为什么会用到缓存?
为了减少与数据库链接所消耗的时间,将查询到的内容放到内存中去,下次查询直接取用就ok了。
缓存的适应场景:
1.经常查询并且不经常改变的。
2.数据的正确与否对最终结果影响不大的。
缓存的种类:
一级缓存:一级缓存是 SqlSession 级别的缓存,只要 SqlSession 没有 flush 或 close,它就存在(默认开启无需配置)。
二级缓存:二级缓存是 mapper 映射级别的缓存,多个 SqlSession 去操作同一个 Mapper 映射的 sql 语句,多个SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。
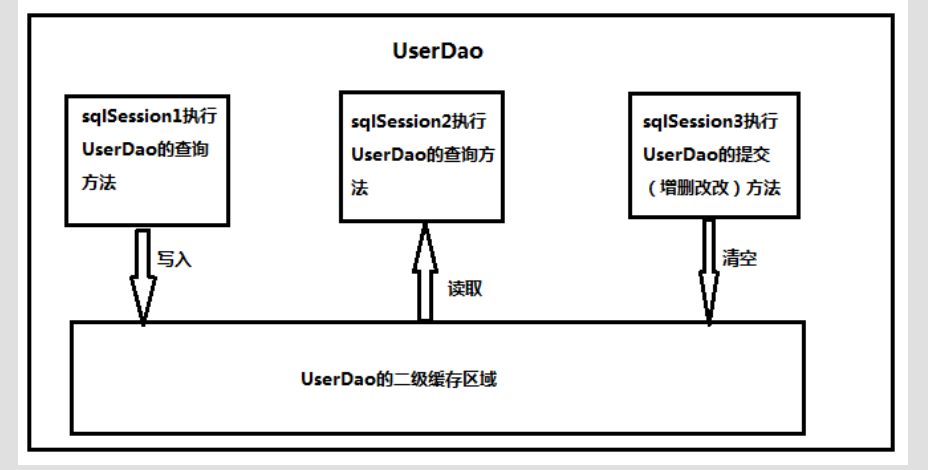
查询两次id为52的用户

查询语句只执行一次(user1和user2相同)

查询两次id为52的用户,中途关闭Sqlsession对象
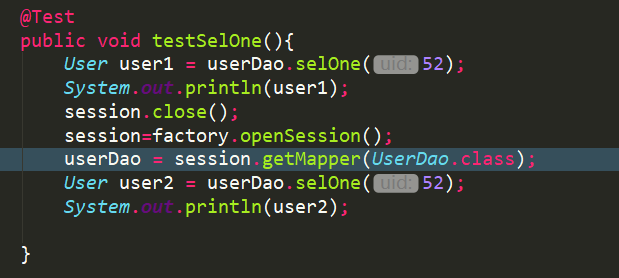
执行两遍SQl语句(user1和user2不相同了):
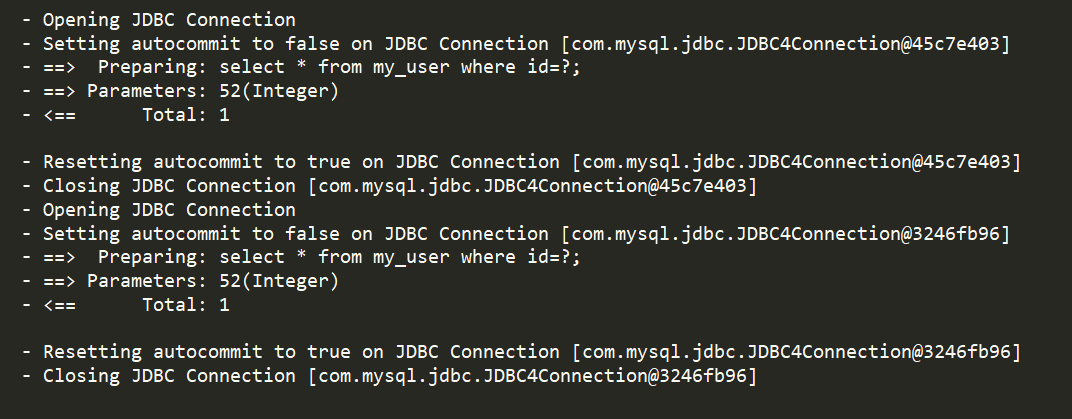
查询两次id为52的用户,中途插入更新操作
执行便便SQL语句(user1不等于user2):

二级缓存
<settings> <!-- 开启二级缓存的支持 --> <setting name="cacheEnabled" value="true"/> </settings> <!--因为 cacheEnabled 的取值默认就为 true,所以这一步可以省略不配置。为 true 代表开启二级缓存;为false 代表不开启二级缓存。-->
<!-- <cache>标签表示当前这个 mapper 映射将使用二级缓存,区分的标准就看 mapper 的 namespace 值。--> <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.zyb.dao.UserDao"> <!-- 开启二级缓存的支持 --> <cache></cache> </mapper>

注意:
什么是懒加载
懒加载也就是常说的延迟加载、按需加载等等。
在真正使用数据时才发起查询,不用的时候不查询。
懒加载的好处:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
懒加载的适应场景:
在对应的四种表关系中:一对多,多对一,一对一,多对多
一对多,多对多:通常情况下我们都是采用延迟加载。
多对一,一对一:通常情况下我们都是采用立即加载。
例如:当我们查询一个用户时有可能只是想查询它的基本信息(一对一)而不想知道他多个银行账户的信息
表结构见:https://www.cnblogs.com/cstdio1/p/11914831.html
下面的案例就是按需查询:
当将下面的通过用户查询账户的方法(一对多)注释掉之后:
结果:只执行了查询所有用户的单表操作

去掉注释之后(会联合表进行查询):
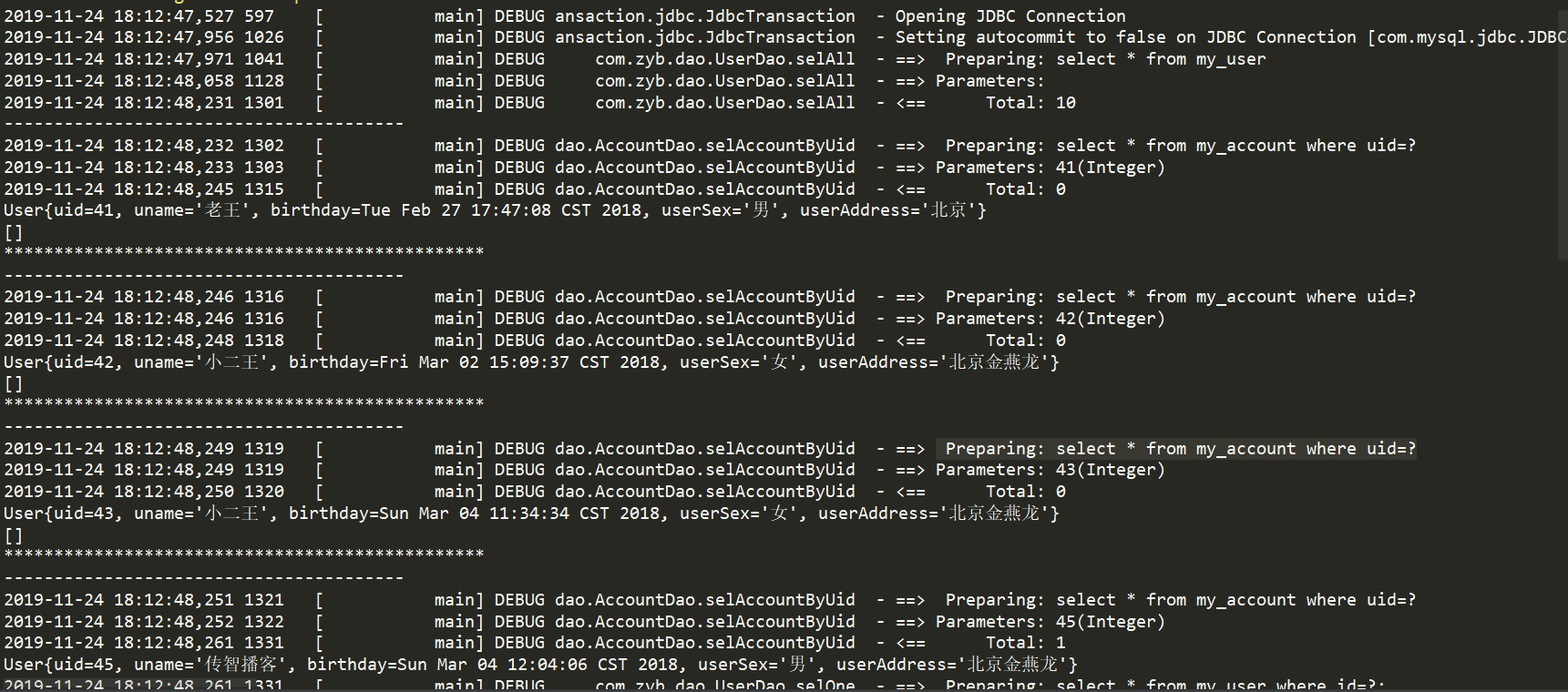
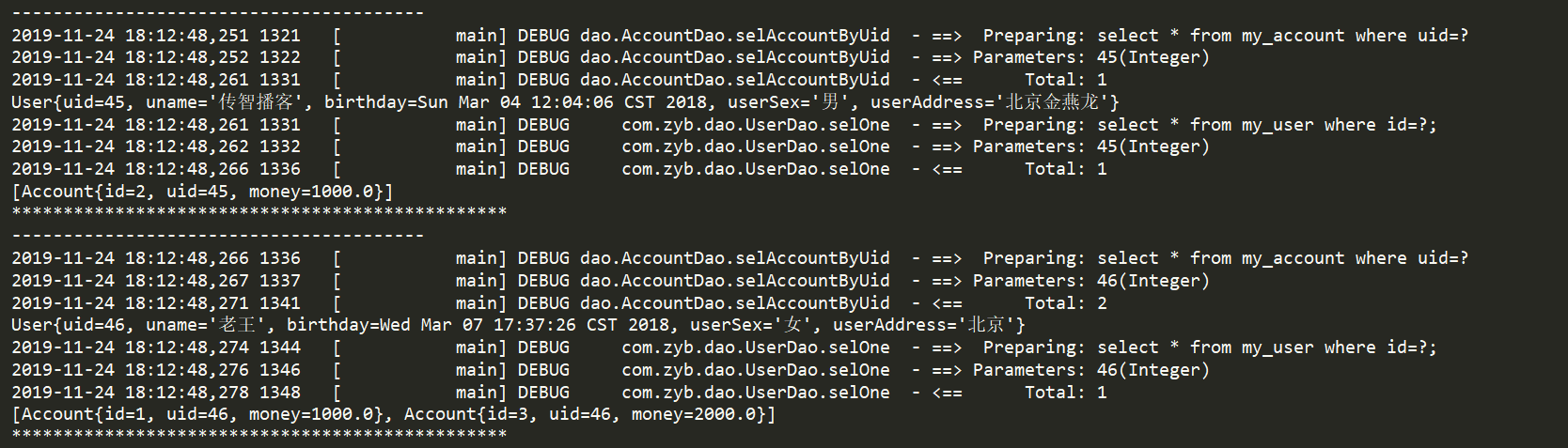
accountMapper.xml的配置:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.zyb.dao.AccountDao"> <resultMap id="accountUserMap" type="com.zyb.pojo.Account"> <!-- 没起别名account_id改回为id--> <id property="id" column="id"></id> <result property="uid" column="uid"></result> <result property="money" column="money"></result> <!-- 一对一关系映射配置user的--> <!-- 这里的Column是uid我觉得是和下面的uid=#{uid}有关--> <association property="user" javaType="user" column="uid" select="com.zyb.dao.UserDao.selOne"> <!--主键字段对应--> <id property="uid" column="id"></id> <!-- 非主键属性对应--> <result property="uname" column="username"></result> <result property="birthday" column="birthday"></result> <result property="userSex" column="sex"></result> <result property="userAddress" column="address"></result> </association> </resultMap> <select id="selAllAccount" resultMap="accountUserMap" > select * from my_account </select> <select id="selAllAccount2User" resultType="com.zyb.pojo.Account" resultMap="accountUserMap" > -- select u.*,a.id as account_id,a.money,a.uid from my_user u,my_account a where a.UID=u.id select * from my_account </select> <select id="selAccountByUid" parameterType="int" resultMap="accountUserMap"> select * from my_account where uid=#{uid} </select> </mapper>
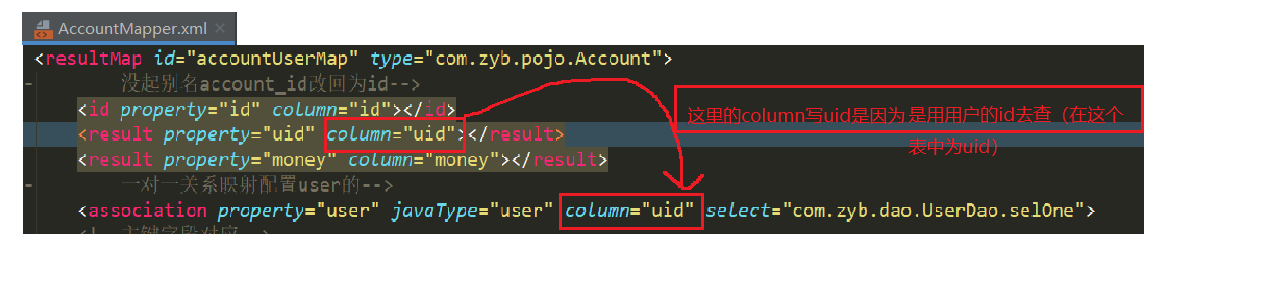
userMapper.xml的配置:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.zyb.dao.UserDao"> <!-- 返回类型可以写成user是因为我在mybatis-config.xml已经声明了,否则得写全限定类名--> <resultMap id="userMap" type="user"> <!--主键字段对应--> <id property="uid" column="id"></id> <!-- 非主键属性对应--> <result property="uname" column="username"></result> <result property="birthday" column="birthday"></result> <result property="userSex" column="sex"></result> <result property="userAddress" column="address"></result> <!-- 这里写accounts是因为在User中List<Account>的变量名为accounts--> <!--这里的column是id我觉得是和where id=#{uid};相关--> <collection property="accounts" ofType="com.zyb.pojo.Account" column="id" select="com.zyb.dao.AccountDao.selAccountByUid"> <!-- aid是列名重复SQl语句起别名的缘故--> <id property="id" column="id"></id> <result property="uid" column="uid"></result> <result property="money" column="money"></result> </collection> </resultMap> <sql id="defaultSql"> select * from my_user </sql> <select id="selAll" resultMap="userMap"> select * from my_user <!--根据id查询一个人--> </select> <select id="selOne" resultMap="userMap" parameterType="int"> select * from my_user where id=#{uid}; </select> </mapper>
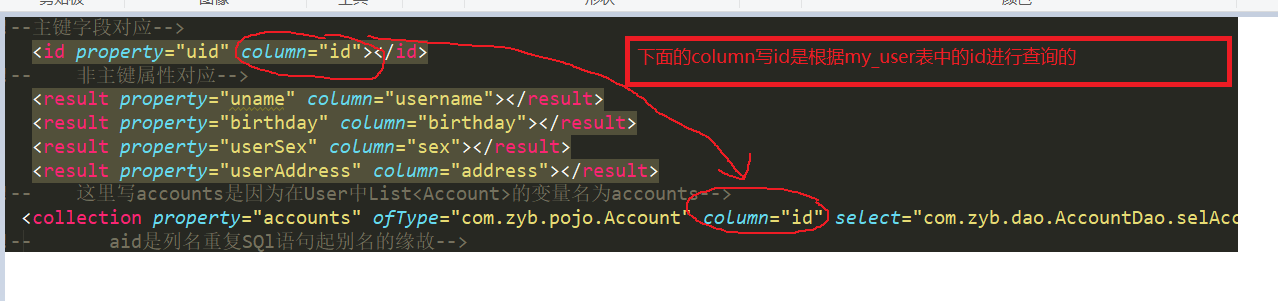

上面的配置同样可以完成只加载账户不加载用户的操作(一对一)。这里不多演示。
上面多了一个select是指向延迟加载的sql语句