有缘人可Ctrl+F检索 或 直达底部看脑图
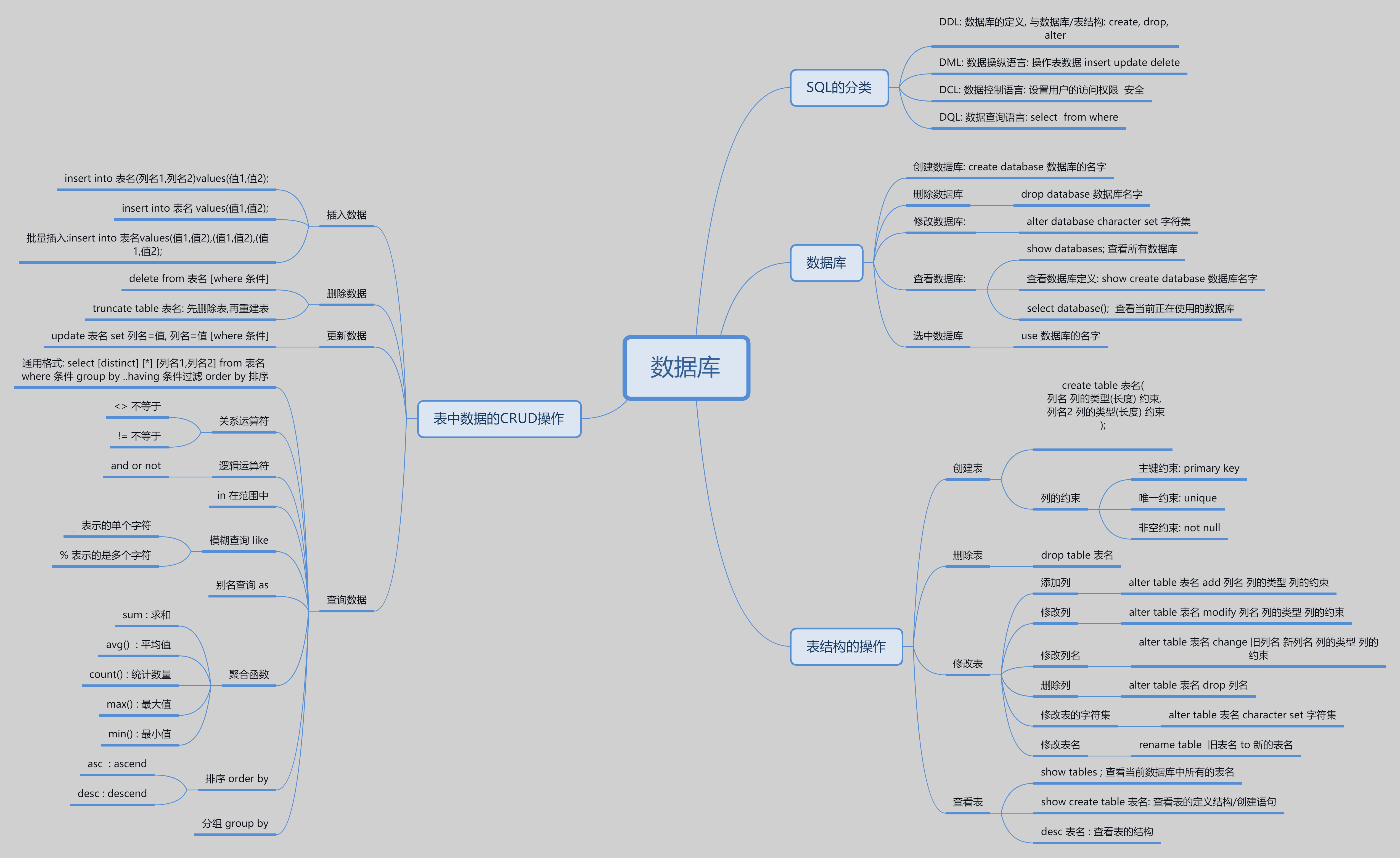
常见命令
use 数据库名 --选择数据库
desc 表名 --查看表结构
show databases --显示当前连接下所有数据库
show tables --显示当前库中所有表
show tables from 库名 --显示指定库中所有表
show columns from 表名 --显示指定表中所有列
show create table 表名 --查看表的创建语句
rename table 旧表名 to 新表名 --重命名表
MySQL_DCL_事务
概念:由一条或多条SQL语句组成,要么都执行成功,要么都失败
特性:ACID
原子性
一致性
隔离性
持久性
- 分类:
隐式事务:没有明显的开启和结束标记
如:DML语句insert、update、delete本身就是一条事务(其中一条被约束而无法操作时其他列都不会改变)
显示事务:具有明显的开启和结束标记
一般又多条SQL语句组成,必须具有明显的开启和结束标记 - 步骤:
前提:取消隐式事务的自动开启功能 --:DML语句会自动开启事务吗,在有多条DML语句时,后面的语句还未读取前面的就已经提交了,不能保证事务的特性:
* 开始事务
* 编写事务需要的SQL语句(1条或多条)
* 结束事务
补充:SHOW VARIABLES LIKE '%auto%' :查看关键变量;可用来查看记录隐式事务开关的变量值,并修改
演示事务的使用步骤:
#1.取消事务自动开启
set autocommit = 0;
#2.开启事务
start transaction
#3.编写事物的SQL语句
-- 将user1的余额-5000
update 表名 set balance=balance-5000 where 主键值
-- 将user2的余额+5000
update 表名 set balance=balance+5000 where 主键值
#4.结束事务
#提交
commit
#回滚
rollback
--注:事务执行顺利直接提交,反之执行回滚
DML (Data Manipulation Language)
数据操纵语言,可对表中的数据的增删改:insert update dalete
- 数据的插入
/*
语法:
插入单行:
insert into 表名(字段1,字段2,...) values(值1,值2,...);
插入多行:
insert into 表名(字段名1,字段名2,...) values(值1,值2,...),(值1,值2,...),(值1,值2,...);
特点:
①字段和值列表一一对应(包含类型、约束等必须匹配)
②数值型的值,不用单引号;非数值型的值必须用单引号
③字段顺序要求
*/
#案例1:要求字段和值列表一一对应,且遵循类型和约束的限制
INSERT INTO stuinfo(stuid,stuname,stugender,email,age,majorid)
VALUES(1,'熊大','女','sisi@qq.com',12,1);
#案例2:空字段如何插入
-- 方案1:字段名和值都不写
INSERT INTO stuinfo(stuid,stuname,email,majorid)
VALUES(1,'熊大','sisi@qq.com',2);
-- 方案2:字段名写上,值使用null
INSERT INTO stuinfo(stuid,stuname,email,age,majorid)
VALUES(1,'熊大','sisi@qq.com',NULL,2);
#案例3:默认字段如何插入
-- 方案1:字段名写上,值使用default
INSERT INTO stuinfo(stuid,stuname,email,stugender,majorid)
VALUES(7,'熊大','sisi@qq.com',DEFAULT,2);
-- 方案2:字段名和值都不写
INSERT INTO stuinfo(stuid,stuname,email,majorid)
VALUES(7,'熊大','sisi@qq.com',2);
#案例4:可以省略字段列表,默认对所有字段进行插入操作
INSERT INTO stuinfo VALUES(8,'熊大','女','lin@126.com',12,3);
- 数据的修改
/*
语法:
update 表名 set 字段名 = 新值,字段名 = 新值,...
where 筛选条件;
*/
#案例1:修改年龄<20的专业编号为3号,且邮箱更改为 xx@qq.com
UPDATE stuinfo SET majorid = 3,email='xx@qq.com'
WHERE age<20;
- 数据的删除
/*
语法:
方式1:delete语句 -- 删除指定筛选条件的列表项
delete from 表名 where 筛选条件;
方式2:truncate语句 -- 一次性清除所有数据
truncate table 表名;
两种方式的区别:
1.delete可以添加where条件,truncate不能添加where条件,且一次性清除所有数据
2.truncate的效率较高
3.如果删除带自增长列的表:
使用delete删除后,新插入的数据,记录从断点处开始
使用truncate删除后,新插入的数据,记录从1开始
4.delete删除数据,会返回受影响的行数
truncate删除数据,不会返回受影响的行数
5.delete删除数据,可以支持事务回滚
truncate删除数据,不可以支持事务回滚
补充:设置自增长列 auto_increment
1、自增长列要求必须设置在一个键上,比如主键或唯一键
2、自增长列要求数据类型为字符型
3、一个表至多有一个增长列
*/
#案例1:删除姓李所有信息
DELETE FROM stuinfo WHERE stuname LIKE '李%';
#案例2:删除表中所有数据
TRUNCATE TABLE stuinfo ;
DDL语言
说明:Date Define Language数据定义语言,用于对数据库和表的管理和操作
- 库的管理
#一、创建数据库
CREATE DATABASE 数据库名;
CREATE DATABASE IF NOT EXISTS 数据库名;
#删除数据库
DROP DATABASE 数据库名;
DROP DATABASE 数据库名;
- 表的管理
#一、创建表
语法:
CREATE TABLE [IF NOT EXISTS] 表名(
字段名 字段类型 [字段约束],
字段名 字段类型 [字段约束],
字段名 字段类型 [字段约束]
);
-- 案例:没有添加约束
CREATE TABLE IF NOT EXISTS table1(
table_id INT,
table_name VARCHAR(20),
birthday DATETIME
gender CHAR,
age INT,
);
-- 案例:添加约束
CREATE TABLE IF NOT EXISTS table1(
table_id INT PRIMARY KEY,-- 添加了主键约束,如需添加备注后面加: COMMENT '备注信息';后面加 auto_increment表示id自增
table_name VARCHAR(20) UNIQUE,-- 添加了唯一约束
birthday DATETIME
gender CHAR DEFAULT '男',-- 添加了默认约束
age INT CHECK(age BETWEEN 0 AND 100),-- 添加了检查约束,MySQL不支持,顾不会生效
majorid INT,
CONSTRAINT 自定义名字 FOREIGN KEY (majorid) REFERENCES 主表名(主表的主键);-- 添加了外键约束
)其他选项(如存储引擎,字符集等);
#一)数据类型:
1、整型
TINYINT SMALLINT INT BIGINT
2、浮点型
FLOAT(m,n)
DOUBLE(m,n)
DECIMAL(m,n)
m和n可选
3、字符型
CHAR(n):n可选
VARCHAR(n):n必选
TEXT
n表示最多字符个数
4、日期型
DATE TIME DATETIME TIMESTAMP
5、二进制型
BLOB 存储图片数据
#二)常见约束
说明:用于限制表中字段的数据,从而进一步保证数据表的数据是一致、精确和可靠的
NOT NULL 非空:用于限制该字段为必填项
DEFAULT 默认:用于限制该字段没有显式插入值时,直接显示的默认值
PRIMARY KEY 主键:用于限制该字段的值不能重复,设置为主键列的字段默认不能为空,一个表只能设置一个主键(可以是多个列的组合主键)
UNIQUE 唯一:用于限制该字段值不能重复
对比 字段是否可以为空 一个表可以有几个
PRIMARY KEY 否 1个
UNIQUE 是 n个
CHECK 检查:用于限制该字段值必须满足指定条件
CHECK(age BETWEEN 1 AND 10)
FOREIGN KEY 外键:用于限制两个表的关系,要求外键列的值必须来自于主表的关联列(外键位于从表)
要求:
①主表的关联列和从表的关联列的类型必须一致、意思一样;名称可以不同
②主表的关联列必须是主键
定义数据库列时,可以使用ENUM(enumeration,枚举)和SET(集合)类型:变通的实现CHECK约束
两者的区别是:
使用ENUM,只能选一个值; 如:sex enum('M','F') -表示sex只能取一个值,大小写自动转换,可以为null值,填入非选项的字符报警告不存储(指的是添加多个数据时,enum类型这一列添加不上,同时添加的其他数据可以添加上)
使用SET,可以选多个值; 如:link set('game','basketball','computer','...') -可以选择里面的多个添加
ENUM和SET中的值都必须是字符串类型
注意:
在内部存储ENUM值时,MYSQL给ENUM中的每个值一个顺序号码:第一个值的顺序号码是1,第二个值的顺序号码是2,以此类推。当排序或比较ENUM的时候,使用这些顺序号码进行。
#
语法:ALTER TABLE 表名 ADD|MODIFY|CHANGE|DROP COLUMN 字段名 字段类型 【字段约束】;
#1.修改表名
ALTER TABLE 旧表名 TO xin表名;
#2.添加字段
ALTER TABLE 表名 ADD COLUMN 新字段 TIMESTAMP NOT NULL;
DESC students;
#3.修改字段名
ALTER TABLE 表名 CHANGE [COLUMN] 原字段名 新字段名 字段类型 [字段约束];
#4.修改字段类型
ALTER TABLE 表名 MODIFY [COLUMN] 字段名 数据类型;
#5.删除字段
ALTER TABLE 表名 DROP COLUMN 字段名;
DESC 表名;-- 查看表
#三、删除表 √
DROP TABLE IF EXISTS 表名;
#四、复制表√
-- 仅仅复制表的结构
CREATE TABLE 新表名 LIKE 目标表名;
-- 复制表的结构+数据
CREATE TABLE 新表名 SELECT * FROM 目标表名.字符段;
-- -- 案例:复制employees表中的last_name,department_id,salary字段到新表 emp表,但不复制数据
CREATE TABLE emp
SELECT last_name,department_id,salary
FROM myemployees.`employees`
WHERE 1=2; -- 让判断结果不成立
#五、字段顺序(字段位置)
-- 将字段名1添加到字段名2后一列(修改类似)
ALTER TABLE 表名 ADD 字段名1 数据类型 AFTER 字段名2;
-- 将字段名添加到第一列
ALTER TABLE 表名 ADD 字段名 数据类型 FIRST
#六、查看表的字符编码(字符集)和 默认存储引擎
SHOW TABLE STATUS FROM 库名 LIKE '%表名%'; -- 要用单引号包裹
SHOW VARIABLES LIKE '%storage_engine%';
注释(备注)
#创建表的时候写注释
create table 表名(
field_name int comment '字段的注释'
)comment='表的注释';
#修改表的注释
alter table 表名 comment '修改后的表的注释';
#修改字段的注释
alter table 表名 modify column 字段名 字段类型 comment '修改后的字段注释';
--注意:字段名和字段类型照写就行
#查看表注释的方法
--在生成的SQL语句中看
show create table 表名;
#查看字段注释的方法
--show
show full columns from 表名;
函数
- 常见函数
/*
函数:类似于java中的方法
为了解决某个问题,将编写一系列的命令集合封装在一起,对外仅暴露方法名,供外部调用
1、自定义函数
2、调用函数:需要知道函数名以及函数功能
常见函数:
字符函数:
concat:拼接字符
substr:截取子串
length:获取字节长度
char_length:获取字符长度
upper:字符转换为大写
lower:字符转换为小写
trim:去除前后指定字符
left:从左开始截取子串
right:从右开始截取子串
lpad:左填充
rpad:右填充
instr:获取字符串第一次出现的索引
strcmp:比较两个字符串大小
数字函数;
abs:获取绝对值
ceil:向上取整
floor:向下取整
round:四舍五入
truncate:截断
mod:取余
日期函数:
now:当前日期和时间
curdate:当前日期
curtim:当前时间
datediff:时间差
date_format:指定日期时间格式
str_to_date:按指定格式解析为日期时间类型
流程控制函数:
if:如果
case:类似java的switch
*/
#一、字符函数
1、CONCAT 拼接字符
SELECT CONCAT(last_name,'我是拼接进来的',first_name)
FROM employees;
2、LENGTH 获取字节长度
SELECT LENGTH('abcd中国');-- 10
3、CHAR_LENGTH 获取字符个数
SELECT CHAR_LENGTH('abcd中国');-- 6
4、SUBSTRING 截取子串
/*
注意:起始索引从1开始!!!
substr(str,起始索引,截取的字符长度)
substr(str,起始索引)
*/
SELECT SUBSTR('如果我是dj你还爱我吗',9,1);-- 爱
5、INSTR获取字符第一次出现的索引
SELECT INSTR('如果我是dj你还爱我吗','爱');-- 9
6、TRIM去前后指定的字符,默认是去空格
SELECT TRIM(' 如果我是dj 你还爱我吗 ');
SELECT TRIM('x' FROM 'xx如果x我是dj你还爱我吗xx');-- 如果x我是dj你还爱我吗
7、LPAD/RPAD 左填充/右填充(按指定的长度显示字符)
SELECT LPAD('独孤九剑',10,'a');-- aaaaaa独孤九剑
SELECT RPAD('独孤九剑',1,'a');-- 独
8 、 UPPER/ LOWER转换大小写 -- 案例:查询员工表的姓名,要求格式:姓首字符大写,其他字符小写,名所有字符大写,且姓和名之间用_分割,最后起别名“OUTPUT”
SELECT
CONCAT(
UPPER(SUBSTR(first_name, 1, 1)),
LOWER(SUBSTR(first_name, 2)),'_',UPPER(last_name)
) AS "OUTPUT"
FROM
employees ;
9、STRCMP 比较两个字符大小(前面的比后面的大返回1,小返回-1)
SELECT STRCMP('aa','bb');-- -1
10、LEFT/RIGHT 截取子串,从左/右开始
SELECT LEFT('鸠摩智',1);
SELECT RIGHT('鸠摩智',1);
#二、数学函数
1、ABS 绝对值
SELECT ABS(-34.6);
2、CEIL 向上取整 返回>=该参数的最小整数
SELECT CEIL(-1.09); -- 1
3、FLOOR 向下取整,返回<=该参数的最大整数
SELECT FLOOR(-1.09); -- -2
4、ROUND 四舍五入
SELECT ROUND(1.8712345,1);-- 1.9
5、TRUNCATE 截断
SELECT TRUNCATE(1.8712345,1);-- 1.8
6、MOD 取余
SELECT MOD(-10,3);
取余公式:a%b = a-(INT)a/b*b
小技巧:被取余数是正数/负数结果也是
#三、日期函数
1、NOW -- 当前日期和时间
SELECT NOW();
2、CURDATE -- 当前日期
SELECT CURDATE();
3、CURTIME -- 当前时间
SELECT CURTIME();
4、DATEDIFF -- 计算时间差(日期错误时结果为null)
SELECT DATEDIFF('2020-03-30','2020-02-29');-- 30
5、DATE_FORMAT -- 指定日期时间格式
SELECT DATE_FORMAT('1998-01-02 15-20-10','%Y年%m月%d日 %H时%i分%s秒');-- 1998年01月02日 15时20分10秒
6、STR_TO_DATE -- 按指定格式解析字符串为日期时间类型
SELECT STR_TO_DATE('3/15 1998 10:20:20','%m/%d %Y %H:%i:%s');-- 1998-03-15 10:20:20
#四、流程控制函数
1、IF函数 -- 类似三元运算符
SELECT IF(100>9,'好','坏');
-- 案例:需求:如果有奖金,则显示最终奖金,如果没有,则显示0
SELECT IF(commission_pct IS NULL,0,12*salary*commission_pct)
FROM employees;
2、CASE函数
-- 情况1:类似于switch语句,可以实现等值判断
CASE 表达式
WHEN 值1 THEN 结果1
WHEN 值2 THEN 结果2
...
ELSE 结果n
END
-- 情况2:类似于多重IF语句,实现区间判断
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
...
ELSE 结果n
END
- 分组函数
/*
说明:分组函数往往用于实现将一组数据进行统计计算,最终得到一个值,又称为聚合函数或统计函数
分组函数清单:
sum(字段名):求和
avg(字段名):求平均值
max(字段名):求最大值
min(字段名):求最小值、
count(字段名):计算非空字段值的个数
*/
#案例1 :查询员工信息表中,所有员工的工资和、工资平均值、最低工资、最高工资、有工资的个数
SELECT SUM(salary),AVG(salary),MIN(salary),MAX(salary),COUNT(salary) FROM employees;
#案例2:添加筛选条件
-- ①查询emp表中记录数:
SELECT COUNT(employee_id) FROM employees;
-- ②查询emp表中有佣金的人数:
SELECT COUNT(salary) FROM employees;
-- ③查询emp表中月薪大于2500的人数:
SELECT COUNT(salary) FROM employees WHERE salary>2500;
#④查询有领导的人数:
SELECT COUNT(manager_id) FROM employees;
#count的补充介绍★
-- 1、统计结果集的行数,推荐使用count(*)
-- -- 方式一:检测每一行的每一列,只要有不为null的值,则返回该行
SELECT COUNT(*) FROM employees;
SELECT COUNT(*) FROM employees WHERE department_id = 30;
-- -- 方式二:在每一不为空的行前面加一列,并指定值用来判断非空(效率低)
SELECT COUNT(1) FROM employees;
SELECT COUNT(1) FROM employees WHERE department_id = 30;
-- 2、搭配distinct实现去重的统计
-- -- 需求:查询有员工的部门个数
SELECT COUNT(DISTINCT department_id) FROM employees;
查询操作
查询
- 基础查询
/*
语法:
select 查询列表 from 表名;
特点:
1、查询的结果集 是一个虚拟表
2、select 查询列表 类似于System.out.println(打印内容);
select后面跟的查询列表,可以有多个部分组成,中间用逗号隔开
例如:select 字段1,字段2,表达式 from 表;
System.out.println()的打印内容,只能有一个。
3、执行顺序
① from子句
② select子句
4、查询列表可以是:字段、表达式、常量、函数等
#一、查询常量
SELECT 100 ;
#二、查询表达式
SELECT 100%3;
#三、查询单个字段
SELECT `last_name` FROM `employees`;
#四、查询多个字段
SELECT `last_name`,`email`,`employee_id` FROM employees;
#五、查询所有字段
SELECT * FROM `employees`;
#六、查询函数(调用函数,获取返回值)
SELECT DATABASE();
#七、起别名
使用as关键字 或 直接使用空格
SELECT USER() AS 用户名;
SELECT USER() 用户名;
#八、+的作用
-- 需求:查询 first_name 和last_name拼接成的全名,最终起别名为:姓 名
-- 方案1:使用+ pass×
SELECT first_name+last_name AS "姓 名"
FROM employees;
-- 方案2:使用concat拼接函数
SELECT CONCAT(first_name,last_name) AS "姓 名"
FROM employees;
#九、distinct的使用,只去一个
-- 需求:查询员工涉及到的部门编号有哪些
SELECT DISTINCT department_id FROM employees;
#十、查看表的结构
DESC employees;
-- or
SHOW COLUMNS FROM employees;
*/
- 条件查询
/*
语法:
select 查询列表
from 表名
where 筛选条件;
执行顺序:
①from子句
②where子句
③select子句
select last_name,first_name from employees where salary>20000;
特点:
1、按关系表达式筛选
关系运算符:> < >= <= = <>
补充:也可以使用!=,但不建议
2、按逻辑表达式筛选
逻辑运算符:and or not
补充:也可以使用&& || ! ,但不建议
3、模糊查询
like:一般和通配符搭配使用,对字符型数据进行部分匹配查询
in:查询某字段的值是否属于指定的列表之内
between and:查询某字段是否在指定区间内
is null:判断值是否为空
*/
#一、按关系表达式筛选
#案例1:查询部门编号不是100的员工信息
SELECT *
FROM employees
WHERE department_id <> 100;
-- 案例2:查询工资<15000的姓名、工资
SELECT last_name,salary
FROM employees
WHERE salary<15000;
#二、按逻辑表达式筛选
-- 案例1:查询部门编号不是 50-100之间员工姓名、部门编号、邮箱
---- 方式1:
SELECT last_name,department_id,email
FROM employees
WHERE department_id <50 OR department_id>100;
---- 方式2:
SELECT last_name,department_id,email
FROM employees
WHERE NOT(department_id>=50 AND department_id<=100);
#案例2:查询奖金率>0.03 或者 员工编号在60-110之间的员工信息
SELECT *
FROM employees
WHERE commission_pct>0.03 OR (employee_id >=60 AND employee_id<=110);
#三、模糊查询
#1、like
/*
功能:一般和通配符搭配使用,对字符型数据进行部分匹配查询
常见的通配符:
_ 任意单个字符
% 任意多个字符,支持0-多个
like/not like
*/
-- 案例1:查询姓名中包含字符a的员工信息
SELECT *
FROM employees
WHERE last_name LIKE '%a%';
-- 案例2:查询姓名中包含最后一个字符为e的员工信息
SELECT *
FROM employees
WHERE last_name LIKE '%e';
-- 案例3:查询姓名中包含第一个字符为e的员工信息
SELECT *
FROM employees
WHERE last_name LIKE 'e%';
-- 案例4:查询姓名中包含第三个字符为x的员工信息
SELECT *
FROM employees
WHERE last_name LIKE '__x%';
-- 案例5:查询姓名中包含第二个字符为_的员工信息
SELECT *
FROM employees
WHERE last_name LIKE '_\_%';
SELECT *
FROM employees
WHERE last_name LIKE '_$_%' ESCAPE '$';
#2、in
/*
功能:查询某字段的值是否属于指定的列表之内
a in(常量值1,常量值2,常量值3,...)
a not in(常量值1,常量值2,常量值3,...)
in/not in
*/
-- 案例1:查询部门编号是30/50/90的员工名、部门编号
---- 方式1:
SELECT last_name,department_id
FROM employees
WHERE department_id IN(30,50,90);
---- 方式2:
SELECT last_name,department_id
FROM employees
WHERE department_id = 30
OR department_id = 50
OR department_id = 90;
-- 案例2:查询工种编号不是SH_CLERK或IT_PROG的员工信息
---- 方式1:
SELECT *
FROM employees
WHERE job_id NOT IN('SH_CLERK','IT_PROG');
---- 方式2:
SELECT *
FROM employees
WHERE NOT(job_id ='SH_CLERK'
OR job_id = 'IT_PROG');
#3、between and
/*
功能:判断某个字段的值是否介于xx之间
between and/not between and
*/
-- 案例1:查询部门编号是30-90之间的部门编号、员工姓名
---- 方式1:
SELECT department_id,last_name
FROM employees
WHERE department_id BETWEEN 30 AND 90;
---- 方式2:
SELECT department_id,last_name
FROM employees
WHERE department_id>=30 AND department_id<=90;
-- 案例2:查询年薪不是100000-200000之间的员工姓名、工资、年薪
SELECT last_name,salary,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
WHERE salary*12*(1+IFNULL(commission_pct,0))<100000 OR salary*12*(1+IFNULL(commission_pct,0))>200000;
SELECT last_name,salary,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
WHERE salary*12*(1+IFNULL(commission_pct,0)) NOT BETWEEN 100000 AND 200000;
#4、is null/is not null
-- 案例1:查询没有奖金的员工信息
SELECT *
FROM employees
WHERE commission_pct IS NULL;
-- 案例2:查询有奖金的员工信息
SELECT *
FROM employees
WHERE commission_pct IS NOT NULL;
SELECT *
FROM employees
WHERE salary IS 10000;
#-------------------------对比---------------------------
= 只能判断普通的内容
IS 只能判断NULL值
<=> 安全等于,既能判断普通内容,又能判断NULL值
- 排序查询
/*
语法:
select 查询列表
from 表名
【where 筛选条件】
order by 排序列表
执行顺序:
①from子句
②where子句
③select子句
④order by 子句
举例:
select last_name,salary
from employees
where salary>20000
order by salary ;
select * from employees;
特点:
1、排序列表可以是单个字段、多个字段、表达式、函数、列数、以及以上的组合
2、升序 ,通过 asc ,默认行为
降序 ,通过 desc
*/
#一、按单个字段排序
-- 案例1:将员工编号>120的员工信息进行工资的升序
SELECT *
FROM employees
ORDER BY salary ;
-- 案例2:将员工编号>120的员工信息进行工资的降序
SELECT *
FROM employees
WHERE employee_id>120
ORDER BY salary DESC;
#二、按表达式排序
-- 案例:对有奖金的员工,按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
#三、按别名排序
-- 案例:对有奖金的员工,按年薪降序
SELECT *,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
ORDER BY 年薪 DESC;
#四、按函数的结果排序
-- 案例:按姓名的字数长度进行升序
SELECT last_name
FROM employees
ORDER BY LENGTH(last_name);
#五、按多个字段排序
-- 案例:查询员工的姓名、工资、部门编号,先按工资升序,再按部门编号降序
SELECT last_name,salary,department_id
FROM employees
ORDER BY salary ASC,department_id DESC;
#六、补充:按列数排序
SELECT * FROM employees
ORDER BY 2 DESC;
SELECT * FROM employees
ORDER BY first_name;
分组查询
/*
语法:
select 查询列表
from 表名
where 筛选条件
group by 分组列表
having 分组后筛选
order by 排序列表
执行顺序:
①from子句
②where子句
③group by子句
④having子句
⑤select子句
⑥order by子句
特点:
①查询列表往往是分组字段和被分组字段
②分组查询中的筛选分为两类:
筛选的基表 使用关键字 位置
分组前筛选 原始表 where group by的前面
分组后的筛选 分组后的结果集 having group by的后面
where——group by——having
③分组函数做条件时,只能放在having后面
技巧:填空式
先按语法格式列出SQL语句
先将要求结果的列名直接先放到SELECT后;
"每个xx",说的就是分组项,直接放到GROUP BY 后(一般也会放大SELECT后显示出来)
再来根据限制条件看是基于原始表还是分组后的结果集,把限制条件写到 WHERE 或 HAVING 后;
*/
#1)简单的分组
-- 案例1:查询每个工种的员工平均工资
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id;
-- 案例2:查询每个领导的手下人数
SELECT COUNT(*),manager_id
FROM employees
WHERE manager_id IS NOT NULL
GROUP BY manager_id;
#2)可以实现分组前的筛选
-- 案例1:查询邮箱中包含a字符的 每个部门的最高工资
SELECT MAX(salary) 最高工资,department_id
FROM employees
WHERE email LIKE '%a%'
GROUP BY department_id;
-- 案例2:查询每个领导手下有奖金的员工的平均工资
SELECT AVG(salary) 平均工资,manager_id
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY manager_id;
#3)可以实现分组后的筛选
-- 案例1:查询哪个部门的员工个数>5
-- -- 分析1:查询每个部门的员工个数
SELECT COUNT(*) 员工个数,department_id
FROM employees
GROUP BY department_id
-- -- 分析2:在刚才的结果基础上,筛选哪个部门的员工个数>5
SELECT COUNT(*) 员工个数,department_id
FROM employees
GROUP BY department_id
HAVING COUNT(*)>5;
-- 案例2:每个工种有奖金的员工的最高工资>12000的工种编号和最高工资
SELECT job_id,MAX(salary)
FROM employees
WHERE commission_pct IS NOT NULL
GROUP BY job_id
HAVING MAX(salary)>12000;
-- 案例3:领导编号>102的 每个领导手下的最低工资大于5000的最低工资
-- -- 分析1:查询每个领导手下员工的最低工资
SELECT MIN(salary) 最低工资,manager_id
FROM employees
GROUP BY manager_id;
-- -- 分析2:筛选刚才1的结果
SELECT MIN(salary) 最低工资,manager_id
FROM employees
WHERE manager_id>102
GROUP BY manager_id
HAVING MIN(salary)>5000 ;
#4)可以实现排序
-- 案例:查询没有奖金的员工的最高工资>6000的工种编号和最高工资,按最高工资升序
-- -- 分析1:按工种分组,查询每个工种有奖金的员工的最高工资
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
-- -- 分析2:筛选刚才的结果,看哪个最高工资>6000
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
HAVING MAX(salary)>6000
-- -- 分析3:按最高工资升序
SELECT MAX(salary) 最高工资,job_id
FROM employees
WHERE commission_pct IS NULL
GROUP BY job_id
HAVING MAX(salary)>6000
ORDER BY MAX(salary) ASC;
#5)按多个字段分组
#案例:查询每个工种每个部门的最低工资,并按最低工资降序
#提示:工种和部门都一样,才是一组
工种 部门 工资
1 10 10000
1 20 2000
2 20
3 20
1 10
SELECT MIN(salary),job_id,department_id
FROM employees
GROUP BY job_id,department_id
ORDER BY MIN(salary) DESC;
连接查询(多表查询)
/*
说明:又称多表查询,当查询语句涉及到的字段来自于多个表时,就会用到连接查询
笛卡尔乘积现象:表1 有m行,表2有n行,结果=m*n行
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
分类:
按年代分类:
1、sql92标准:仅仅支持内连接
内连接:
等值连接
非等值连接
自连接
2、sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按功能分类:
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接
右外连接
全外连接
交叉连接
*/
#---------------------------------sql92标准------------------
#一、内连接
/*
语法:
select 查询列表
from 表1 别名,表2 别名
where 连接条件
and 筛选条件
group by 分组列表
having 分组后筛选
order by 排序列表
执行顺序:
1、from子句
2、where子句
3、and子句
4、group by子句
5、having子句
6、select子句
7、order by子句
*/
#-------------------------SQL99标准--------------------------
-- 下面操作均用SQL标准
#一、内连接
/*
语法:
select 查询列表
from 表名1 别名
[inner]join 表名2 别名
on 连接条件
where 筛选条件
group by 分组列表
having 分组后筛选
order by 排序列表
SQL92和99的区别:
使用join关键字代替了原来的逗号,并将连接条件和筛选调条件进行了分离,提高阅读性
*/
#一)等值连接
-- ①简单连接
-- -- 案例:查询员工名和部门名
SELECT last_name,department_name
FROM departments d
JOIN employees e
ON e.department_id =d.department_id;
-- ②添加筛选条件
-- -- 案例1:查询部门编号>100的部门名和所在的城市名
SELECT department_name,city
FROM departments d
JOIN locations l
ON d.`location_id` = l.`location_id`
WHERE d.`department_id`>100;
-- ③添加分组+筛选
-- -- 案例1:查询每个城市的部门个数
SELECT COUNT(*) 部门个数,l.`city`
FROM departments d
JOIN locations l
ON d.`location_id`=l.`location_id`
GROUP BY l.`city`;
-- ④添加分组+筛选+排序
-- -- 案例1:查询部门中员工个数>10的部门名,并按员工个数降序
SELECT COUNT(*) 员工个数,d.department_name
FROM employees e
JOIN departments d
ON e.`department_id`=d.`department_id`
GROUP BY d.`department_id`
HAVING 员工个数>10
ORDER BY 员工个数 DESC;
#二)非等值连接
-- 案例:查询部门编号在10-90之间的员工的工资级别,并按级别进行分组
SELECT * FROM sal_grade;
SELECT COUNT(*) 个数,grade
FROM employees e
JOIN sal_grade g
ON e.`salary` BETWEEN g.`min_salary` AND g.`max_salary`
WHERE e.`department_id` BETWEEN 10 AND 90
GROUP BY g.grade;
#三)自连接
-- 案例:查询员工名和对应的领导名
SELECT e.`last_name`,m.`last_name`
FROM employees e
JOIN employees m
ON e.`manager_id`=m.`employee_id`;
#二、外连接
/*
说明:查询结果为主表中所有的记录,如果从表有匹配项,则显示匹配项;如果从表没有匹配项,则显示null
应用场景:一般用于查询主表中有但从表没有的记录
特点:
1、外连接分主从表,两表的顺序不能任意调换
2、左连接的话,left join左边为主表
右连接的话,right join右边为主表
语法:
select 查询列表
from 表1 别名
left|right|full 【outer】 join 表2 别名
on 连接条件
where 筛选条件;
*/
-- 案例1:查询所有女神记录,以及对应的男神名,如果没有对应的男神,则显示为null
-- -- 左连接
SELECT b.*,bo.*
FROM beauty b
LEFT JOIN boys bo ON b.`boyfriend_id` = bo.`id`;
-- -- 右连接
SELECT b.*,bo.*
FROM boys bo
RIGHT JOIN beauty b ON b.`boyfriend_id` = bo.`id`;
-- 案例2:查哪个女神没有男朋友
-- -- 左连接
SELECT b.`name`
FROM beauty b
LEFT JOIN boys bo ON b.`boyfriend_id` = bo.`id`
WHERE bo.`id` IS NULL;
-- -- 右连接
SELECT b.*,bo.*
FROM boys bo
RIGHT JOIN beauty b ON b.`boyfriend_id` = bo.`id`
WHERE bo.`id` IS NULL;
-- 案例3:查询哪个部门没有员工,并显示其部门编号和部门名
SELECT COUNT(*) 部门个数
FROM departments d
LEFT JOIN employees e ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
子查询
/*
说明:当一个查询语句中又嵌套了另一个完整的select语句,则被嵌套的select语句称为子查询或内查询,
外面的select语句称为主查询或外查询
分类:
按主查询出现的位置:
1、select后面
要求:子查询的结果为单行单列(标量子查询)
2、from后面
要求:子查询的结果可以为多行多列
3、where或having
要求:子查询的结果必须为单列
单行子查询
多行子查询
4、exists后面
要求:子查询结果必须为单列(相关子查询)
特点:
1、子查询放在条件中时,必须放在条件右侧
2、子查询一般放在小括号中
3、子查询的执行优先于主查询
4、单行子查询对应了单行操作符:> < >= <= <>
5、多行子查询对应了多行操作符:any/some all in
*/
#一、放在where或having后面
#一)单行子查询
-- 案例1:谁的工资比 Abel 高?
-- -- ①查询Abel的工资
SELECT salary
FROM employees
WHERE last_name = 'Abel'
-- -- ②查询salary>①的员工信息
SELECT last_name,salary
FROM employees
WHERE salary>(
SELECT salary
FROM employees
WHERE last_name <> 'Abel'
);
-- 案例2:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id 和工资
-- -- ①查询141号员工的job_id
SELECT job_id
FROM employees
WHERE employee_id = 141
-- -- ②查询143号员工的salary
SELECT salary
FROM employees
WHERE employee_id = 143
-- -- ③查询job_id=① and salary>②的信息
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE employee_id = 141
) AND salary>(
SELECT salary
FROM employees
WHERE employee_id = 143
);
-- 案例3:返回公司工资最少的员工的last_name,job_id和salary
-- -- ①查询最低工资
SELECT MIN(salary)
FROM employees
-- -- ②查询salary=①的员工的last_name,job_id和salary
SELECT last_name,job_id,salary
FROM employees
WHERE salary=(
SELECT MIN(salary)
FROM employees
);
-- 案例4:查询最低工资大于50号部门最低工资的部门id和其最低工资
-- -- ①查询50号部门的最低工资
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
-- -- ②查询各部门的最低工资,筛选看哪个部门的最低工资>①
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
HAVING MIN(salary)>(
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
);
#二)多行子查询
/*
in:判断某字段是否在指定列表内
x in(10,20,50)
any/some:判断某字段的值是否满足其中任意一项
x=any(10,20,50) -> x in(10,20,50)
x>any(10,20,50) -> x > min()
all:判断某字段是否满足其中所有的项
x>all(10,30,50)
x>max()
*/
-- 案例1:返回location_id是1400或1700的部门中的所有员工姓名
-- -- ①查询location_id是1400或1700的部门
SELECT department_id
FROM departments
WHERE location_id IN(1400,1700)
-- -- ②查询department_id = ①的姓名
SELECT last_name
FROM employees
WHERE department_id IN(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
);
-- 题目:返回其它部门中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
-- -- ①查询job_id为‘IT_PROG’部门的工资
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
-- -- ②查询其他部门的工资<任意一个①的结果
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
等价于
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<(
SELECT MAX(salary)
FROM employees
WHERE job_id = 'IT_PROG'
);
-- 案例3:返回其它部门中比job_id为‘IT_PROG’部门所有工资都低的员工 的员工号、姓名、job_id 以及salary
-- -- ①查询job_id为‘IT_PROG’部门的工资
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
-- -- ②查询其他部门的工资<所有①的结果
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<ALL(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
);
等价于
SELECT employee_id,last_name,job_id,salary
FROM employees
WHERE salary<(
SELECT MIN(salary)
FROM employees
WHERE job_id = 'IT_PROG'
);
#二、放在select后面
-- 案例;查询部门编号是50的员工个数
SELECT
(
SELECT COUNT(*)
FROM employees
WHERE department_id = 50
) 个数;
#三、放在from后面
-- 案例:查询每个部门的平均工资的工资级别
-- -- ①查询每个部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
-- -- ②将①和sal_grade两表连接查询
SELECT dep_ag.department_id,dep_ag.ag,g.grade
FROM sal_grade g
JOIN (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) dep_ag ON dep_ag.ag BETWEEN g.min_salary AND g.max_salary;
#四、放在exists后面
-- 案例1 :查询有无名字叫“张三丰”的员工信息
SELECT EXISTS(
SELECT *
FROM employees
WHERE last_name = 'Abel'
) 有无Abel;
-- 案例2:查询没有女朋友的男神信息
SELECT bo.*
FROM boys bo
WHERE bo.`id` NOT IN(
SELECT boyfriend_id
FROM beauty b
)
SELECT bo.*
FROM boys bo
WHERE NOT EXISTS(
SELECT boyfriend_id
FROM beauty b
WHERE bo.id = b.boyfriend_id
);
分页查询
/*
应用场景:当页面上的数据,一页显示不全,则需要分页显示
分页查询的SQL命令请求数据库服务器——>服务器响应查询到的多条数据——>前台页面
语法:
select 查询列表
from 表1 别名
join 表2 别名
on 条件连接
where 筛选条件
group by 分组条件
having 分组后筛选
order by 排序列表
limit 起始索引条目,显示的条目数
执行顺序:
①from子句
②join子句
③on子句
④where子句
⑤group by子句
⑥having子句
⑦select子句
⑧order by子句
⑨limit子句
特点:
1、起始条目如果不写,默认是0
2、limit后面支持两个参数
参数1:要显示的条目起始索引
参数2:要显示的条目数量
公式:
假设要显示的页数索引为page,每页显示条目数为size
select*
from employees
limit (page-1)*size,size;
*/
-- 案例1:查询员工信息表的前5条
SELECT *
FROM employees
LIMIT 5;
-- 案例2:查询有奖金且工资较高的第11名到20名员工信息
SELECT *
FROM employees
WHERE commission_pct IS NOT NULL
ORDER BY commission_pct DESC
LIMIT 10,10;
-- 案例3:查询年薪最高的前10名
SELECT last_name,salary,salary*12*(1+IFNULL(commission_pct,0)) 年薪
FROM employees
ORDER BY 年薪 DESC
LIMIT 0,10;
- 联合查询
/*
说明:当查询结果来自于多张表,但多张表之间没有关联,可使用联合查询(union查询)
语法:
select 查询列表 from 表1 where 筛选条件
union
select 查询列表 from 表2 where 筛选条件
特点:
1、多条查询的联合语句列数必须一致,查询类型、字段意义最好也一致
2、union实现去重查询
union all 实现全部查询,包含重复项
*/
-- 案例:查询所有国家的年龄>20岁的用户信息
SELECT * FROM usa WHERE uage >20 UNION
SELECT * FROM chinese WHERE age >20 ;
-- 案例2:查询所有国家的用户姓名和年龄
SELECT uname,uage FROM usa
UNION
SELECT age,`name` FROM chinese;
-- 案例3:union自动去重/union all 可以支持重复项
SELECT 1,'范冰冰'
UNION ALL
SELECT 1,'范冰冰'
补充
left(str,len) 从左边截取指定位数的字符串
group_concat(字段名) 将集合中的字符串连接起来