选一个自己感兴趣的主题或网站。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
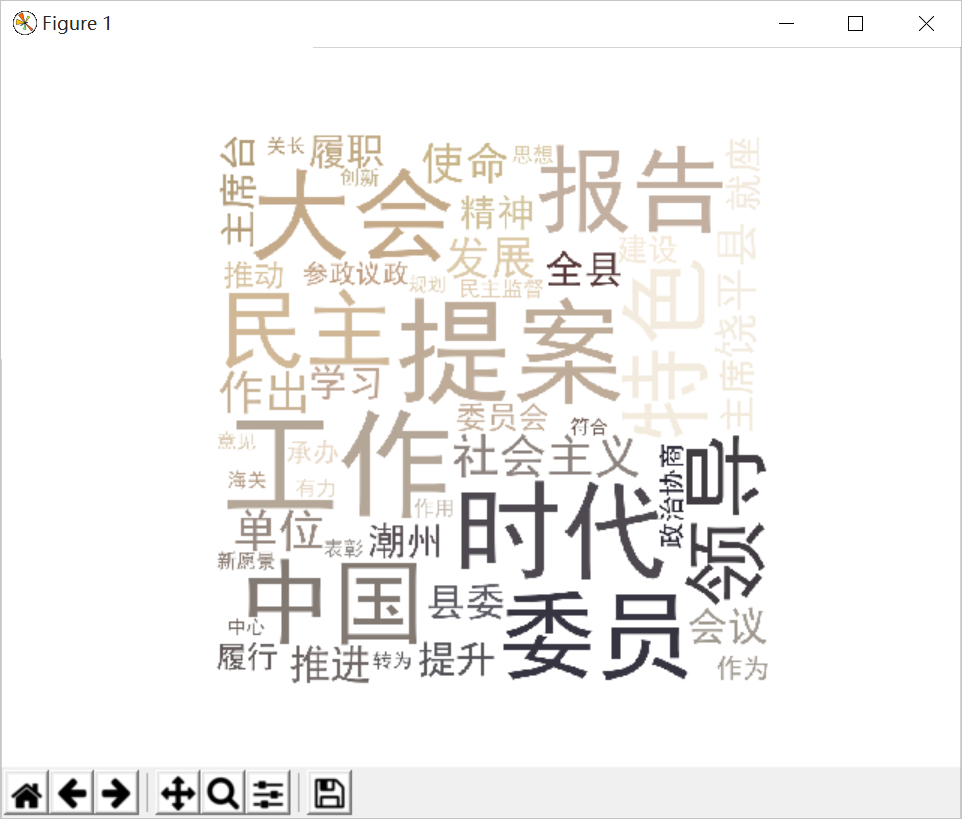
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
#-*- coding: UTF-8 -*- import requests import re import pandas from bs4 import BeautifulSoup import datetime import time import pymysql import matplotlib.pyplot as plt import jieba.analyse from wordcloud import WordCloud,ImageColorGenerator import numpy as np from PIL import Image,ImageSequence from os import path def writeNewsDetail(content): f = open('fly.txt','a',encoding='utf-8') f.write(content) f.close() def getNewDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') # print(resd.text) content = soupd.select('.conTxt #fontzoom p') a = int(len(content)) for i in range(0,int(len(content))): f = open('fly.txt', 'a', encoding='utf-8') f.write(content[i].text) f.write(" ") f.close() # news = {} # news['标题'] = soupd.select('.headline')[0].text.strip() # info = soupd.select('.artical-info')[0].text # if info.find('来源:') > 0: # news['来源'] = info[info.find('来源:'):].split()[0].lstrip('来源:') # news['发布时间'] = datetime.strptime(info.lstrip(' ')[-23:-1].strip(), '%Y-%m-%d %H:%M:%S') # news['编辑'] = soupd.select('#editor_baidu')[0].text.strip(')').split(':')[1] # news['链接'] = newsUrl # fly = soupd.select('.artical-main-content')[0].text.strip() # writeNewsDetail(fly) # return news newsurl = 'http://www.raoping.gov.cn/Item/33226.aspx' getNewDetail(newsurl) lyric = '' f = open('fly.txt', 'r',encoding='utf-8') for i in f: lyric += f.read() result = jieba.analyse.textrank(lyric, topK=50, withWeight=True) keywords = dict() for i in result: keywords[i[0]] = i[1] print(keywords) image = Image.open('001.jpg') graph = np.array(image) wc = WordCloud(font_path='./fonts/simhei.ttf', background_color='White', max_words=50, mask=graph) wc.generate_from_frequencies(keywords) image_color = ImageColorGenerator(graph) plt.imshow(wc) plt.imshow(wc.recolor(color_func=image_color)) plt.axis("off") plt.show() wc.to_file('dd.jpg')