到2020年,人们每天都能从人工智能中受益:音乐推荐系统、谷歌地图、Uber以及更多的应用程序都使用人工智能。然而,人工智能、机器学习和深度学习这三个术语之间的混淆仍然存在。一个常见的谷歌搜索请求如下:“人工智能和机器学习是一回事吗?”.
让我们弄清楚:人工智能(AI)、机器学习(ML)和深度学习(DL)是三个不同的东西。
- 人工智能是一门像数学或生物学一样的科学。它研究如何建立智能程序和机器来创造性地解决问题,这一直被认为是人类独有的。
- 机器学习是人工智能(AI)的一个子集,它使系统能够自动学习并从经验中进行改进,而无需进行明确的编程。 在ML中,有多种有助于解决问题的算法(例如神经网络)。
- 深度学习或深度神经学习是机器学习的一个子集,它使用神经网络来分析结构类似于人类神经系统的不同因素。
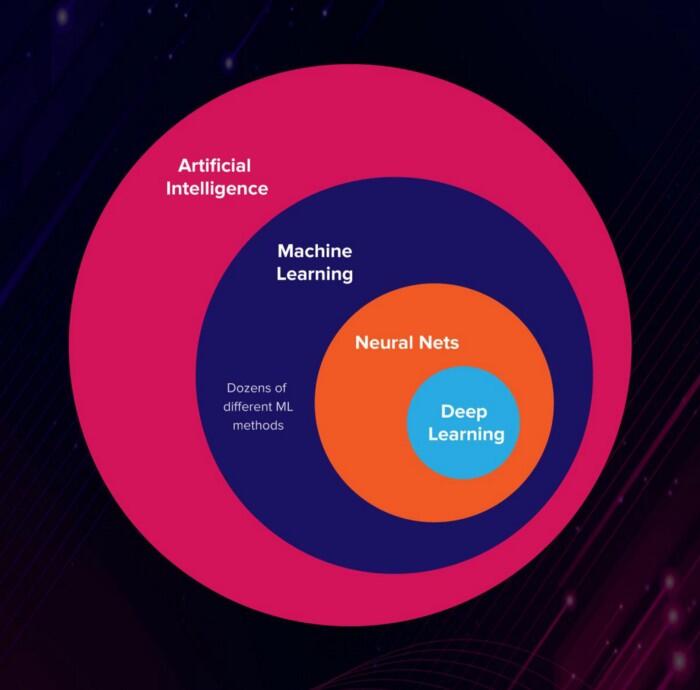
人工智能的3个方面
人工智能这个词最早出现在1956年达特茅斯的一次计算机科学会议上。人工智能描述了一种试图模拟人脑如何工作的尝试,并基于这些知识,创造出更先进的计算机。科学家们希望了解人类大脑的工作原理并将其数字化不需要太长时间。毕竟,这次会议汇集了当时最聪明的人,进行了为期2个月的集思广益。
虽然,研究人员在达特茅斯的那个夏天玩得很开心,但结果有点糟糕。结果表明了用编程的方法来模拟大脑的作法是复杂的。
尽管如此,还是取得了一些成果。例如,研究人员了解到智能机器的关键因素是学习(与不断变化和自发的环境进行交互)、自然语言处理(用于人机交互)和创造力(将人类从许多麻烦中解放出来?)。
即使在人工智能无处不在的今天,计算机仍然远远没有将人类智能完美的表现出来。
人工智能一般分为三类:

狭义/弱AI
要了解什么是弱人工智能,最好将其与强人工智能进行对比。这两个版本的人工智能正试图实现不同的目标。
“强”的人工智能寻求创造人造人:拥有我们所有精神力量的机器,包括现象意识。另一方面,“弱”的人工智能寻求建立信息处理机器,似乎拥有人类的全部智力储备(Searle 1997)
弱或狭义的人工智能擅长于执行特定的任务,但它不会在超出其定义能力的任何其他领域被人类所接受。
你可能听说过深蓝,第一台在国际象棋中打败人类的电脑。不仅仅是任何人——加里·卡斯帕罗夫(1997年)。深蓝每秒可以生成和计算大约2亿个象棋位置。老实说,有些人还没有准备好将其全称为人工智能,而另一些人则声称它是弱小人工智能最早的例子之一。
另一个著名的人工智能在游戏中击败人类的例子是AlphaGo。这个程序赢得了有史以来最复杂的游戏之一,学习如何玩它,而不仅仅是计算所有可能的移动(这是不可能的)。

目前,狭义人工智能广泛应用于科学、商业和医疗领域。例如,2017年,一家名为DOMO的公司宣布推出Roboto。这个人工智能软件系统包含强大的分析工具,可以为企业主提供商业发展的建议和见解。它可以检测异常情况和斑点模式,对风险管理和足智多谋的计划是有用的。其他行业也有类似的项目,像谷歌和亚马逊这样的大公司也在他们的开发上投资。
一般/强人工智能
这是未来机器变得像人一样的时候。他们自己做决定和学习,没有任何人类的投入。他们不仅有能力解决逻辑问题,而且有情感。
问题是:如何建造一个活的机器?你可以对机器进行编程,使其对刺激产生一些情绪化的言语反应。聊天机器人和虚拟助理已经非常擅长进行保持对话。此外,教机器人阅读人类情感的实验已经开始实施。但是,复制情感反应并不能使机器真正的情绪化,是吗?
超级智能
这是每个人在阅读人工智能时通常期望的内容。机器,远远领先于人类。聪明,聪明,有创造力,有良好的社交能力。它的目标要么是让人类的生活变得更好,要么就是毁灭他们。
令人失望的是:今天的科学家们甚至没有梦想创造出像两百周年纪念者那样的自主情感机器。
数据科学家目前正在关注的任务(有助于创建通用智能和超级智能):
- 机器推理。MR系统有一些可供使用的信息,例如数据库或图书馆。使用演绎和归纳技术,他们可以根据这些信息形成一些有价值的见解。它可以包括人工智能系统的规划、数据表示、搜索和优化;
- 机器人技术。这个科学领域专注于制造、开发和控制从roombas到智能机器人的机器人;
- 机器学习是研究机器用来执行给定任务的算法和计算机模型。
你可以称之为创造人工智能的方法。可以在一个系统中只使用一个或将所有这些功能组合在一起。现在,让我们更深入地了解细节。
机器如何学习?
sujitpal和Antonio Gulli在Keras的深度学习中指出,机器学习是人工智能(AI)更大领域的一个子集,该领域“专注于教计算机如何学习,而无需为特定任务编程”。“事实上,ML背后的关键思想是可以创建从数据中学习并对数据进行预测的算法。”
为了“教”机器,您需要以下三个部分:

数据集 机器学习系统是在称为数据集的特殊样本集合上训练的。样本可以包括数字、图像、文本或任何其他类型的数据。创建一个好的数据集通常需要花费大量的时间和精力。在这里了解有关机器学习的数据准备的更多信息。
特征 功能是重要的数据块,是解决任务的关键。他们向机器演示该注意什么。如何选择功能?比方说,你想预测一套公寓的价格。例如,根据长度和宽度的组合,很难用线性回归来预测这个地方的成本。然而,要找到价格与建筑所在区域之间的相关性要容易得多。
注:在有监督学习的情况下(我们将在后面讨论有监督的和无监督的ML),当你有带标签的数据的训练数据,其中包含“正确的解决方案”和一个验证集时,它的工作原理与上面一样。在学习过程中,程序学习如何获得“正确”的解决方案。然后,使用验证集来调整超参数,以避免过拟合。然而,在无监督学习中,特征是用未标记的输入数据来学习的。你不告诉机器在哪里看,它学会了注意自己的模式。
算法 使用不同的算法可以解决同一个任务。根据算法的不同,获得结果的精度或速度可能不同。有时为了获得更好的性能,你结合了不同的算法,比如集成学习。

任何使用ML的软件在执行特定任务时都比手动编码的指令更独立。系统学习识别模式并做出有价值的预测。如果数据集的质量很高,并且特征选择正确,那么基于ML的系统在给定的任务上可以比人类更好。
深度学习
深度学习是一类受人脑结构启发的机器学习算法。深度学习算法使用复杂的多层神经网络,通过输入数据的非线性变换,抽象程度逐渐提高。

在神经网络中,信息通过连接的通道从一层传递到另一层。每个通道都有一个加权值。
所有的神经元都有一个独特的数字叫做偏差。这个偏差加上到达神经元的输入加权和,然后应用于激活函数。函数的结果决定了神经元是否被激活。每一个被激活的神经元都会将信息传递到下面的层。这一直持续到最后第二层。人工神经网络中的输出层是产生程序输出的最后一层。
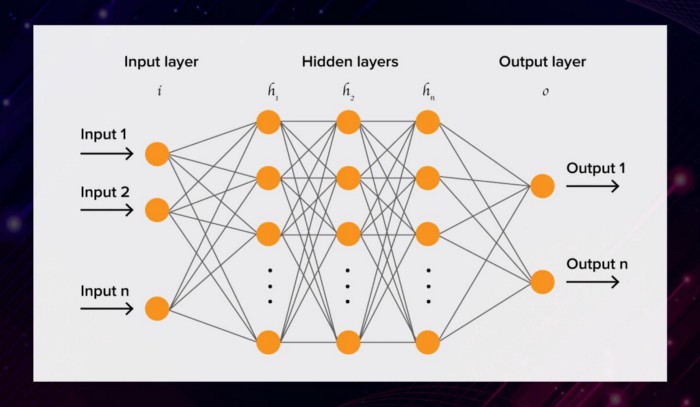
请观看此视频以更详细地了解该过程:
为了训练大量的数据,科学家需要训练大量的神经网络。这是因为为了使解精确,必须考虑大量的参数。
深度学习算法现在很火热,然而,实际上在深度deep和不太深not so deep的算法之间没有明确的界限。但是,如果您想对这个主题有更深入的了解,请查看此链接。
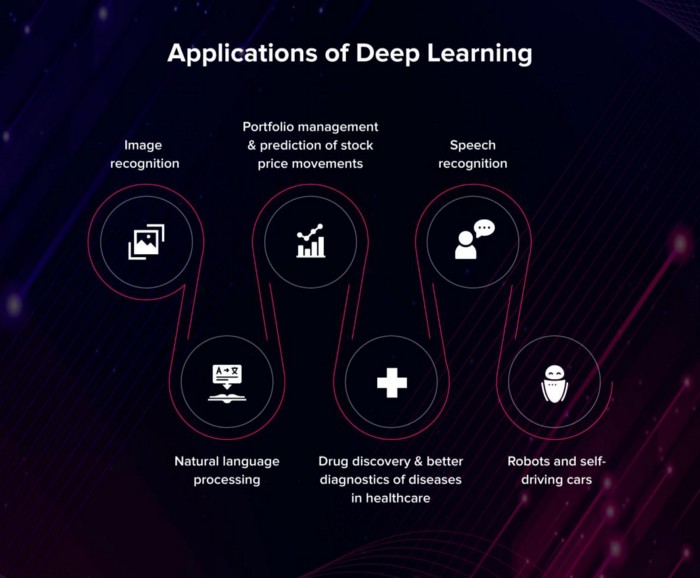
DL的一些实际应用是语音识别系统,例如googleassistant和Amazon Alexa。扬声器的声波可以用频谱图表示,它是不同频率的时间快照。一个能够记忆序列输入(例如LSTM,long-short-term memory的缩写)的神经网络可以识别和处理这种时空输入信号序列。它学会将光谱图输入映射到单词。你可以在这里找到更多的例子。
当人们听到“人工智能”这个词的时候,DL真的很接近人们的想象。计算机可以自己学习,这有多可怕?!好吧,事实是DP算法并不是完美无缺的。但是程序员喜欢DL,因为它可以应用于各种任务。然而,我们现在要讨论的还有其他的ML方法。
没有免费午餐,为什么有这么多的ML算法
在我们开始之前:有几种方法可以对算法进行分类,您可以自由选择您最喜欢的方法。
在人工智能科学中,有一个定理叫做没有免费午餐。它说,没有一种完美的算法能同样适用于所有任务:从自然语音识别到在环境中生存。因此,需要各种工具。
算法可以根据其学习风格或相似性进行分组。在这篇文章中,您将看到基于学习风格的算法分组,因为这对于第一次学习的人来说更直观。你会在这里找到一个基于相似性的分类。
四组ML算法
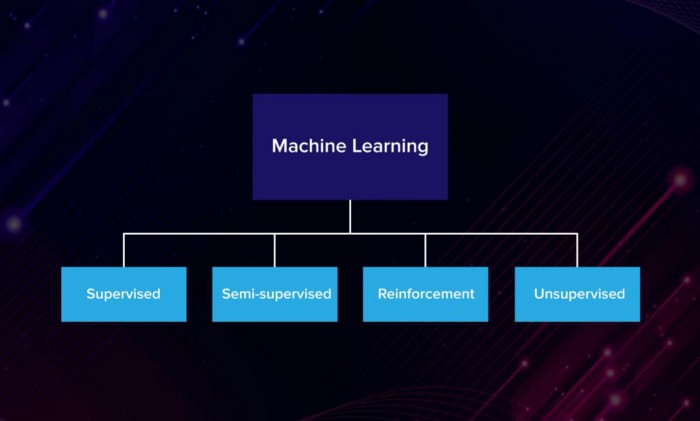
因此,根据学习方式,机器学习算法通常分为4组:
监督学习
“监督”是指教师在整个培训过程中帮助项目:有一个带有标记数据的培训集。例如,你想教电脑把红、蓝、绿袜子放在不同的篮子里。
首先,向系统显示每个对象,并说明什么是对象。然后,在验证集上运行该程序,该验证集检查所学函数是否正确。程序做出断言,当这些结论是错误的时,程序员会更正这些断言。训练过程将继续进行,直到模型在训练数据上达到所需的精度水平。这种类型的学习通常用于分类和回归。
算法示例:
- Naive Bayes,
- 支持向量机 (Support Vector Machine),
- 决策树(Decision Tree),
- K-Nearest Neighbours,
- 逻辑回归(Logistic Regression),
- 线性和多项式回归(Linear and Polynomial regressions)。
用于:垃圾邮件过滤,语言检测,计算机视觉,搜索和分类。
无监督学习
在无监督学习中,你不能为程序提供任何允许它独立搜索模式的功能。想象一下,你有一大筐衣服,电脑必须把它们分成不同的类别:袜子、T恤衫、牛仔裤。这称为聚类,无监督学习通常用于根据相似性将数据分组。
无监督学习也有助于深入的数据分析。有时程序可以识别出人类由于无法处理大量数值数据而错过的模式。例如,UL可用于发现欺诈交易、预测销售额和折扣或根据客户的搜索历史分析客户的偏好。程序员不知道他们想找到什么,但肯定有一些模式,系统可以检测到它们。
算法示例:
- K-means clustering,
- DBSCAN,
- Mean-Shift,
- Singular Value Decomposition (SVD),
- Principal Component Analysis (PCA),
- Latent Dirichlet allocation (LDA),
- Latent Semantic Analysis, FP-growth.
用于:数据分割,异常检测,推荐系统,风险管理,假图像分析。
半监督学习
正如你可以从标题中判断的,半监督学习意味着输入数据是有标记和无标记样本的混合。
程序员已经想到了一个期望的预测结果,但是模型必须找到结构数据的模式并自己进行预测。
强化学习
这与人类的学习方式非常相似:通过试验。人类不需要不断的监督才能像有监督的学习一样有效地学习。通过只接收积极或消极的强化信号来回应我们的行为,我们仍然可以非常有效地学习。例如,孩子在感到疼痛后学会了不碰热锅。
强化学习最令人兴奋的部分之一是,它允许您远离静态数据集的培训。相反,计算机能够在动态、嘈杂的环境中学习,例如游戏世界或真实世界。
游戏对于强化学习研究非常有用,因为它们提供了理想的数据丰富的环境。游戏中的分数是训练奖励动机行为的理想奖励信号,例如马里奥。
算法示例:
用于:自动驾驶汽车,游戏,机器人,资源管理。
总结
人工智能有许多伟大的应用,正在改变技术世界。虽然创造一个和人类一样智能的人工智能系统仍然是一个梦想,但ML已经允许计算机在计算、模式识别和异常检测方面胜过我们。如果你想阅读更多关于ML算法、DL方法和AI趋势的资料,请查看原作者的博客。
原文请看链接
众多好文请参考原作者-博客!··-
https://serokell.io/blog/best-machine-learning-datasets
https://medium.com/ai-in-plain-english
https://serokell.io/blog/ai-ml-dl-difference