文章很长,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈 奉上以下珍贵的学习资源:
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
| 入大厂 、做架构、大力提升Java 内功 必备的精彩博文 | 2021 秋招涨薪1W + 必备的精彩博文 |
|---|---|
| 1:Redis 分布式锁 (图解-秒懂-史上最全) | 2:Zookeeper 分布式锁 (图解-秒懂-史上最全) |
| 3: Redis与MySQL双写一致性如何保证? (面试必备) | 4: 面试必备:秒杀超卖 解决方案 (史上最全) |
| 5:面试必备之:Reactor模式 | 6: 10分钟看懂, Java NIO 底层原理 |
| 7:TCP/IP(图解+秒懂+史上最全) | 8:Feign原理 (图解) |
| 9:DNS图解(秒懂 + 史上最全 + 高薪必备) | 10:CDN图解(秒懂 + 史上最全 + 高薪必备) |
| 11: 分布式事务( 图解 + 史上最全 + 吐血推荐 ) | 12:seata AT模式实战(图解+秒懂+史上最全) |
| 13:seata 源码解读(图解+秒懂+史上最全) | 14:seata TCC模式实战(图解+秒懂+史上最全) |
| Java 面试题 30个专题 , 史上最全 , 面试必刷 | 阿里、京东、美团... 随意挑、横着走!!! |
|---|---|
| 1: JVM面试题(史上最强、持续更新、吐血推荐) | 2:Java基础面试题(史上最全、持续更新、吐血推荐 |
| 3:架构设计面试题 (史上最全、持续更新、吐血推荐) | 4:设计模式面试题 (史上最全、持续更新、吐血推荐) |
| 17、分布式事务面试题 (史上最全、持续更新、吐血推荐) | 一致性协议 (史上最全) |
| 29、多线程面试题(史上最全) | 30、HR面经,过五关斩六将后,小心阴沟翻船! |
| 9.网络协议面试题(史上最全、持续更新、吐血推荐) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
| SpringCloud 精彩博文 | |
|---|---|
| nacos 实战(史上最全) | sentinel (史上最全+入门教程) |
| SpringCloud gateway (史上最全) | 更多专题, 请参见【 疯狂创客圈 高并发 总目录 】 |
背景:
下一个视频版本,从架构师视角,尼恩为大家打造史上最强kafka源码视频。
并且,进一步,带大家实现一个超高质量的项目实操:10WQPS超高并发消息队列架构与实操
why kafka:
kafka 是高性能、高并发应用的经典案例,从技术学习、架构学习的角度来讲,浑身是宝。 netty 仅仅是通讯架构,kafka还有存储架构、高并发架构、高可用架构等等,都是经典中的经典。
但是,kafka很难,大家要做好思想准备。不过,跟着尼恩一起学架构,估计大家也不难了。
最终的目标,带大家穿透kafka, 掌握其存储架构、高并发架构、高可用架构的精髓。
最后,结合netty高性能架构,最终手写一个10WQPS超高并发消息队列。
此视频版本的整体的次序:
- 首先,开始Kafka源码分析,对kafka来一次彻底穿透
- 然后,10WQPS超高并发消息队列架构与实操,结合牛逼的Seata 源码中的RPC框架
此文为Kafka源码分析之11.
本系列博客的具体内容,请参见 Java 高并发 发烧友社群:疯狂创客圈
Kafka源码分析11:PartitionStateMachine分区状态机
kafka分区机制
分区机制是kafka实现高吞吐的秘密武器,但这个武器用得不好的话也容易出问题,作为背景,这里介绍分区的机制。
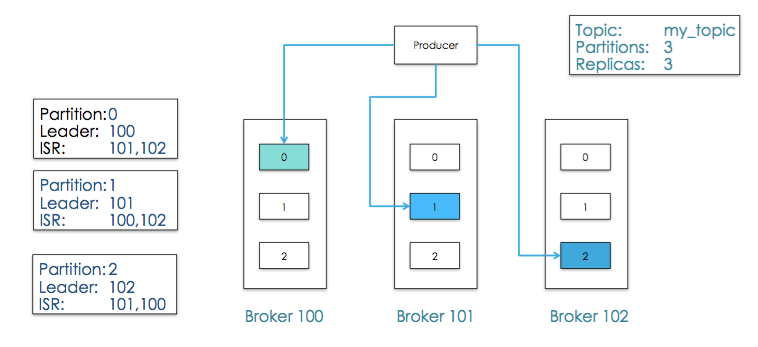
首先,从数据组织形式来说,kafka有三层形式,kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。
而每个分区可以分布到不同的机器上,这样一来,从服务端来说,分区可以实现高伸缩性,以及负载均衡,动态调节的能力。
下图是一个3个分区的topic例子,并且每个分区有3个副本:
我们可以通过replication-factor指定创建topic时候所创建的分区数。
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
比如这里就是创建了1个分区,的主题。
值得注意的是,还有一种创建主题的方法,是使用zookeeper参数的,那种是比较旧的创建方法,这里是使用bootstrap参数的。
PartitionStateMachine:分区状态机
PartitionStateMachine 负责管理 Kafka 分区状态的转换,和 ReplicaStateMachine 是一 脉相承的。
二者的对比
- ReplicaStateMachine:
负责定义 Kafka 副本状态、合法的状态转换,以及管理状态之间的转换。
- PartitionStateMachine:
负责定义 Kafka 分区状态、合法的状态转换,以及管理状态之间的转换。
分区状态机相关的类设计
从代码结构、实现功能和设计原理来看,二者都极为相似。
- PartitionStateMachine:分区状态机抽象类。
它定义了诸如 startup、shutdown 这 样的公共方法,定义了处理分区状态转换入口方法 handleStateChanges ,另外,定义了一个私有的 doHandleStateChanges方法,实现分区状态转换的操作。
-
PartitionState 接口及其实现对象:
定义 4 类分区状态,分别是 NewPartition、 OnlinePartition、OfflinePartition 和 NonExistentPartition。除此之外,还定义了它 们之间的依赖关系。 -
PartitionLeaderElectionStrategy 接口及其实现对象:
定义 4 类分区 Leader 选举策 略,对应到 Leader 选举的 4 种场景。
- PartitionLeaderElectionAlgorithms:分区 Leader 选举的算法实现。
4 类分区 Leader 选举策 略的实现代码,PartitionLeaderElectionAlgorithms 就提供了 这 4 类选举策略的实现代码。
分区状态机的启用
每个 Broker 启动时,都会创建对应的分区状态机和副本状态机实例,但只有 Controller 所在的 Broker 才会启动它们。
如果 Controller 变更到其他 Broker,老 Controller 所在的 Broker 要调用这些状态机的 shutdown 方法关闭它们,新 Controller 所在的 Broker 调用状态机的 startup 方法启动它们。
分区状态
PartitionState 接口
PartitionState 接口及其实现类,用来定义分区状态。
sealed trait PartitionState {
def state: Byte // 状态序号
def validPreviousStates: Set[PartitionState] // 合法前置状态集合
}
和 ReplicaState 类似,PartitionState 定义了分区的状态空间以及依赖规则。
OnlinePartition 状态
下面以 OnlinePartition 状态为例,说明下代码是如何实现流转的:
case object OnlinePartition extends PartitionState {
val state: Byte = 1
val validPreviousStates: Set[PartitionState] = Set(NewPartition, OnlinePartition, OfflinePartition)
}
如代码所示,每个 PartitionState 都定义了名为 validPreviousStates 的集合,也就是每个状态对应的合法前置状态集。
对于 OnlinePartition 而言,它的合法前置状态集包括 NewPartition、OnlinePartition 和 OfflinePartition。

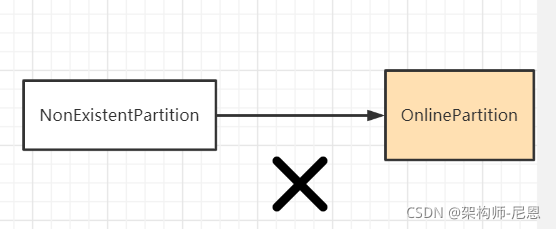
在 Kafka 中,从合法状态集以外的状态向目标状态进行转换,将被视为非法操作。
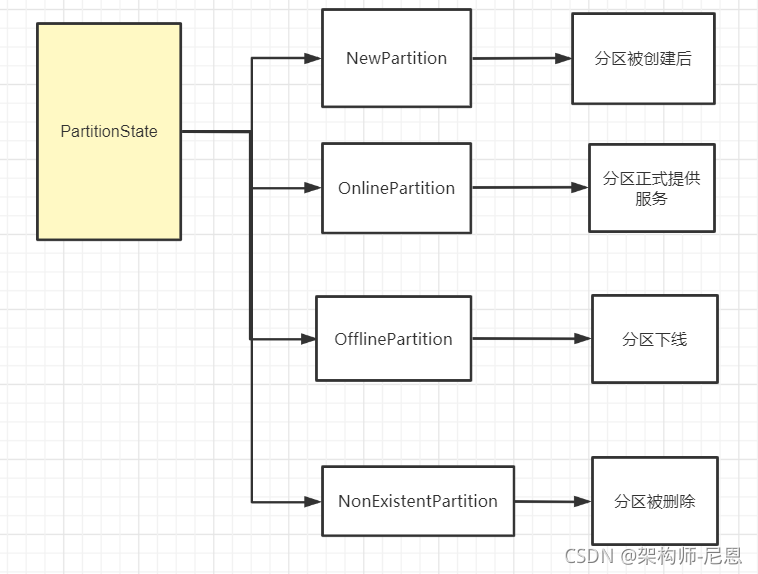
Kafka 的 4 类分区状态
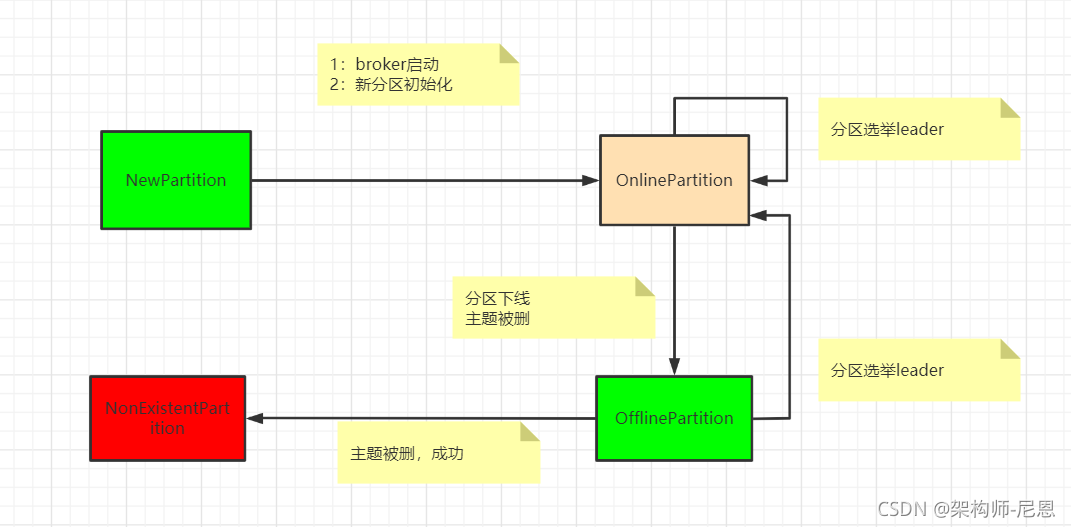
Kafka 为分区定义了 4 类状态,分别是 NewPartition、OnlinePartition、OfflinePartition 和 NonExistentPartition。
1. NewPartition:
分区被创建后被设置成这个状态,表明它是一个全新的分区对象。
处于 这个状态的分区,被 Kafka 认为是“未初始化”,因此,不能选举 Leader。
case object NewPartition extends PartitionState {
val state: Byte = 0
val validPreviousStates: Set[PartitionState] = Set(NonExistentPartition)
}
2. OnlinePartition:
分区正式提供服务时所处的状态。
case object OnlinePartition extends PartitionState {
val state: Byte = 1
val validPreviousStates: Set[PartitionState] = Set(NewPartition, OnlinePartition, OfflinePartition)
}
3. OfflinePartition:
分区下线后所处的状态。
case object OfflinePartition extends PartitionState {
val state: Byte = 2
val validPreviousStates: Set[PartitionState] = Set(NewPartition, OnlinePartition, OfflinePartition)
}
4. NonExistentPartition:
分区被删除,并且从分区状态机移除后所处的状态。
case object NonExistentPartition extends PartitionState {
val state: Byte = 3
val validPreviousStates: Set[PartitionState] = Set(OfflinePartition)
}
分区状态之间的转换关系
处理分区状态转换的方法
handleStateChanges
handleStateChanges 把 partitions 的状态设置为 targetState。
handleStateChanges 调用doHandleStateChanges方法执行真正的状态变更逻辑,在这个方法中,可能需要用 为 partitions 选举新的 Leader,最终将 partitions 的 Leader 信息返回。
def handleStateChanges(partitions: Seq[TopicPartition], targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy] = None): Unit = {
if (partitions.nonEmpty) {
try {
// raise error if the previous batch is not empty
//为了提高KafkaController Leader和集群其他broker的通信效率,实现批量发送请求的功能
// 检查上一批请求KafkaController请求,如果没有发送完成,就报错
controllerBrokerRequestBatch.newBatch()
// 调用doHandleStateChanges方法执行真正的状态变更逻辑
doHandleStateChanges(partitions, targetState, partitionLeaderElectionStrategyOpt)
// Controller给相关Broker发送请求通知状态变化
controllerBrokerRequestBatch.sendRequestsToBrokers(controllerContext.epoch)
} catch {
case e: Throwable => error(s"Error while moving some partitions to $targetState state", e)
}
}
}
三个参数说明:
- partitions 是待执行状态变更的目标分区列表
- targetState 是目标状态
- partitionLeaderElectionStrategyOpt 是一个可选项,如果传入了,就表示要执行 Leader 选举。
doHandleStateChanges
doHandleStateChanges方法执行真正的状态变更逻辑。
在这个方法中,可能需要用 为 partitions 选举新的 Leader,最终将 partitions 的 Leader 信息返回
private def doHandleStateChanges(partitions: Seq[TopicPartition], targetState: PartitionState,
partitionLeaderElectionStrategyOpt: Option[PartitionLeaderElectionStrategy]): Unit = {
val stateChangeLog = stateChangeLogger.withControllerEpoch(controllerContext.epoch)
// 检查分区的状态,如果没有,分区的状态设置为NonExistentPartition
partitions.foreach(partition => partitionState.getOrElseUpdate(partition, NonExistentPartition))
// 找出要执行非法状态转换的分区,记录错误日志
val (validPartitions, invalidPartitions) = partitions.partition(partition => isValidTransition(partition, targetState))
invalidPartitions.foreach(partition => logInvalidTransition(partition, targetState))
// 根据targetState进入到不同的case分支
targetState match {
case NewPartition =>
....
//4大分支
}
首先,这个方法会做状态检查工作。
检查分区的状态,如果没有,分区的状态设置为NonExistentPartition
接着,检查哪些分区执行的状态转换不合法,如果当前的状态不属于targetState的前置依赖,则为不合法。然后为这些分区记录相应的错误日志。
然后,就是重点和核心。
根据targetState进入到 case 分支。由于分区状态只有 4 个,其中,只有 OnlinePartition 这一路的分支逻辑相对复杂,其他 3 路仅仅是将分区状态设置成目标状态而已。
先看简单的3路。
targetState match {
case NewPartition =>
validPartitions.foreach { partition =>
stateChangeLog.trace(s"Changed partition $partition state from ${partitionState(partition)} to $targetState with " +
s"assigned replicas ${controllerContext.partitionReplicaAssignment(partition).mkString(",")}")
partitionState.put(partition, NewPartition)
}
case OnlinePartition =>
....
}
case OfflinePartition =>
validPartitions.foreach { partition =>
stateChangeLog.trace(s"Changed partition $partition state from ${partitionState(partition)} to $targetState")
partitionState.put(partition, OfflinePartition)
}
case NonExistentPartition =>
validPartitions.foreach { partition =>
stateChangeLog.trace(s"Changed partition $partition state from ${partitionState(partition)} to $targetState")
partitionState.put(partition, NonExistentPartition)
}
}
接下来,是负责的那一路,目标状态是 OnlinePartition 的分支。
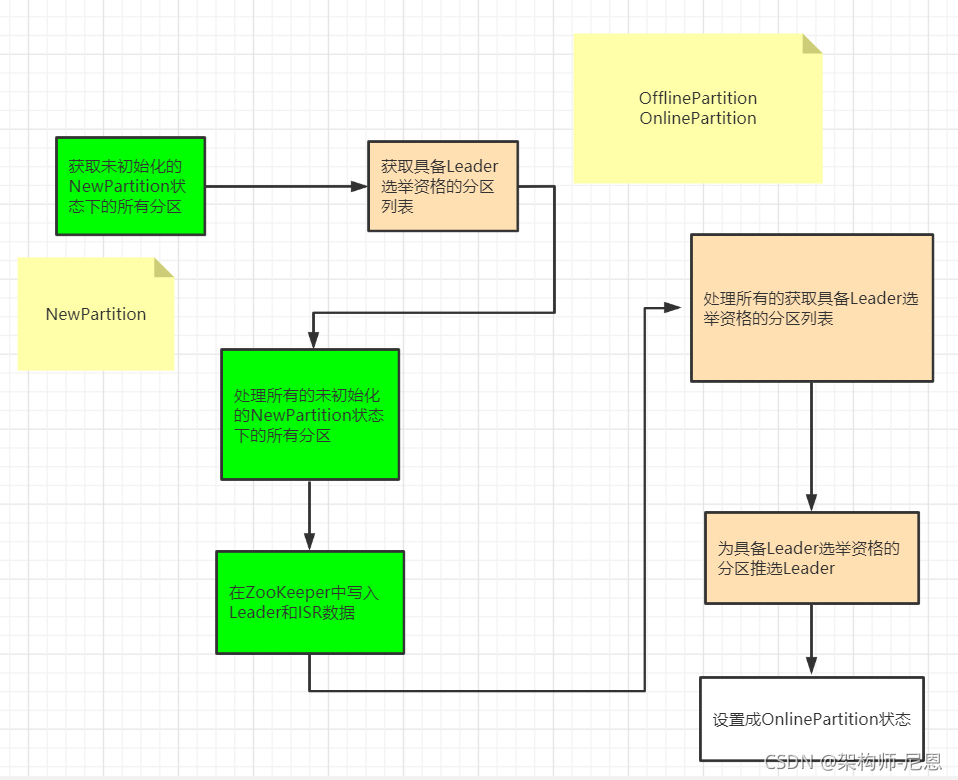
图解:目标状态是 OnlinePartition 的分支
流程图如下:
代码如下:
case OnlinePartition =>
// 获取未初始化的NewPartition状态下的所有分区
val uninitializedPartitions = validPartitions.filter(partition => partitionState(partition) == NewPartition)
// 获取具备Leader选举资格的分区列表
// 只能为OnlinePartition和OfflinePartition状态的分区选举Leader
val partitionsToElectLeader = validPartitions.filter(partition => partitionState(partition) == OfflinePartition || partitionState(partition) == OnlinePartition)
// 处理所有的未初始化的NewPartition状态下的所有分区
if (uninitializedPartitions.nonEmpty) {
// 初始化NewPartition状态分区,在ZooKeeper中写入Leader和ISR数据
// Initialize leader and isr partition state in zookeeper
val successfulInitializations = initializeLeaderAndIsrForPartitions(uninitializedPartitions)
successfulInitializations.foreach { partition =>
stateChangeLog.trace(s"Changed partition $partition from ${partitionState(partition)} to $targetState with state " +
s"${controllerContext.partitionLeadershipInfo(partition).leaderAndIsr}")
partitionState.put(partition, OnlinePartition)
}
}
// 处理所有的获取具备Leader选举资格的分区列表
if (partitionsToElectLeader.nonEmpty) {
// 为具备Leader选举资格的分区推选Leader
val successfulElections = electLeaderForPartitions(partitionsToElectLeader, partitionLeaderElectionStrategyOpt.get)
// 将成功选举Leader后的分区设置成OnlinePartition状态
successfulElections.foreach { partition =>
stateChangeLog.trace(s"Changed partition $partition from ${partitionState(partition)} to $targetState with state " +
s"${controllerContext.partitionLeadershipInfo(partition).leaderAndIsr}")
partitionState.put(partition, OnlinePartition)
}
}
图解:initializeLeaderAndIsrForPartitions初始化分区
处理所有的未初始化的NewPartition状态下的所有分区,需要在 ZooKeeper 中,创建并写入分区的znode节点数据。
znode节点的位置是/brokers/topics/partitions/,每个节点都要包含分区的 Leader 和 ISR 等数据。
ZK中partition状态信息
/brokers/topics/[topic]/partitions/[0...N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
Schema:
{
"controller_epoch": 表示kafka集群中的中央控制器选举次数,
"leader": 表示该partition选举leader的brokerId,
"version": 版本编号默认为1,
"leader_epoch": 该partition leader选举次数,
"isr": [同步副本组brokerId列表]
}
Example:
{
"controller_epoch": 1,
"leader": 2,
"version": 1,
"leader_epoch": 0,
"isr": [2, 1]
}

分区的Leader 和 ISR 的确定规则是:选择存活副本列表的第一个副本作为 Leader;选择存活副本列表作为 ISR。
具体的代码如下:
private def initializeLeaderAndIsrForPartitions(partitions: Seq[TopicPartition]): Seq[TopicPartition] = {
val successfulInitializations = mutable.Buffer.empty[TopicPartition]
// 获取每个分区的副本列表
val replicasPerPartition = partitions.map(partition => partition -> controllerContext.partitionReplicaAssignment(partition))
// 获取每个分区的所有存活副本
val liveReplicasPerPartition = replicasPerPartition.map { case (partition, replicas) =>
val liveReplicasForPartition = replicas.filter(replica => controllerContext.isReplicaOnline(replica, partition))
partition -> liveReplicasForPartition
}
// 按照有无存活副本对分区进行分组:有活副本的分区、无活副本的分区
val (partitionsWithoutLiveReplicas, partitionsWithLiveReplicas) = liveReplicasPerPartition.partition { case (_, liveReplicas) => liveReplicas.isEmpty }
partitionsWithoutLiveReplicas.foreach { case (partition, replicas) =>
val failMsg = s"Controller $controllerId epoch ${controllerContext.epoch} encountered error during state change of " +
s"partition $partition from New to Online, assigned replicas are " +
s"[${replicas.mkString(",")}], live brokers are [${controllerContext.liveBrokerIds}]. No assigned " +
"replica is alive."
logFailedStateChange(partition, NewPartition, OnlinePartition, new StateChangeFailedException(failMsg))
}
// 为"有活副本的分区"确定Leader和ISR
// Leader确认依据:存活副本列表的首个副本被认定为Leader
// ISR确认依据:存活副本列表被认定为ISR
val leaderIsrAndControllerEpochs = partitionsWithLiveReplicas.map { case (partition, liveReplicas) =>
val leaderAndIsr = LeaderAndIsr(liveReplicas.head, liveReplicas.toList)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
partition -> leaderIsrAndControllerEpoch
}.toMap
val createResponses = try {
zkClient.createTopicPartitionStatesRaw(leaderIsrAndControllerEpochs)
} catch {
case e: Exception =>
partitionsWithLiveReplicas.foreach { case (partition,_) => logFailedStateChange(partition, partitionState(partition), NewPartition, e) }
Seq.empty
}
createResponses.foreach { createResponse =>
val code = createResponse.resultCode
val partition = createResponse.ctx.get.asInstanceOf[TopicPartition]
val leaderIsrAndControllerEpoch = leaderIsrAndControllerEpochs(partition)
if (code == Code.OK) {
controllerContext.partitionLeadershipInfo.put(partition, leaderIsrAndControllerEpoch)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(leaderIsrAndControllerEpoch.leaderAndIsr.isr,
partition, leaderIsrAndControllerEpoch, controllerContext.partitionReplicaAssignment(partition), isNew = true)
successfulInitializations += partition
} else {
logFailedStateChange(partition, NewPartition, OnlinePartition, code)
}
}
successfulInitializations
}
图解:electLeaderForPartitions 选举分区Leader
处理所有的获取具备Leader选举资格的分区列表,为具备 Leader 选举资格的分区推选 Leader,代码调用 electLeaderForPartitions 方法实现。
这个方法会不断尝试为多个分区选举 Leader,直到所有分区都成功选出 Leader。
/**
* Repeatedly attempt to elect leaders for multiple partitions until there are no more remaining partitions to retry.
* @param partitions The partitions that we're trying to elect leaders for.
* @param partitionLeaderElectionStrategy The election strategy to use.
* @return The partitions that successfully had a leader elected.
*/
private def electLeaderForPartitions(partitions: Seq[TopicPartition], partitionLeaderElectionStrategy: PartitionLeaderElectionStrategy): Seq[TopicPartition] = {
val successfulElections = mutable.Buffer.empty[TopicPartition]
var remaining = partitions
//处理所有的获取具备Leader选举资格的分区列表,为具备 Leader 选举资格的分区推选 Leader,代码调用 electLeaderForPartitions 方法实现。
//不断尝试为多个分区选举 Leader,直到所有分区都成功选出 Leader。
while (remaining.nonEmpty) {
val (success, updatesToRetry, failedElections) = doElectLeaderForPartitions(partitions, partitionLeaderElectionStrategy)
remaining = updatesToRetry
successfulElections ++= success
failedElections.foreach { case (partition, e) =>
logFailedStateChange(partition, partitionState(partition), OnlinePartition, e)
}
}
successfulElections
}
选举 Leader 的核心代码位于 doElectLeaderForPartitions 方法中。
由于分区leader选举的代码比较复杂,在介绍之前,作为铺垫,为大家先介绍一下分区 Leader 选举的场景及方法。
分区 Leader 选举的场景及方法
分区online状态和分区leader选举有关,这里说说 分区 Leader 选举的场景及方法。
在kafka中,每个主题可以有多个分区,每个分区又可以有多个副本。这多个副本中,只有一个是leader,而其他的都是follower副本。
注意:每个分区都必须选举出 Leader副本 才能正常提供服务,没有leader副本,分区无法提供服务。
总之,在kafka的集群中,会存在着多个主题topic,在每个topic中,又被划分为多个partition,为了防止数据不丢失,每个partition又有多个副本。
kafka主要的三种副本角色
kafka主要的三种副本角色:
- 首领副本(leader):也就是leader主副本,每一个分区都有一个首领副本,为了保证数据一致性,全部的生产者与消费者的请求都会通过该副原本处理。
- 跟随者副本(follower):除了首领副本外的其余全部副本都是跟随者副本,跟随者副本不处理来自客户端的任何请求,只负责从首领副本同步数据,保证与首领保持一致。若是首领副本发生崩溃,就会从这其中选举出一个leader。
- 首选首领副本:建立分区时指定的首选首领。若是不指定,则为分区的第一个副本。
follower须要从leader中同步数据,可是因为网络或者其余缘由,致使数据阻塞,出现不一致的状况,为了不这种状况,follower会向leader发送请求信息,这些请求信息中包含了follower须要数据的偏移量offset,并且这些offset是有序的。
若是有follower向leader发送了请求1,接着发送请求2,请求3,那么再发送请求4,这时就意味着follower已经同步了前三条数据,不然不会发送请求4。leader经过跟踪 每个follower的offset来判断它们的复制进度。
默认的,若是follower与leader之间超过10s内没有发送请求,或者说没有收到请求数据,此时该follower就会被认为“不一样步副本”, 而持续请求的副本就是“同步副本”。
当leader发生故障时,只有“同步副本”才能够被选举为leader。其中的请求超时时间能够经过参数replica.lag.time.max.ms参数来配置。
负载均衡的最佳目标:
每一个分区的leader能够分布到不一样的broker中,尽量的达到最最佳的负载均衡效果。
因此会有一个首选首领,若是咱们设置参数auto.leader.rebalance.enable为true,那么它会检查首选首领是不是真正的首领,若是不是,则会触发选举,让首选首领成为首领。
啰嗦:Replica副本的几个术语
1、assignments
这是分区的副本列表。
该列表有个专属的名称,叫 Assigned Replicas,简称 AR。当我们 创建主题之后,使用 kafka-topics 脚本查看主题时,应该可以看到名为 Replicas 的一列数 据。这列数据显示的,就是主题下每个分区的 AR。assignments 参数类型是 Seq[Int]。这 揭示了一个重要的事实:AR 是有顺序的,而且不一定和 ISR 的顺序相同!
2、isr
ISR 在 Kafka 中很有名气,它保存了分区所有与 Leader 副本保持同步的副本列表。
注意, Leader 副本自己也在 ISR 中。另外,作为 Seq[Int]类型的变量,isr 自身也是有顺序的。
3、liveReplicas
从名字可以推断出,它保存了该分区下所有处于存活状态的副本。
怎么判断副本是否存活 呢?可以根据 Controller 元数据缓存中的数据来判定。简单来说,所有在运行中的 Broker 上的副本,都被认为是存活的。
4、uncleanLeaderElectionEnabled
在默认配置下,只要不是由 AdminClient 发起的 Leader 选举,这个参数的值一般是 false,即 Kafka 不允许执行 Unclean Leader 选举。
所谓的 Unclean Leader 选举,是指 在 ISR 列表为空的情况下,Kafka 选择一个非 ISR 副本作为新的 Leader。
由于存在丢失数 据的风险,目前,社区已经通过把 Broker 端参数 unclean.leader.election.enable 的默认 值设置为 false 的方式,禁止 Unclean Leader 选举了。
代码首先会顺序搜索 AR 列表,并把第一个同时满足以下两个条件的副本作为新的 Leader 返回:
- 该副本是存活状态,即副本所在的 Broker 依然在运行中;
- 该副本在 ISR 列表中。
分区 Leader 选举有 4 类场景
// 分区Leader选举策略接口
sealed trait PartitionLeaderElectionStrategy
// 离线分区Leader选举策略
case object OfflinePartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// 分区副本重分配Leader选举策略
case object ReassignPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// 分区Preferred副本Leader选举策略
case object PreferredReplicaPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
// Broker Controlled关闭时Leader选举策略
case object ControlledShutdownPartitionLeaderElectionStrategy extends PartitionLeaderElectionStrategy
- OfflinePartitionLeaderElectionStrategy:
因为 Leader 副本下线而引发的分区 Leader 选举。
- ReassignPartitionLeaderElectionStrategy:
因为执行分区副本重分配操作而引发的分 区 Leader 选举。
- PreferredReplicaPartitionLeaderElectionStrategy:
因为执行 Preferred 副本 Leader 选举而引发的分区 Leader 选举。
- ControlledShutdownPartitionLeaderElectionStrategy:
因为正常关闭 Broker 而引发 的分区 Leader 选举。
scala基础
上面使用到了 case object,补充下scala基础知识
Scala中class、object、case class、case object区别
/** class、object、case class、case object区别
*
* class: 类似Java中的class;
* object: 类似java的单例对象,Scala不能定义静态成员,用定义单例对象代之;
* case class:被称为样例类,是一种特殊的类,常被用于模式匹配。
*
* 一、class 和 object 关系:
* 1.单例对象不能带参数,类可以
* 2.当对象和类名一样时,object被称为伴生对象,class被称为伴生类;
* 3.类和伴生对象可以相互访问其私有属性,但是它们必须在一个源文件当中;
* 4.类只会被编译,不会被执行。要执行,必须在Object中。
*
* 二、case class 与 class 区别:
* 1.初始化的时候可以不用new,也可以加上,但是普通类必须加new;
* 2.默认实现了equals、hashCode方法;
* 3.默认是可以序列化的,实现了Serializable;
* 4.自动从scala.Product中继承一些函数;
* 5.case class 构造函数参数是public的,我们可以直接访问;
* 6.case class默认情况下不能修改属性值;
* 7.case class最重要的功能,支持模式匹配,这也是定义case class的重要原因。
*
* 三、case class 和 case object 区别:
* 1.类中有参和无参,当类有参数的时候,用case class ,当类没有参数的时候那么用case object。
*
* 四、当一个类被声名为case class的时候,scala会帮助我们做下面几件事情:
* 1.构造器中的参数如果不被声明为var的话,它默认的话是val类型的,但一般不推荐将构造器中的参数声明为var
* 2.自动创建伴生对象,同时在里面给我们实现子apply方法,使得我们在使用的时候可以不直接显示地new对象
* 3.伴生对象中同样会帮我们实现unapply方法,从而可以将case class应用于模式匹配,关于unapply方法我们在后面的“提取器”那一节会重点讲解
* 4.实现自己的toString、hashCode、copy、equals方法
* 除此之此,case class与其它普通的scala类没有区别
*/
case class Iteblog(name:String)
object TestScala {
def main(args: Array[String]): Unit = {
val iteblog = new Iteblog("iteblog_hadoop")
val iteblog2 = Iteblog("iteblog_hadoop")
println(iteblog == iteblog2)
println(iteblog.hashCode)
println(iteblog2.hashCode)
}
}
PartitionLeaderElectionAlgorithms
针对这 4 类场景,分区状态机的 PartitionLeaderElectionAlgorithms 对象定义了 4 个方 法,分别负责为每种场景选举 Leader 副本,这 4 种方法是:
- offlinePartitionLeaderElection;
- reassignPartitionLeaderElection;
- preferredReplicaPartitionLeaderElection;
- controlledShutdownPartitionLeaderElection。
具体的模式匹配代码在doElectLeaderForPartitions方法中如下:
val (partitionsWithoutLeaders, partitionsWithLeaders) = partitionLeaderElectionStrategy match {
case OfflinePartitionLeaderElectionStrategy =>
// 离线分区Leader选举策略
leaderForOffline(validPartitionsForElection).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
case ReassignPartitionLeaderElectionStrategy =>
// 分区副本重分配Leader选举策略
leaderForReassign(validPartitionsForElection).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
case PreferredReplicaPartitionLeaderElectionStrategy =>
// 分区Preferred副本Leader选举策略
leaderForPreferredReplica(validPartitionsForElection).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
case ControlledShutdownPartitionLeaderElectionStrategy =>
// Broker Controlled关闭时Leader选举策略
leaderForControlledShutdown(validPartitionsForElection, shuttingDownBrokers).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
}
接下来,我们回到重点方法:doElectLeaderForPartitions的介绍。
重点方法:doElectLeaderForPartitions
step1:获取可选举Leader分区列表
首先,doElectLeaderForPartitions是从 ZooKeeper 中获取给定partitions分区的 Leader、ISR 信息,并将结果封装进名为 leaderIsrAndControllerEpochPerPartition 的容器中,代码如下:
private def doElectLeaderForPartitions(partitions: Seq[TopicPartition], partitionLeaderElectionStrategy: PartitionLeaderElectionStrategy):
(Seq[TopicPartition], Seq[TopicPartition], Map[TopicPartition, Exception]) = {
val getDataResponses = try {
//step1:获取可选举Leader分区列表
// 获取ZooKeeper中给定partitions分区的znode节点数据
zkClient.getTopicPartitionStatesRaw(partitions)
} catch {
case e: Exception =>
return (Seq.empty, Seq.empty, partitions.map(_ -> e).toMap)
}
//选举失败分区列表map容器
val failedElections = mutable.Map.empty[TopicPartition, Exception]
//可选举Leader分区列表map容器
val leaderIsrAndControllerEpochPerPartition = mutable.Buffer.empty[(TopicPartition, LeaderIsrAndControllerEpoch)]
// 遍历每个分区的znode节点数据
getDataResponses.foreach { getDataResponse =>
val partition = getDataResponse.ctx.get.asInstanceOf[TopicPartition]
val currState = partitionState(partition)
// 如果成功拿到znode节点数据
if (getDataResponse.resultCode == Code.OK) {
val leaderIsrAndControllerEpochOpt = TopicPartitionStateZNode.decode(getDataResponse.data, getDataResponse.stat)
if (leaderIsrAndControllerEpochOpt.isEmpty) {
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
failedElections.put(partition, exception)
}
// 将该分区加入到可选举Leader分区列表
leaderIsrAndControllerEpochPerPartition += partition -> leaderIsrAndControllerEpochOpt.get
} else if (getDataResponse.resultCode == Code.NONODE) {
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
// 如果没有拿到znode节点数据,则将该分区加入到选举失败分区列表
failedElections.put(partition, exception)
} else {
failedElections.put(partition, getDataResponse.resultException.get)
}
}
...
}
遍历完这些分区之后,leaderIsrAndControllerEpochPerPartition 容器中是否包含可选举 Leader 的分区。
step2,进行 Controller Epoch 的年代判断
接着,进行 Controller Epoch 的年代判断:
-
节点数据包含 Leader 和 ISR 信息且节点数据的 Controller Epoch 值小于当前 Controller Epoch 值,那么,就将该分区加入到可选举 Leader 分区列表validPartitionsForElection。
-
倘若发现 Zookeeper 中保存的 Controller Epoch 值大于当前 Epoch 值,说明该分区已经被一个更新的 Controller 选举过 Leader 了,将该分区放置到选举失败分区列表中invalidPartitionsForElection。
如果validPartitionsForElection为空,则终止本次选举。
//接着,进行 Controller Epoch 的年代判断:
// 节点数据包含 Leader 和 ISR 信息且节点数据的 Controller Epoch 值小于当前 Controller Epoch 值,
// 那么,就将该分区加入到可选举 Leader 分区列表。
// 倘若 Controller Epoch 值大于当前Controller Epoch 值,
// 说明该分区已经被一个更新的 Controller 选举过 Leader 了,此时必须终止本次 Leader 选举,并将该分区放置到选举失败分区列表中
val (invalidPartitionsForElection, validPartitionsForElection) = leaderIsrAndControllerEpochPerPartition.partition { case (partition, leaderIsrAndControllerEpoch) =>
leaderIsrAndControllerEpoch.controllerEpoch > controllerContext.epoch
}
invalidPartitionsForElection.foreach { case (partition, leaderIsrAndControllerEpoch) =>
val failMsg = s"aborted leader election for partition $partition since the LeaderAndIsr path was " +
s"already written by another controller. This probably means that the current controller $controllerId went through " +
s"a soft failure and another controller was elected with epoch ${leaderIsrAndControllerEpoch.controllerEpoch}."
failedElections.put(partition, new StateChangeFailedException(failMsg))
}
if (validPartitionsForElection.isEmpty) {
return (Seq.empty, Seq.empty, failedElections.toMap)
}
step3:调用 PartitionLeaderElectionAlgorithms 的不同方法执行 Leader 选举
这一步是根据给定的 PartitionLeaderElectionStrategy,调用 PartitionLeaderElectionAlgorithms 的不同方法执行 Leader 选举
//step3:调用 PartitionLeaderElectionAlgorithms 的不同方法执行 Leader 选举
//根据给定的 PartitionLeaderElectionStrategy,调用 PartitionLeaderElectionAlgorithms 的不同方法执行 Leader 选举
val shuttingDownBrokers = controllerContext.shuttingDownBrokerIds.toSet
val (partitionsWithoutLeaders, partitionsWithLeaders) = partitionLeaderElectionStrategy match {
case OfflinePartitionLeaderElectionStrategy =>
// 离线分区Leader选举策略
leaderForOffline(validPartitionsForElection).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
case ReassignPartitionLeaderElectionStrategy =>
// 分区副本重分配Leader选举策略
leaderForReassign(validPartitionsForElection).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
case PreferredReplicaPartitionLeaderElectionStrategy =>
// 分区Preferred副本Leader选举策略
leaderForPreferredReplica(validPartitionsForElection).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
case ControlledShutdownPartitionLeaderElectionStrategy =>
// Broker Controlled关闭时Leader选举策略
leaderForControlledShutdown(validPartitionsForElection, shuttingDownBrokers).partition { case (_, newLeaderAndIsrOpt, _) => newLeaderAndIsrOpt.isEmpty }
}
这 4 种不同的策略定义了 4 个专属的方法来进行 Leader 选举。
大致的选择 Leader 的规则,就是选择副本集合中首个存活且处于 ISR 中的副本作为 Leader
以leaderForOffline为例子吧:
private def leaderForOffline(leaderIsrAndControllerEpochs: Seq[(TopicPartition, LeaderIsrAndControllerEpoch)]):
Seq[(TopicPartition, Option[LeaderAndIsr], Seq[Int])] = {
....
} ++ partitionsWithLiveInSyncReplicas.map { case (partition, leaderIsrAndControllerEpoch) => (partition, Option(leaderIsrAndControllerEpoch), false) }
partitionsWithUncleanLeaderElectionState.map { case (partition, leaderIsrAndControllerEpochOpt, uncleanLeaderElectionEnabled) =>
//获取全部副本
val assignment = controllerContext.partitionReplicaAssignment(partition)
//获取存活副本
val liveReplicas = assignment.filter(replica => controllerContext.isReplicaOnline(replica, partition))
if (leaderIsrAndControllerEpochOpt.nonEmpty) {
val leaderIsrAndControllerEpoch = leaderIsrAndControllerEpochOpt.get
val isr = leaderIsrAndControllerEpoch.leaderAndIsr.isr
//通过算法选举一个leader
val leaderOpt = PartitionLeaderElectionAlgorithms.offlinePartitionLeaderElection(assignment, isr, liveReplicas.toSet, uncleanLeaderElectionEnabled, controllerContext)
val newLeaderAndIsrOpt = leaderOpt.map { leader =>
val newIsr = if (isr.contains(leader)) isr.filter(replica => controllerContext.isReplicaOnline(replica, partition))
else List(leader)
leaderIsrAndControllerEpoch.leaderAndIsr.newLeaderAndIsr(leader, newIsr)
}
(partition, newLeaderAndIsrOpt, liveReplicas)
} else {
(partition, None, liveReplicas)
}
}
}
4种选举leader的算法:
4种选举leader的算法也类同,大致选择副本集合中首个存活且处于 ISR 中的副本作为 Leader。
object PartitionLeaderElectionAlgorithms {
def offlinePartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], uncleanLeaderElectionEnabled: Boolean, controllerContext: ControllerContext): Option[Int] = {
//返回第一个存活的、在isr中的副本
//如果没有找到,就找一个存活副本
assignment.find(id => liveReplicas.contains(id) && isr.contains(id)).orElse {
if (uncleanLeaderElectionEnabled) {
val leaderOpt = assignment.find(liveReplicas.contains)
if (!leaderOpt.isEmpty)
controllerContext.stats.uncleanLeaderElectionRate.mark()
leaderOpt
} else {
None
}
}
}
def reassignPartitionLeaderElection(reassignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
//返回第一个存活的、在isr中的副本
reassignment.find(id => liveReplicas.contains(id) && isr.contains(id))
}
def preferredReplicaPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int]): Option[Int] = {
assignment.headOption.filter(id => liveReplicas.contains(id) && isr.contains(id))
}
def controlledShutdownPartitionLeaderElection(assignment: Seq[Int], isr: Seq[Int], liveReplicas: Set[Int], shuttingDownBrokers: Set[Int]): Option[Int] = {
assignment.find(id => liveReplicas.contains(id) && isr.contains(id) && !shuttingDownBrokers.contains(id))
}
}
step4:zk元数据和Controller 端元数据缓存信息的更新
再来看这个方法的最后一部分代码,这一步主要是更新 ZooKeeper 节点数据,以及 Controller 端元数据缓存信息。
// 将所有选举失败的分区全部加入到Leader选举失败分区列表
partitionsWithoutLeaders.foreach { case (partition, leaderAndIsrOpt, recipients) =>
val failMsg = s"Failed to elect leader for partition $partition under strategy $partitionLeaderElectionStrategy"
failedElections.put(partition, new StateChangeFailedException(failMsg))
}
val recipientsPerPartition = partitionsWithLeaders.map { case (partition, leaderAndIsrOpt, recipients) => partition -> recipients }.toMap
val adjustedLeaderAndIsrs = partitionsWithLeaders.map { case (partition, leaderAndIsrOpt, recipients) => partition -> leaderAndIsrOpt.get }.toMap
// 使用新选举的Leader和ISR信息更新ZooKeeper上分区的znode节点数据
val UpdateLeaderAndIsrResult(successfulUpdates, updatesToRetry, failedUpdates) = zkClient.updateLeaderAndIsr(
adjustedLeaderAndIsrs, controllerContext.epoch)
// 对于ZooKeeper znode节点数据更新成功的分区,封装对应的Leader和ISR信息
// 构建LeaderAndIsr请求,并将该请求加入到Controller待发送请求的集合中
// 等待后续批量发送
successfulUpdates.foreach { case (partition, leaderAndIsr) =>
val replicas = controllerContext.partitionReplicaAssignment(partition)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
controllerContext.partitionLeadershipInfo.put(partition, leaderIsrAndControllerEpoch)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipientsPerPartition(partition), partition,
leaderIsrAndControllerEpoch, replicas, isNew = false)
}
// 返回选举结果,包括成功选举并更新ZooKeeper节点的分区、选举失败分区以及
// ZooKeeper节点更新失败的分区
(successfulUpdates.keys.toSeq, updatesToRetry, failedElections.toMap ++ failedUpdates)
对于 ZooKeeper Znode 节点数据更新成功的那些分区,源码会封装对应的 Leader 和 ISR 信息,构建 LeaderAndIsr 请求,并将该请求加入到 Controller 待发送请求集合,等待后续统一发送。最后,方法返回选举结果,包括成功选举并更新 ZooKeeper 节点的分区列表、选举失败分区列表,以及 ZooKeeper 节点更新失败的分区列表。
参考文献
https://www.cnblogs.com/boanxin/p/13696136.html
https://www.cnblogs.com/listenfwind/p/12465409.html
https://www.shangmayuan.com/a/5e15939288954d3cb3ad613e.html
https://my.oschina.net/u/3070368/blog/4338739