1. 画图详解Spark工作流程,以及在集群上和各个角色的对应的关系
当 jar 在客户端进行spark-submit的时候spark流程就开始了,先概括的介绍一下流程, 在讲述一下流程中的重要组件
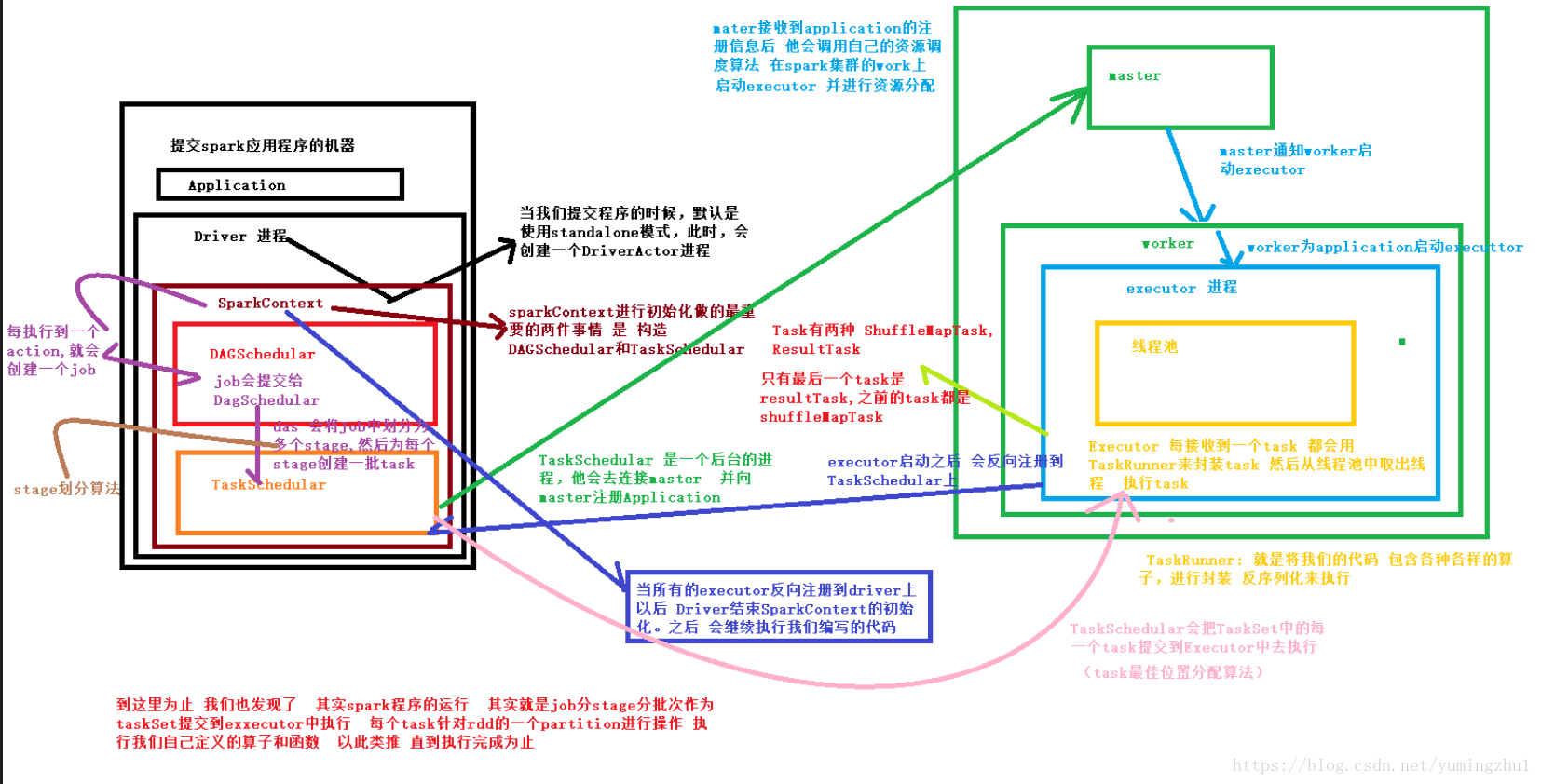
1.application启动之后, 会在本地启动一个Driver进程 用于控制整个流程,(假设我们使用的Standalone模式)
2 首先需要初始化的是SparkContext, SparkContext 要构建出DAGScheduler,TaskScheduler
3 在初始化TastScheduler的时候,它会去连接master,并向master 注册Application ,master 收到信息之后,会调用自己的资源调度算法,在spark集群的work上,启动Executor,并进行资源的分配, 最后将Executor 注册到TaskScheduler, 到这准备工作基本完成了
4 现在可以进行我们编写的的业务了, 一般情况下通过sc.textFile("file") 去加载数据源( 这个过程类似于mr的inputformat加载数据的过程), 去将数据转化为RDD,
5 DagScheduer 先按照action将程序划分为一至多个job(每一个job对应一个Dag), 之后对DagScheduer按照是否进行shuffer,将job划分为多个Stage 每个Stage过程都是taskset , dag 将taskset交给taskScheduler,由Work中的Executor去执行, 至于tast交给那个executor去执行, 由算法来决定,
2. spark那些算子操作涉及到shuffle
bykey系列,join, distinct等
3. Spark性能优化主要有那些手段
spark优化基础篇
https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
spark优化高级篇
https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
spark面试总结
https://blog.csdn.net/Lwj879525930/article/details/82559596
4. Map-Reduce程序运行的时候会有什么比较常见的问题
https://blog.csdn.net/u011762604/article/details/73178097
https://blog.csdn.net/dkjhl/article/details/84098847
面试过程中问到这个,并没有标准答案,主要是想知道你到底有没有做过开发,如果是做过开发,肯定遇到过问题
5. Hadoop和Spark的shuffle过程,你怎么避免一些问题
这个题目回答的步骤是:
1.hadoop的shuffle过程
2.spark的shuffle过程
3.讲下优化
6. Hadoop的TextInputFormat作用是什么,如何自定义实现
k:偏移量 ---》 v : 数据
InputFormat会在map操作之前对数据进行两方面的预处理
1是getSplits,返回的是InputSplit数组,对数据进行split分片,每片交给map操作一次
2是getRecordReader,返回的是RecordReader对象,对每个split分片进行转换为key-value键值对格式传递给map
常用的InputFormat是TextInputFormat,使用的是LineRecordReader对每个分片进行键值对的转换,以行偏移量作为键,行内容作为值
自定义类继承InputFormat接口,重写createRecordReader和isSplitable方法
在createRecordReader中可以自定义分隔符
7. 有哪些数据倾斜,怎么解决
hadoop的mr数据倾斜解决思路:
https://blog.csdn.net/WYpersist/article/details/79797075
hive数据倾斜解决思路:
https://www.cnblogs.com/zhangxiaofan/p/11110463.html
hbase的热点问题,解决思路:
https://blog.csdn.net/qq_31598113/article/details/71278857
spark数据倾斜与解决思路:8种解决方案,常用的4种