分别下载了spark 和hive 配置好 发现在元数据库里面 这2个是不通的 是需要编译spark的源码以支持hive的
在这里我用的是一台centos7的虚拟机
准备工作:
jdk的安装配置 我用的版本是1.8
hadoop的安装配置 我这里用的版本是2.7.5
maven的配置 我这用的是apache-maven-3.5.4 maven列表:https://archive.apache.org/dist/maven/maven-3/
spark的版本spark-2.3.1这个版本支持到hive1.2.1 我本机用1.2.2好像也阔以
配置好环境变量就开干,我这里的环境变量是:
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop env
export HADOOP_HOME=/opt/env/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin
#hive env
export HIVE_HOME=/opt/env/apache-hive-1.2.2-bin
export PATH=$PATH:$HIVE_HOME/bin
#maven
export M2_HOME=/opt/env/maven3
export PATH=$PATH:$JAVA_HOME/bin:$M2_HOME/bin
#scala
export SCALA_HOME=/opt/env/scala-2.11.6
export PATH=$PATH:$SCALA_HOME/bin
其中这几个必须安装吧 java,spark是scala写的 所以也必须安装 下载源代码
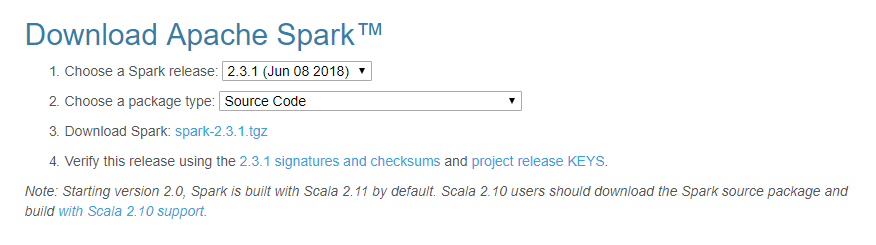
下载 spark-2.3.1.tgz
然后解压
cd spark-2.3.1 进dev目录
cd dev
vi make-distribution.sh 把 MVN=的值改成我们下载的mvn配置目录
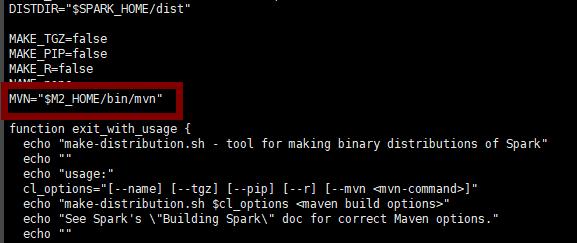
在进入 spark-2.3.1目录
mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.5 -Phive -Phive-thriftserver -DskipTests
编译中。。。。大概有26个task
编译完成:
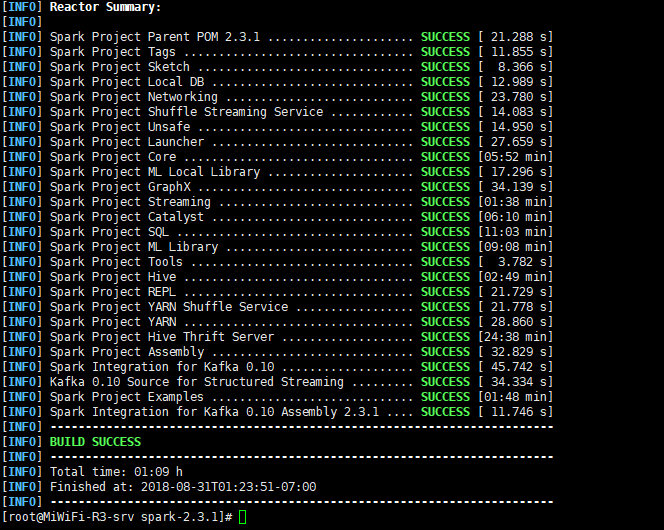
编译了这么多个模块 要了个把小时。。。。
编译成功后然后打包 打成 2.7.5hive.tar包---------------------下面打包的步骤花了2个半小时。。。。
./dev/make-distribution.sh --name 2.7.5hive --tgz -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.5 -Phive -Phive-thriftserver -DskipTests
然后捏配置好spark vi /etc/profile
增加环境变量
export SPARK_HOME=/opt/env/spark-2.3.1-bin-2.7.5hive
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
将$HIVE_HOME/conf/hive-site.xml配置文件拷贝到$SPARK_HOME/conf目录下。
将$HADOOP_HOME/etc/hadoop/hdfs-site.xml配置文拷贝到$SPARK_HOME/conf目录下
当然先启动hadoop
到hadoop/sbin/start-dfs.sh
写个脚本用spark执行一下 然后去hive查询一把 看是在spark创建的表在hive也能直接看到 命名
from pyspark import SparkContext
from pyspark.sql import HiveContext
sc=SparkContext.getOrCreate()
sqlContext = HiveContext(sc)
sqlContext.sql('use default')
sqlContext.sql('CREATE TABLE IF NOT EXISTS test(key INT, value STRING)')
sqlContext.sql('show tables').show()
在spark用pyspark执行下看:
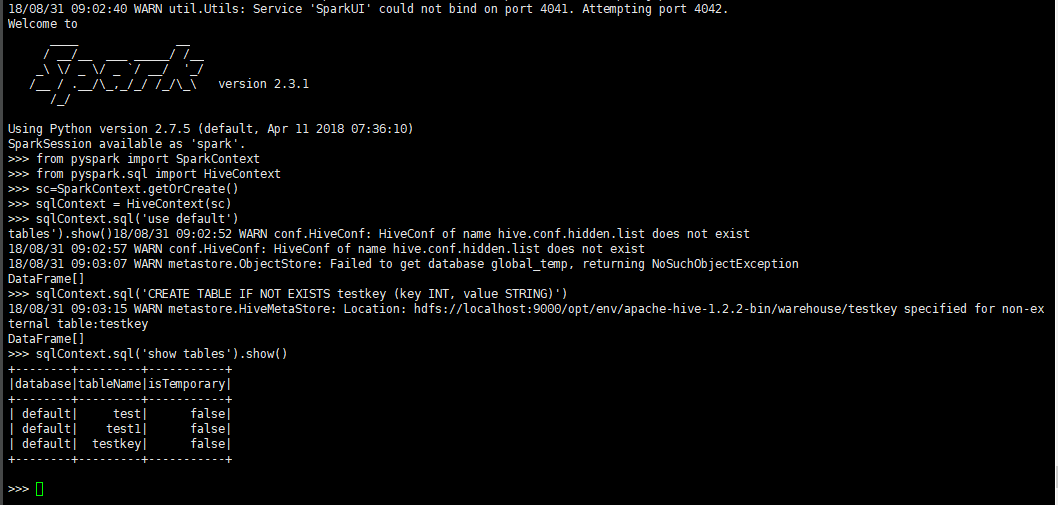
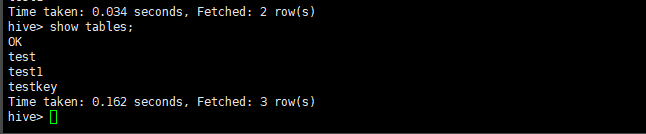
在hive下看看表
这里是编译后的版本 一个是厦大教授编译的2.1.0的版本和我编译的2.3.1版本
https://pan.baidu.com/s/1jNYhDBRvGS0s11Lah4tW0A