Linux-鸟菜-7-Linux文件系统-EXT
Linux最传统的磁盘文件系统(filesystem)使用的是EXT2,所以先从EXT2开始了解。
/dev/sd[a-p][1-128] 为实体磁盘的磁盘文件名
/dev/vd[a-d][1-128] 为虚拟磁盘的磁盘文件名
Ext2(Linux second extended file system,ext2fs)
一个可被挂载的数据为一个文件系统而不是一个分区槽。
文件系统通常会将这两部分的数据分别存放在不同的区块,权限与属性放置到inode中,至于实际数据则放置到data block 区块中。另外,还有一个超级区块(superblock)会记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等。
每个inode与block都有编号,相关数据意义如下:
Superblock: 记录此filesystem的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息等。
Inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码。
Block:实际记录文件的内容,若文件太大时,会占用多个block。
Inode/block资料存储示意图(索引式文件系统)
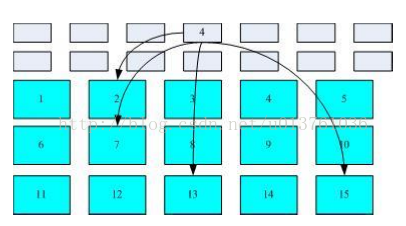
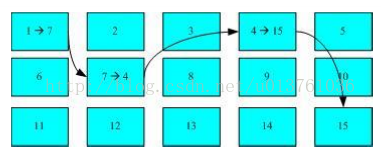
FAT文件系统图
文件系统一开始就将inode与block规划好了,除非重新格式化(或者利用resize2fs等指令更改文件系统大小),否则inode与block固定后就不再变动。但是如果文件系统过大,将所有inode与block放在一起有点不好维护。于是Ext2文件系统在格式化的时候基本上是区分为多个区块群组(block group)的,每个区块群组都有独立的inode/block/superblock系统。
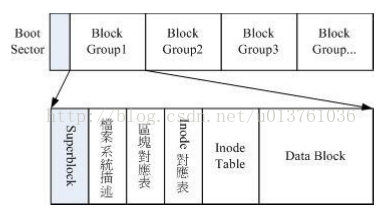
在整体的规划当中,文件系统最前面有一个启动山扇区(boot sector),这个启动扇区可以安装开机管理程序,这个非常重要的设计,因为这样就可以将不同的开机管理程序安装到个别的文件系统最前端,而不用覆盖磁盘卫衣MBR,这样也才能制作出多重引导的环境。Block group下面的留个模块下面细说:
Data block [以ext2系统为例]
实际存储数据的地方,有编号,大小可以为1 2 4 K,在格式化的时候确定的,根据大小的不同,导致系统对文件管理的限制也就不同。如下:

*原则上,block的大小与数量在格式化完就不能够再改变了(除非重新格式化);
*每个block内最多只能防止一个文件的数据;
*如果文件大于block的大小,这一个文件会占用多个block数量;
*若文件小于block,则该block的剩余容量就不能够再被使用了(磁盘空间浪费)
Inode table(inode 表格)
*该文件的存储模式(rwx);
*该文件的拥有者与组群(owner/group);
*该文件的容量;
*该文件建立或状态改变的时间(ctime);
*该文件最近一次的读取时间(atime);
*最近修改时间(mtime);
*定义特殊性的标志,如SetUID
*真正内容指向(pointer);
*每个inode大小均固定为128bytes(新的ext4与xfs可设定到256bytes);
*每个文件都仅会占用一个inode而已;
*因此文件系统能够建立的文件数与inode数量有关;
*系统读取文件时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够开始读取block的内容。
下面例子是展示128b的inode怎么存400MB的文件,通常每个block占用4b的index。直接存肯定不够,假如block位4K,那么400MB/4K*4b 远远大于128b,而每个文件又只能使用一个index来存,所以出现了直接,间接,双间接三间接等等。
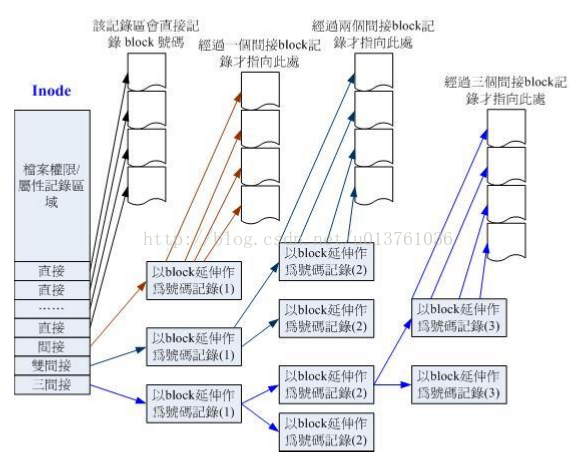
Inode(假如block=1K)
12个直连接指向:12*1K=12K
间接 :256*1K=256K
双间接:256*256*1K=256^2K
三间接:256*256*256*1K=256^3K
总值:
将直连接、间接、双间接、三间接贾总,得到12+256+256*256+256*256*256=16G
所以当block为1K大小时,能够容纳的最大文件为16GB,但是不能用同样的方法计算2K以及4K block,因为大雨2K的block将会受到Ext2文件系统本身的限制。
Superblock(超级区块)
Suiperblock是记录整个filesystem相关信息的地方,没有Superblock就没有filesystem了。
*block与inode的总量;
*未使用与已使用的inode/block数量;
*block与inode的大小(block与1,2,3K,inode为128/256bytes);
*filesystem的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等文件系统相关信息;
*一个validbit的数值,若此文件系统已被挂载,则valid bit为0,若未被挂载,则valid bit为1。
Superblock的大小为1024bytes,每个block group都可能含有superblock,但是我们也说一个文件系统应该仅有一个superblock,事实上除了第一个block group内会含有superblock之外,后续的block group不一定含有superblock,而若有superblock则该superblock主要是做为第一个block group内superblock的备份。
Filesystem Description(文件系统描述说明)
这个区段可以描述每个block group的开始于结束的block号码,以及说明每个区段(superblock bitmap inodemap datablock)分别位于哪一个block号码之间。
Block bitmap(区块对照表)
从block bitmap 当中可以知道哪些block是空的,因此我们的系统就能够很快速的找到可以使用空间来处理文件。同时如果删除文件时,也会在这里标记相关位置是空的了。
Inode bitmap(inode对照表)
和上面一样,只不过这个是标记inode的。
查看superblock用dumpe2fs相关命令,xfs(CentOS 7.X)用不了。
与目录树的关系
在Linux上建立一个目录时,文件系统会分配一个inode与至少一块block给该目录。其中,inode记录该目录的相关权限与属性,并记录分配到的那块block号码;而block则是记录在这个目录下的文件名与该文件名占用的inode号码数据。如下block记录的:

想要观察文件占用的inode号码时,可以使用 ls -i

目录树读取
经过上面的说明克制,inode本身宾补记录文件名,文件名的记录是在目录的block中,所以之前说 文件增删改查与目录的w权限有关。那么因为文件名是记录在目录的block当中,因此当我们要读取某个文件时,就无比会经过目录的inode与block,然后才能找到那个带读取文件的inode号码,最后才会督导正确文件的block内的数据。
由于目录是是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode号码,次数就能够找到根目录的inode内容,并依据该inode读取根目录的block内文件名的数据,再一层一层的往下读到正确的文件。