted)
notifyKeyspaceEvent(NOTIFY_GENERIC,"del",
dstkey,c->db->id);
}
signalModifiedKey(c,c->db,dstkey);
server.dirty++;
}
zfree(sets);
}
14.2.3 差集
sdiff命令的作用是求集合间的差集。
说明: 返回一个集合的全部成员,该集合是所有给定集合之间的差集。
格式:SDIFF key [key ...]
源码分析: 函数入口在sinterCommand,最终调用sunionDiffGenericCommand。
求差集的逻辑跟求交集有类似之处,将待求差集的集合A作为"标尺",并将给定集合按基数大小排序,然后筛选掉不符合条件的元素。需要注意的是以下方面。
1)求交集时,按基数大小对给定集合进行升序排序:
qsort(sets,setnum,sizeof(robj*),qsortCompareSetsByCardinality);
2)求差集时,按基数大小对给定集合进行降序排序:
qsort(sets+1,setnum-1,sizeof(robj*),
qsortCompareSetsByRevCardinality);
求差集时,我们从大集合开始比较(找到的概率更高,一旦匹配成功,说明该元素不是差集元素,省去了往后比较的时间)。
表14-1 筛选策略

14.3 本章小结
单集合的操作和多集合间的运算。集合底层基于dict和intset两基本数据结构插入和删除的效率也依赖dict与intset。