TCP的拥塞控制的一般原理
在计算机网络中的链路容量(带宽)、交换结点中的缓存和处理机等,都是网络的资源。在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏,这种情况就叫做拥塞。若网络中有许多资源同时呈现供应不足,网络的性能就要明显变坏,整个网络的吞吐量随输入负荷的增大而下降。
有人可能会说:只要任意增加一些资源,例如,把结点缓存的存储空间扩大,或把链路更换为更高速率的链路,或把结点处理机的运算速度提高,就可以解决网络拥塞的问题。其实不然,网络拥塞往往是由许多因素引起的。例如,当某个结点缓存的容量太小时,到达该结点的分组因无存储空间暂存而不得已被丢弃。现在将该结点的缓存容量扩展到非常大,于是凡到达该结点的分组均可在结点的缓存队列中排队,不受任何限制。由于输出链路的容量和处理机的速度并未提高,因此队列中的绝大多数分组的排队等待时间将会大大增加,结果上层软件只好把它们进行重传(因为超时了)。由此可见,简单的扩大缓存的存储空间同样会造成网络资源的严重浪费,因而解决不了网络拥塞的问题。
又如,处理机处理的速率太慢可能引起网络的拥塞。此时简单的将处理机的速率提高,可能会缓解这一情况,但往往又会将瓶颈转移到其它地方。问题的本质是整个系统的各个部分不匹配,只有所有的部分都平衡了,问题才会得到解决。
拥塞常常趋于恶化。如果一个路由器没有足够的缓存空间,它就会丢弃一些新到的分组。但当分组被丢弃时,发送这一分组的源点就会重传这一分组,甚至可能还要重传多次。这样会引起更多的分组流入网络和被网络中的路由器丢弃。可见拥塞引起的重传并不会缓解网络的拥塞,反而会加剧网络的拥塞。
拥塞控制与流量控制的关系密切,它们之间也存在着一些差别。所谓拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。TCP连接的端点只要迟迟不能收到对方的确认信息,就猜想在当前网络中的某处很可能发生了拥塞,但这时却无法知道拥塞到底发生在网络的何处,也无法知道发生拥塞的具体原因(某个服务器通信量过大?某个地区出现灾害?)。流量控制往往是指点对点通信量的控制,是个端到端的问题(接收端控制发送端)。流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
举两个例子说明这种区别。假设某个网络的链路传输速率为1000Gbit/s,有一台计算机向一台个人电脑以1Gbit/s的速率传送文件。显然,网络本身的带宽是足够大的,因而不存在产生拥塞的问题。但流量控制却是必须的,因为计算机必须经常停下来,以便个人电脑来得及接收。再假设有另一个网络,其链路传输速率为1Mbit/s,有1000台计算机连接在这个网络上。假定其中的500台计算机分别向其余的500台计算机以100Kbit/s的速率发送文件。那么现在的问题就不是接收端的计算机能否来得及接收,而是整个网络的输入负载是否超过网络所能承受的。
进行拥塞控制需要付出代价。首先需要获得网络内部流量分布的信息。在实施拥塞控制时,还需要在结点之间交换信息和各种命令,以便选择控制的策略和实施控制。这样就产生了额外开销。拥塞控制有时需要将一些资源分配给个别用户单独使用,这样就使得网络资源不能更好的实现共享。
下图中横坐标是提供的负载,代表单位时间内输入给网络的分组数目。因此提供的负载也称为输入负载或网络负载。纵坐标是吞吐量,代表单位时间内从网络输出的分组数目。具有理想拥塞控制的网络,在吞吐量饱和之前,网络吞吐量应等于提供的负载,故吞吐量曲线是45°的斜线。但当提供的负载超过某一限度时,由于网络资源受限,吞吐量不再增长而保持为水平线,即吞吐量达到饱和。这就表明提供的负载中有一部分损失掉了(被某个结点丢弃)。虽然如此,在这种理想的拥塞控制作用下,网络的吞吐量仍维持在其所能达到的最大值。
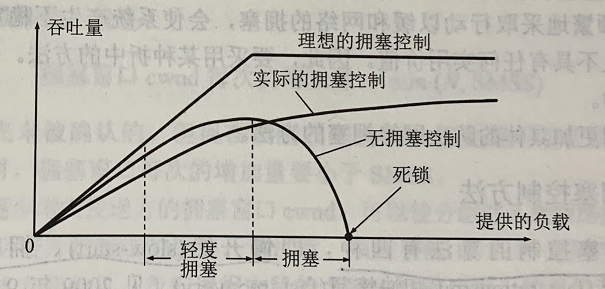
但是,实际网络的情况就很不相同了。观察上图,随着提供的负载的增大,网络吞吐量的增长速率逐渐减小。也就是说,在网络吞吐量还未达到饱和时,就已经有一部分的输入分组被丢弃了。当网络的吞吐量明显的小于理想的吞吐量时,网络就进入了轻度拥塞的状态。当提供的负载达到某一数值时,网络的吞吐量反而随提供的负载的增大而下降,这时网络就进入了拥塞状态。当提供的负载继续增大到某一数值时,网络的吞吐量就下降到零,网络已无法工作,这就是所谓的死锁。
由于计算机网络是一个很复杂的系统,因此可以从控制理论的角度来看拥塞控制这个问题。从大的方面看,可以分为开环控制和闭环控制两种方法。开环控制就是在设计网络时,事先将有关发生拥塞的因素考虑到,力求网络在工作时不产生拥塞。但一旦整个系统运行起来,就不再中途进行改正了。闭环控制是基于反馈环路的概念,主要有以下几种措施:
(1)监测网络系统以便检测到拥塞在何时、何处发生
(2)把拥塞发生的信息传送到可采取行动的地方
(3)调整网络系统的运行以便解决出现的问题
有很多的方法可用来监测网络的拥塞。主要的一些指标是:
- 由于缺少缓存空间而被丢弃的分组的百分数
- 平均队列长度
- 超时重传的分组数
- 平均分组时延
- 分组时延的标准差
一般在监测到拥塞发生时,要将拥塞发生的信息传送到产生分组的源站。当然,通知拥塞发生的分组同样会使网络更加拥塞。另一种方法是在路由器转发的分组中保留一个比特或字段,用该比特或字段的值表示网络没有拥塞或产生了拥塞。也可以由一些主机或路由器周期性的发出探测分组,以询问拥塞是否发生。此外,过于频繁的采取行动以缓和网络的拥塞,会使系统产生不稳定的振荡。但过于迟缓的采取行动又不具有任何实用价值。