一:sqlserver 执行计划介绍
sqlserver 执行计是在sqlser manager studio 工具中打开,是检查一条sql执行效率的工具。建议配合SET STATISTICS IO ON等语句来一起使用,执行计划是从右向左看,耗时高的一般显示在右边,我们知道,sqlserver 查询数据库的方式为:
1:表扫描(table scan) 查询速度最慢.
2:聚集索引扫描(Clustered Index Scan),按聚集索引逐行进行查询,效率比表扫描高,但速度还是慢.
3:索引扫描(index scan)效率比聚集索引快,根据索引滤出部分数据在进行逐行检查。
4;索引查找(index seek) 效率比索引扫描还要快,根据索引定位记录所在位置再取出记录.
5:聚集索引查找(Clustered Index Seek) 效率最快,直接根据聚集索引获取记录。
当发现某个查询比较慢时,可以首先检查哪些操作的成本比较高,再看看那些操作在查找记录时, 是不是【Table Scan】或者【Clustered Index Scan】,如果确实和这二种操作类型有关,则要考虑增加索引来解决了,sqlser 索引有两种,聚集索引和非聚集索引,聚集索引是一张表只能有一个,比如id,非聚集索引可以有多个,聚集索引是顺序排列的类似于字典查找拼音a、b、c……和字典文字内容顺序是相同的,非聚集索引与内容是非顺序排列的,类似字典偏旁查找时,同一个偏旁‘王’的汉字可能一个在第1页一个在第5页。
二:创建测试表
create table shopping_user(uId bigint primary key,uName varchar(10)); create table shopping_goods_category(cId bigint primary key,cName varchar(20)); create table shopping_goods(gId bigint primary key,gName varchar(50),gcId bigint,gPrice int); create table shopping_order(oId bigint primary key,oUserId bigint,oAddTime datetime,oGoodsId bigint,oMoney int);
创建测试sql
declare @index int; set @index = 1; while(@index<=10) begin insert into shopping_user (uId,uName) values(@index,'user'+cast(@index as varchar(10))); set @index = @index+1; end; insert into shopping_goods_category (cid,cName) values(1,'水果'); insert into shopping_goods_category (cid,cName) values( 2,'电脑'); insert into shopping_goods_category (cid,cName) values (3,'手机'); insert into shopping_goods_category (cid,cName) values (4,'服装'); insert into shopping_goods_category (cid,cName) values (5,'食品'); ------ 商品表sql declare @index int; declare @num int; set @index = 1; set @num = 10000; begin while(@index<=100*@num) begin if @index<=10*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,1,'水果'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >10*@num and @index <=20*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,1,'水果'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >20*@num and @index <=30*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,2,'电脑'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >30*@num and @index <=40*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,2,'电脑'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >40*@num and @index <=50*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,3,'手机'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >50*@num and @index <=60*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,3,'手机'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >60*@num and @index <=70*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,4,'服装'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >70*@num and @index <=80*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,4,'服装'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >80*@num and @index <=90*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,5,'食品'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; else if @index >90*@num and @index <=100*@num begin insert into shopping_goods (gId,gcId,gName,gPrice) values (@index,5,'食品'+cast (@index as varchar(10)),cast( floor(rand()*100) as int) ); end; set @index = @index+1; end; end; ------- 订单表sql declare @index int; declare @num int; declare @timeNum int; declare @userId int; declare @goodsId int; declare @money int; declare @addTime varchar(30); set @index = 1; set @num = 10000; set @timeNum = 0; set @userId = 1; set @goodsid = 1; set @money = 100; set @addTime = ''; begin while(@index<=100*@num) begin set @timeNum = cast( floor(rand()*30)+1 as int) set @userId = cast( floor(rand()*99)+1 as int) set @money = cast ( floor(rand()*5000)+@userId as int) set @addTime = dateadd(day,@timeNum,getdate()) set @goodsId = cast( floor(rand()*999999)+1 as int) if @index<=10*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >10*@num and @index <=20*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >20*@num and @index <=30*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >30*@num and @index <=40*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >40*@num and @index <=50*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >50*@num and @index <=60*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >60*@num and @index <=70*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >70*@num and @index <=80*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >80*@num and @index <=90*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; else if @index >90*@num and @index <=100*@num begin insert into shopping_order (oid,oUserId,oAddTime,oGoodsId,oMoney) values (@index,@userId,@addTime,@goodsId,@money ); end; set @index = @index+1; end; end;
创建索引
create index gcid_index on shopping_goods (gcid); create index userid_index on shopping_order(ouserid); create index goodsid_index on shopping_order(ogoodsid);
三:执行计划分析
这里使用上一篇文章sql语句百万数据量优化方案中提到的,in和exists来分析,sql语句如下:
SET STATISTICS IO ON select top 20 * from shopping_order where exists ( select top 10 gid from shopping_goods where gcid =2 and ogoodsid = gid order by gprice desc) select top 20 * from shopping_order where goodsid in ( select top 10 gid from shopping_goods where gcid =2 order by gprice desc) -- DBCC DROPCLEANBUFFERS
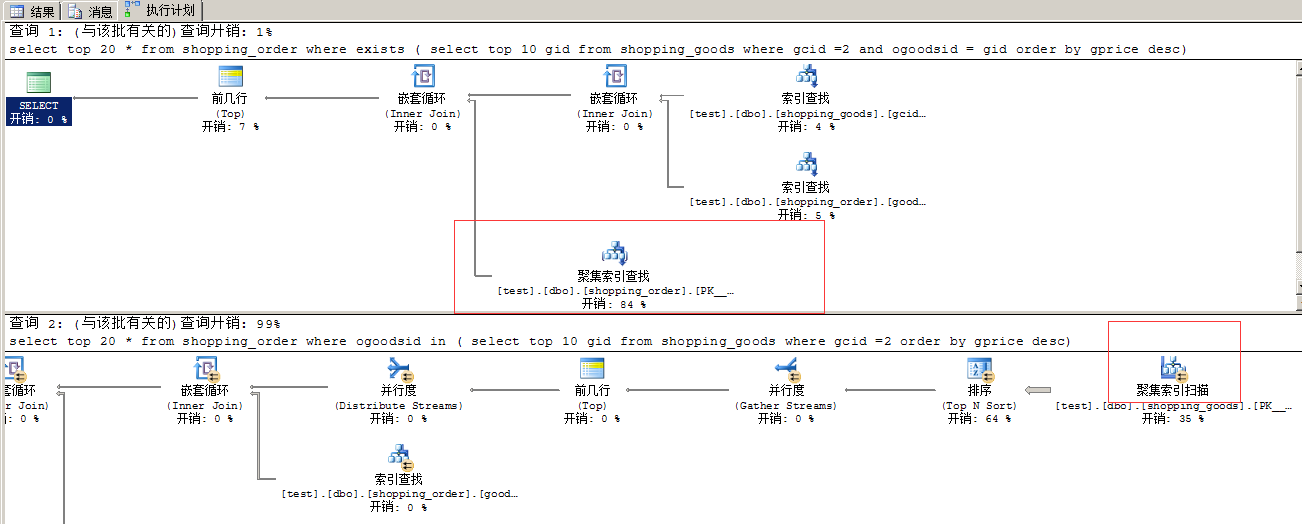
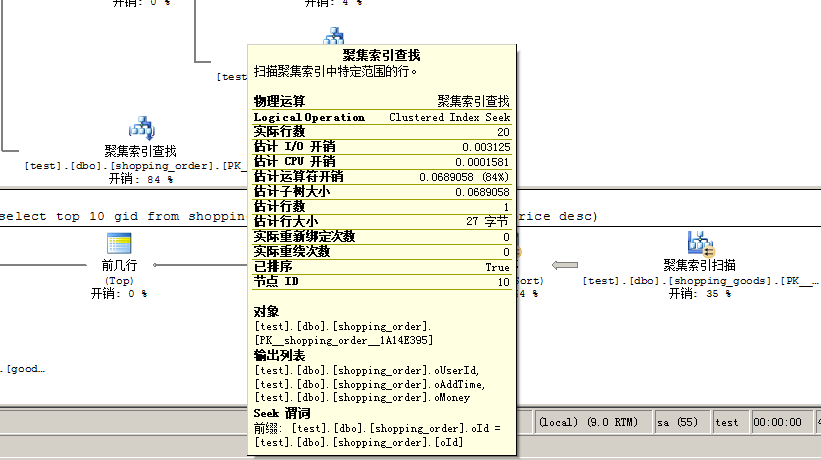
从上图中发现,使用exists,开销最大的是,使用聚集索引查找,而使用in,第一次操作(从右各左看),就使用了聚集索引扫描,in的效果明显差。我们再来看聚集索引查找结果,聚集索引返回的行数是20,见下图.
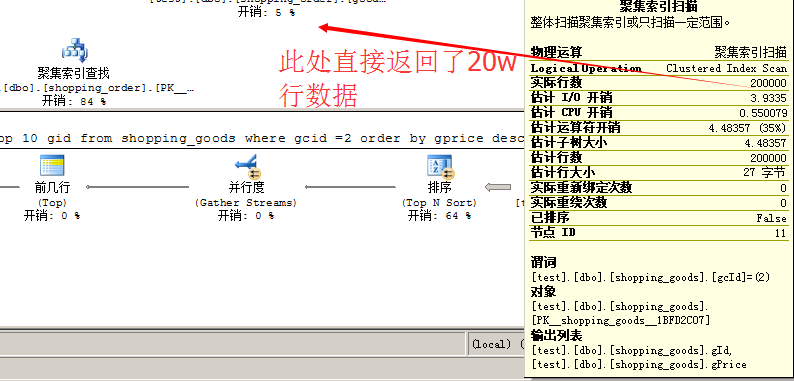
然后我们来看使用in查询,聚集索引扫描,查询结果却是20w
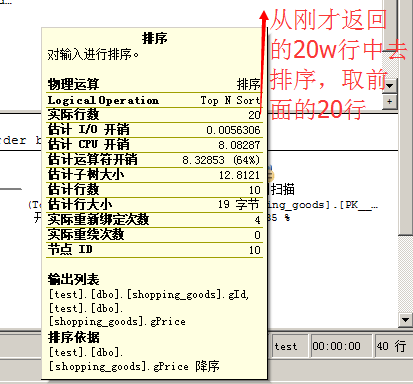
接着我们来看使用in查询,第二个开销大的排序,从刚才查询出来的20w数据中,order by desc 返回前20条数据。
此处我们还可以使用SET STATISTICS IO ON来查询这两者的io开销:
扫描计数:执行的扫描次数;
逻辑读取:从数据缓存读取的页数;
物理读取:从磁盘读取的页数;
预读:为进行查询而放入缓存的页数
重要:如果对于一个SQL查询有多种写法,那么这四个值中的逻辑读(logical reads)决定了哪个是最优化的。

从上图中发现,exists查询:shopping_order表扫描次数是2,逻辑读取是80,shopping_goods表,扫描次数是1,逻辑读取是6次,
而in shopping_order表扫描次数是2,逻辑读取是55,shopping_goods表,扫描次数是5,逻辑读取是5247次,当然工作中的sql肯定要复杂得多,但我们可以借助这个工具来找到需要优化的sql,当然这也只是执行计划,可能实际执行的效率和这个计划有出入,但我们还是可以借鉴执行计划来找到其中的不足。