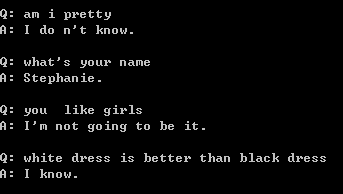
- 基于生成的chatbot系统,使用的是经典Seq2Seq的结构:

- 数据集:
数据集默认存储在项目中的data文件夹中,
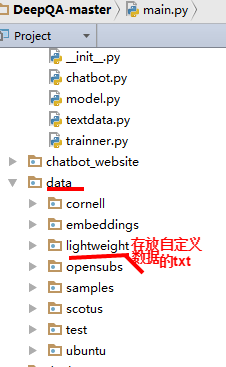

clone项目的的时候,Cornell Movie Dialog 是一起下载
其他的数据集:OpenSubtitles,Supreme Court Conversation Data,Ubuntu Dialogue Corpus 需要额外下载,使用时通过参数--corpus **指定
自定义的数据集,可根据既定的模式使用 https://github.com/Conchylicultor/DeepQA/tree/master/data/lightweight ,使用时通过参数--corpus lightweight --datasetTag <name>指定
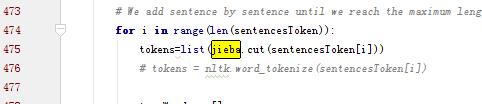
- 注:若需要使用中文数据集,只需修改testdata.py中的断词的地方,引入结巴即可
将tokens = nltk.word_tokenize(sentencesToken[i]) 换成tokens=list(jieba.cut(sentencesToken[i]))
- 为了加速训练,可使用提前训练好的word wmbeddings
- 模型训练
直接运行main函数
读取数据: textdata.py将文本按照出现的次序转换成数字编码,同时生成字典

处理好的数据存储在self.trainingSample中,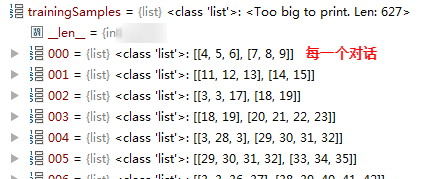
字典:
构建模型:
主要的逻辑实现在model.py中,通过TensorFlow自带embedding_rnn_seq2seq函数实现
构建完成后开始训练
- 测试模型
通过参数modelTag指定model,test指定交互方式

decoder ouptut 输出 单句最大词数*1*数据集单词数 的3维向量,每个数值表示所对应单词的概率,取最大的作为答案,即可得到若干个单词作为答案