一、什么是Urllib?
官方学习文档:https://docs.python.org/3/library/urllib.html
Python内置的HTTP请求库
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
二、相比Python2的变化
Pyhton2
import urllib2
response = urllib2.urlopen('http://www.baidu.com')
Python3
import urllib.request
response = urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
三、用法讲解
urlopen
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response.read().decode('utf-8'))
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word':'hello'}),encoding='utf8')
response = urllib.request.urlopen('http://httpbin.org/post',data=data)
print(response.read)
import urllib.request
response = urllib.request.urlopen('http://httpbin.org/get',timeout=1)
print(response.read)
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://httpbin.org/get',timeout=0.1)
except urllib.error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('TIME OUT')
响应
响应类型
import urllib.request
response = urllib.request.urlopen('http://www.python.org')
print(type(response))
状态码、响应头
import urllib.request
response = urllib.request.urlopen('https://www.python.org')
print(response.status)
print(response.getheaders())
print(response.getheader('Server'))
print(response.read().decode('utf-8'))
Request
import urllib.request
request = urllib.request.Request('https://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
from urllib import request,parse
url = 'http://httpbin.org/post'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
dict = {
'name':'jack'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url,data=data,headers=headers,method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
from urllib import request,parse
url = 'http://httpbin.org/post'
dict = {
'name':'jack'
}
data = bytes(parse.urlencode(dict),encoding='utf8')
req = request.Request(url=url,data=data,method='POST')
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
req.add_header( 'User-Agent', user_agent)
response = request.urlopen(req)
print(response.read().decode('utf-8'))
handler
代理
import urllib.request
proxy_handler = urllib.request.ProxyHandler({
'http':'http://127.0.0.1.9743',
'https':'https://127.0.0.1.9743'
})
opener = urllib.request.build_opener(proxy_handler)
response = opener.open('http://www.baidu.com')
print(response.read())
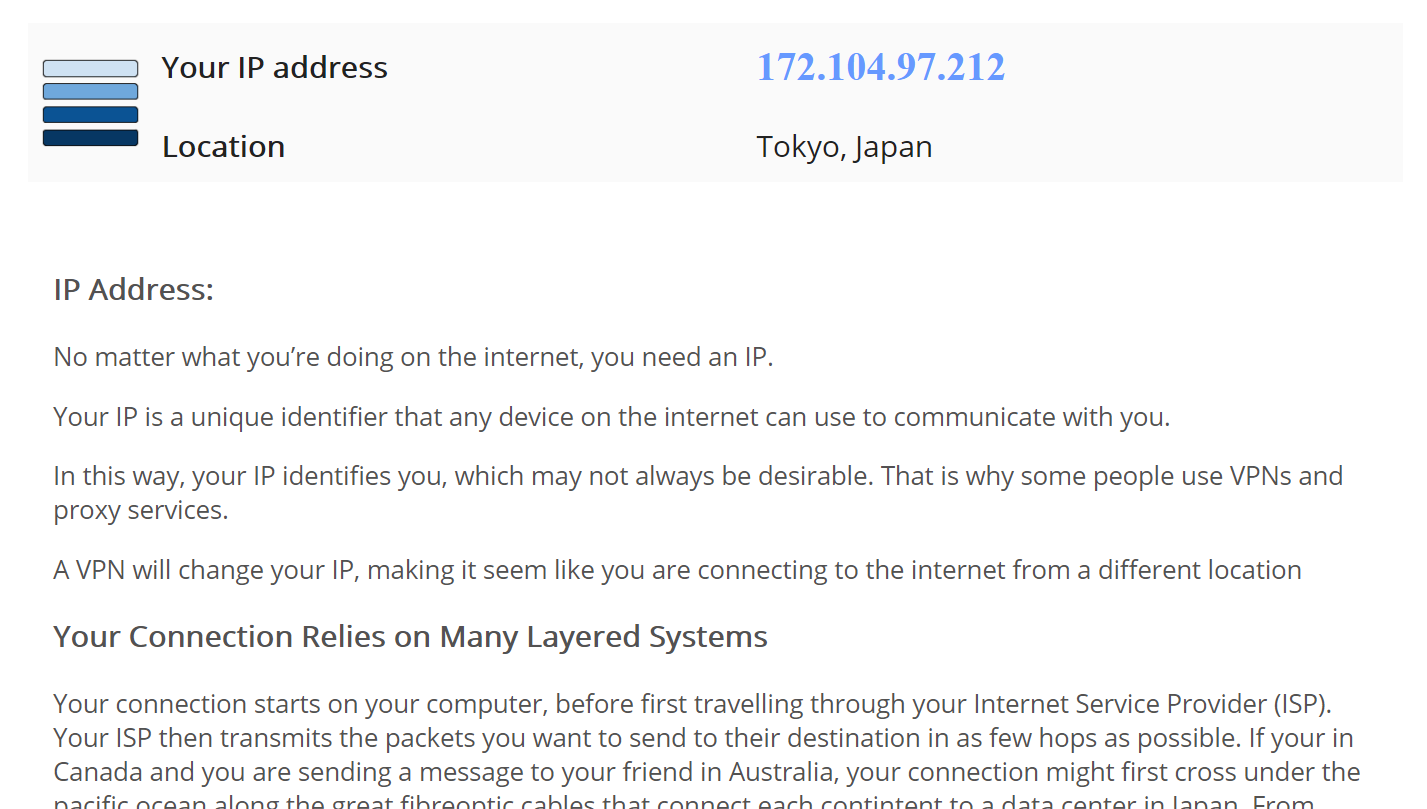
通过代理可以伪装一个ip,比如现在用一个科学上网工具,伪装的是日本ip,那这段代码会弹出浏览器显示如图信息:
Cookie
import http.cookiejar,urllib.request
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
for item in cookie:
print(item.name+"="+item.value)
import http.cookiejar,urllib.request
filename = "cookie.txt"
cookie = http.cookiejar.MozillaCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard = True,ignore_expires = True)
import http.cookiejar,urllib.request
filename = "cookie.txt"
cookie = http.cookiejar.LWPCookieJar(filename)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
cookie.save(ignore_discard = True,ignore_expires = True)
import http.cookiejar,urllib.request
cookie = http.cookiejar.LWPCookieJar()
cookie.load('cookie.txt',Ignore_discard = True,Ignore_expires=True)
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
异常处理
from urllib import request,error
try:
response = request.urlopen('http://culdjiadaqingcal.com/index.html')
except error.URLError as e:
print(e.reason)
from urllib import request,error
try:
response =request.urlopen('http://www.baidu.com/index.html')
except error.HTTPError as e:
print(e.reason,e.code,e.headers,sep = '
')
except error.URLError as e:
print(e.reason)
else:
print('Request Successfully')
import socket
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('https://www.baidu.com',timeout=0.01)
except urllib.error.URLError as e:
print(type(e.reason))
if isinstance(e.reason,socket.timeout):
print("TIME OUT")
URL解析
urlparse
urllib.parse.urlparse(urlstring,scheme='',allow_fragment=True)
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
print(type(result),result)
from urllib.parse import urlparse
result = urlparse('www.baidu.com/index.html;user?id=5#comment',scheme = 'https')
print(result)
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment',scheme = 'https')
print(result)
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment',allow_fragments=False)
print(result)
urlunparse
from urllib.parse import urlunparse
data = {'http','www.baidu.com','index.html','user','id=6','comment'}
print(urlunparse(data))
urljoin
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com','FAQ.html'))
print(urljoin('http://www.baidu.com','https://curere.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html','https://curere.com/FAQ.html'))
print(urljoin('http://www.baidu.com/about.html','https://curere.com/FAQ.html?question=2'))
print(urljoin('http://www.baidu.com?wd=abc','https://curere.com/index.php'))
print(urljoin('http://www.baidu.com','?catefory=2#comment'))
print(urljoin('www.baidu.com','?category=2#comment'))
print(urljoin('www.baidu.com#comment','?category=2'))
urlencode
from urllib.parse import urlencode
params = {
'name':'jack',
'age':22
}
base_url = 'http://www.baidu.com?'
url = base_url+urlencode(params)
print(url)
robotparser
import urllib.robotparser
rp = urllib.robotparser.RobotFileParser()
rp.set_url("http://www.musi-cal.com/robots.txt")
rp.read()
rrate = rp.request_rate("*")
rrate.requests
rrate.seconds
rp.crawl_delay("*")
rp.can_fetch("*", "http://www.musi-cal.com/cgi-bin/search?city=San+Francisco")
rp.can_fetch("*", "http://www.musi-cal.com/")