转载:http://my.oschina.net/shiw019/blog/92771
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。
一、HDFS的主要设计理念
1、存储超大文件
这里的“超大文件”是指几百MB、GB甚至TB级别的文件。
2、最高效的访问模式是 一次写入、多次读取(流式数据访问)
HDFS存储的数据集作为hadoop的分析对象。在数据集生成后,长时间在此数据集上进行各种分析。每次分析都将设计该数据集的大部分数据甚至全部数据,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。
3、运行在普通廉价的服务器上
HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。
二、HDFS的忌讳
1、将HDFS用于对数据访问要求低延迟的场景
由于HDFS是为高数据吞吐量应用而设计的,必然以高延迟为代价。
2、存储大量小文件
HDFS中元数据(文件的基本信息)存储在namenode的内存中,而namenode为单点,小文件数量大到一定程度,namenode内存就吃不消了。
三、HDFS基本概念
数据块(block):大文件会被分割成多个block进行存储,block大小默认为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。
namenode:namenode负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系。
datanode:datanode就负责存储了,当然大部分容错机制都是在datanode上实现的。
四、HDFS基本架构图

图中有几个概念需要介绍一下
Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的。
五、HDFS写文件流程

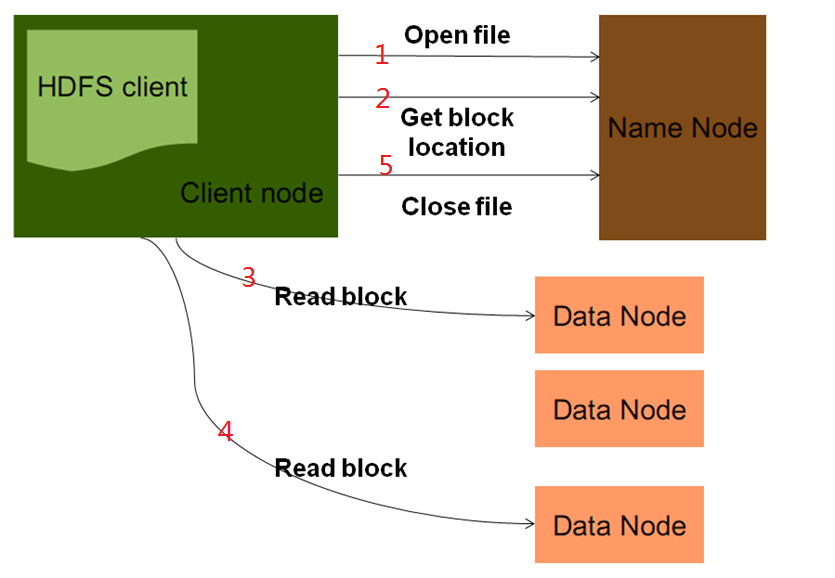
六、HDFS读文件流程