一、什么是爬虫?
答:请求网页并提取数据的自动化程序。
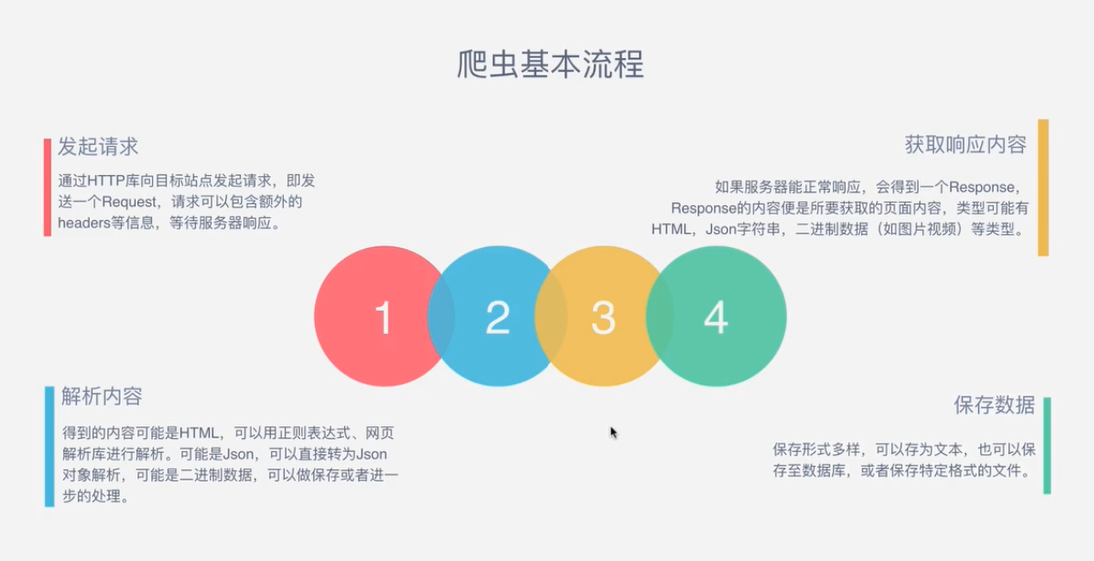
二、爬虫的基本流程
三、什么是Request和Response?

1、Request

2、Response

四、能抓取怎样的数据

五、解析方式

六、怎么解决JavaScript渲染的问题?

七、怎么保存数据?

测试代码:
import requests
response = requests.get('http://www.baidu.com')
print(response.text)
print(response.headers)
print(response.status_code)
headers = {'User-Agent':' Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Mobile Safari/537.36}
response = requests.get('http://www.baidu.com',headers=headers)
print(response.status_code)
response = requests.get('https://gss0.bdstatic.com/5bd1bjqh_Q23odCf/static/newtab/img/fetch_ing_8_0.png')
print(response.content)
with open('/var/tmp/1.png','wb') //写到本地的文件
fwrite(response.content)
f.close()