有 R-CNN SPPNet Fast R-CNN Faster R-CNN ... 的论文翻译
现在已经不能访问了。。。
【私人整理】空间金字塔池化网络SPPNet详解
SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》,这篇论文解决之前深度神经网络的一个大难题,即输入数据的维度一定要固定,SPP-Net网络架构在目标分类,目标检测方面取得了很好的成绩,那它到底有什么技巧,有什么新的创新思维呢?本文只用最简单地描述解析它的核心思想,至于在目标分类和目标检测方面的具体实现不涉及。
一、什么是空间金字塔池化网络——SPPNet 二、为什么要用SPP-Net 2.1、传统卷积神经网络的限制 2.2、CNN为什么需要固定的输入 三、什么是SPP-Net 3.1 SPP-Net与经典CNN的架构对比 3.2 金字塔的具体工作过程 3.3 金字塔池化层的训练过程 3.4 金字塔池化网络SPP-Net的结构设计 四、SPP-Net的应用与案例 4.1 在object classify方面的应用 4.2 在object detect方面的应用 五、拓展以及参考文献
一、什么是空间金字塔池化网络——SPPNet 所谓空间金字塔池化网络,英文全称为Spatial Pyramid Pooling Networks ,简称SPP-Net。它也是由何凯明大神与2015年首先发表的。
二、为什么要用SPP-Net 2.1、传统卷积神经网络的限制 之前的深度卷积神经网络(CNNs)都需要输入的图像尺寸固定(比如224×224)。这种人为的需要导致面对任意尺寸和比例的图像或子图像时降低识别的精度。为什么会降低精度呢?由于输入的图像大小固定,即数据维度固定,但是现实样本中往往很多样本是大小不一的,为了产生固定输入大小的样本,有两种主要的预处理措施: (1)crop(裁剪) 从上面可以看出,对原始图像进行裁剪之后,必然会有相关的特征被剔除掉了,肯定会影响到特征的提取; (2)wrap(缩放) 从上面可以看出,原始图像经过缩放之后,变得很畸形失真,这也会影响到特征提取的过程。 2.2、CNN为什么需要固定的输入 由上面的分析可得,裁剪会导致信息的丢失,变形会导致位置信息的扭曲,就会影响识别的精度。另外,一个预先定义好的尺寸在物体是缩放可变的时候就不适用了。 那么为什么CNNs需要一个固定的输入尺寸呢?CNN主要由两部分组成,卷积部分和其后的全连接部分。卷积部分通过滑窗进行计算,并输出代表激活的空间排布的特征图(feature map)。事实上,卷积并不需要固定的图像尺寸,他可以产生任意尺寸的特征图。而另一方面,根据定义,全连接层则需要固定的尺寸输入。因此固定尺寸的问题来源于全连接层,也是网络的最后阶段。 找到了问题的症结所在,现在就可以来说明解决方案了。
三、什么是SPP-Net 3.1 SPP-Net与经典CNN的架构对比 首先看一下传统CNN网络与SPP-Net网络的一个对比。 从上面的架构中可以看出,SPP-Net与经典CNN最主要的区别在于两点: 第一点:不再需要对图像进行crop/wrap这样的预处理; 第二点:在卷积层和全连接层交接的地方添加所谓的空间金字塔池化层,即(spatial pyramid pooling),这也是SPP-Net网络的核心所在。 总结:SPP-Net在最后一个卷积层后,接入了金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。
3.2 金字塔的具体工作过程 实际上,金字塔层就是几个池化层,也并没有引入新的设计思想,那它是如何保证了全连接层总是能够得到相同的输入的。 假设我们以一个三层金字塔作为例子来说明,将3.1中的图二中红色字体标注出来部分堆叠层展开,如下所示: 抽象出来为下图: 图3.1中有一个特别重要的标注信息,: fix bin numbers,do not fix bin size. 如何理解这句话? 实际上 fix bin size 正是我们经典CNN所采取的方式,即固定一个池化层的大小(size)和步幅(stride),比如池化层的大小为5*5,步幅为3,那么针对不同的输入,池化层输出之后的特征图大小当然不是不定的,自然也没有办法起到固定特征大小的作用了。 那什么又是fix bin numbers?他的意思就是我最终的的那个池化层产生的结果是固定的,即针对一个特征图,经过某一个池化层之后,我的目的就是要产生一个固定大小的特征图,比如上面的三层金字塔: 第一层:为4*4,即要保证我前面的特征图经过池化之后能够总能够产生4*4的输出,即16个特征; 第二层:为2*2,即要保证我前面的特征图经过池化之后能够总能够产生2*2的输出,及4个特征; 第三层:为1*1,即要保证我前面的特征图经过池化之后能够总能够产生1*1的输出,即1个特征; 这样一共就得到了16+4+1=21个特征了。我们将整个这三层包装成一个“金字塔层(这个名字是我自己起的,其实就相当于一个卷积核的意思)”,那么有N个“金字塔层”的时候,最后得到的输出特征为 21*N个,这是固定大小的。 了解池化层过程的小伙伴应该能够体会到这里的含义了,既然要保证对于不同的特征图输入,都能够产生相同的输出,每一个池化过程的池化核肯定是不一样的。 总结:现在可以用一句话来概括fix bin numbers,do not fix bin size.这句话的含义了。即经典的CNN中的4*4指的是一个4*4的池化核;而SPP-Net中的4*4指的是要产生固定的4*4的特征输出。
那具体我要怎么样才能保证针对不同的输入特征图,输出具有相同尺寸的输出特征图呢?这实际上就是由两个参数决定的: 第一个:a*a,指的是最后一个卷积层之后得到的输出,也即是我的金字塔池化层的输入维度; 第二个:n*n,指的是金字塔池化层的期望输出,比如上面的4*4,2*2,1*1. 那到底是怎么决定的呢?在下面的训练过程再说明。
3.3 金字塔池化层的训练过程 SPP-Net的训练过程是分为两个过程的 (1)单一尺寸训练——single-size 所谓单一尺寸训练指的是先只对一种固定输入图像进行训练,比如224*224,在conv5之后的特征图为:13x13这就是我们的(a*a)而我要得到的输出为4*4,2*2,1*1,怎么办呢?这里金字塔层bins即为 n*n,也就是4*4,2*2,1*1,我们要做的就是如何根据a和n设计一个池化层,使得a*a的输入能够得到n*n的输出。实际上这个池化层很好设计,我们称这个大小和步幅会变化的池化层为sliding window pooling。 它的大小为:windows_size=[a/n] 向上取整 , stride_size=[a/n]向下取整。数据实验如下: 当a*a为13*13时,要得到4*4的输出,池化层的大小为4,移动步幅为3; 当a*a为13*13时,要得到2*2的输出,池化层的大小为7,移动步幅为6; 当a*a为13*13时,要得到1*1的输出,池化层的大小为13,移动步幅为13;
有的小伙伴一定发现,那如果我的输入a*a变化为10*10呢,此时再用上面的三个池化核好像得不到固定的理想输出啊,事实上的确如此,这是训练的第二个过程要讲的,因为此过程称之为“单一尺度训练”,针对的就是某一个固定的输入尺度而言的。
(2)多尺寸训练——multi-size(以两种尺度为例) 虽然带有SPP(空间金字塔)的网络可以应用于任意尺寸,为了解决不同图像尺寸的训练问题,我们往往还是会考虑一些预设好的尺寸,而不是一些尺寸种类太多,毫无章法的输入尺寸。现在考虑这两个尺寸:180×180,224×224,此处只考虑这两个哦。 我们使用缩放而不是裁剪,将前述的224的区域图像变成180大小。这样,不同尺度的区域仅仅是分辨率上的不同,而不是内容和布局上的不同。 那么对于接受180输入的网络,我们实现另一个固定尺寸的网络。在论文中,conv5输出的特征图尺寸是axa=10×10。我们仍然使用windows_size=[a/n] 向上取整 , stride_size=[a/n]向下取整,实现每个金字塔池化层。这个180网络的空间金字塔层的输出的大小就和224网络的一样了。 当a*a为10*10时,要得到4*4的输出,池化层的大小为3,移动步幅为2(注意:此处根据这样的一个池化层,10*10的输入好像并得不到4*4的输出,9*9或者是11*11的倒可以得到4*4的)这个地方我也还不是特别清楚这个点,后面我会说出我的个人理解。
当a*a为10*10时,要得到2*2的输出,池化层的大小为5,移动步幅为5; 当a*a为10*10时,要得到1*1的输出,池化层的大小为10,移动步幅为10;
(3)原始论文中的两个训练过程 上面的红色字体表明了在多尺度训练过程的一个漏洞,这其实不是错误,因为我们期望得到的是4*4,2*2,1*1的特征,但是180*180的输入图却并得不到4*4的,这说明用它作为输入是不行的,那到底该怎么搞呢?后面会给出解释,我们先来看一下原始论文中的期望输出是 3*3,2*2,1*1,即期望得到特征是9+4+1=14个。
在single-size过程: 当a*a为13*13时,要得到3*3的输出,池化层的大小为5,移动步幅为4; 当a*a为13*13时,要得到2*2的输出,池化层的大小为7,移动步幅为6; 当a*a为13*13时,要得到1*1的输出,池化层的大小为13,移动步幅为13; 这没有问题:
在multi-size过程: 当a*a为10*10时,要得到3*3的输出,池化层的大小为4,移动步幅为3; 当a*a为10*10时,要得到2*2的输出,池化层的大小为5,移动步幅为5; 当a*a为10*10时,要得到1*1的输出,池化层的大小为10,移动步幅为10; 这也没有问题。 总结: 这样,这个180网络就和224网络拥有一样的参数了。换句话说,训练过程中,我们通过使用共享参数的两个固定尺寸的网络实现了不同输入尺寸的SPP-net。 为了降低从一个网络(比如224)向另一个网络(比如180)切换的开销,我们在每个网络上训练一个完整的epoch,然后在下一个完成的epoch再切换到另一个网络(权重保留)。依此往复。实验中我们发现多尺寸训练的收敛速度和单尺寸差不多。 多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。除了上述两个尺度的实现,我们也在每个epoch中测试了不同的s*s输入,s是从180到224之间均匀选取的。后面将在实验部分报告这些测试的结果。 注意,上面的单尺寸或多尺寸解析度只用于训练。在测试阶段,是直接对各种尺寸的图像应用SPP-net的。
3.4 金字塔池化网络SPP-Net的结构设计 我们知道,在设计卷积神经网络的时候,每一个卷积层、池化层的size和stride需要很好的设计,他决定了说每一次操作之后的输出特征图的大小。虽然SPP-Net名义上称之为可以处理不同尺度的输入尺寸,但是这个尺寸也没有那么的随意,因为就像上面的例子所示,不是所有的尺寸最后都可以完美的得到理想的期望输出的,那怎么办呢?注意几个点即可: (1)至少使用一个大的尺寸和一个小的尺寸。因为从大尺寸到小尺寸,不同尺度的区域仅仅是分辨率上的不同,而不是内容和布局上的不同; (2)不同的尺寸之间要能够较好的“兼容(我自己起的名字)”。指的是这个大小也不是随便乱规定的,我们需要根据最后一层卷积之后的尺寸,即a*a,以及我们期望得到的尺寸 n*n,去计算好到底哪些不同的尺寸可以“兼容”。
四、SPP-Net的应用与案例 SPP-Net从诞生开始,在图像识别、目标检测方面都有着很好的应用。 4.1 在object classify方面的应用 这里可以参考相关的论文,这里不再详细说明了。 4.2 在object detect方面的应用 SPP网络,这个方法的思想在R-CNN、Fast RCNN, Faster RCNN上都起了举足轻重的作用,对于检测算法,论文中是这样做到:使用ss生成~2k个候选框,缩放图像min(w,h)=s之后提取特征,每个候选框使用一个4层的空间金字塔池化特征,网络使用的是ZF-5的SPPNet形式。之后将12800d的特征输入全连接层,SVM的输入为全连接层的输出。这个算法可以应用到多尺度的特征提取:先将图片resize到五个尺度:480,576,688,864,1200,加自己6个。然后在map window to feature map一步中,选择ROI框尺度在{6个尺度}中大小最接近224x224的那个尺度下的feature maps中提取对应的roi feature。这样做可以提高系统的准确率。 这里有一张图来完整的描述SPP-Net。
5 拓展以及参考文献SPP的思想来源于SPM,然后SPM的思想来源自BoW。关于BoW和SPM,找到了两篇相关的博文,就不在这里展开了。) SIFT算法的应用—目标识别之Bag-of-words模型Spatial Pyramid 小结) Spatial Pyramid Matching 小结 参考文献: https://blog.csdn.net/alibabazhouyu/article/details/80058009 https://blog.csdn.net/bryant_meng/article/details/78615353 https://blog.csdn.net/v1_vivian/article/details/73275259 http://www.dengfanxin.cn/?p=403 有趣的灵魂终究会相遇 好看的皮囊风干在路上 扫码即可相遇哦 |
两阶段的图像检测总:基于深度学习的图像目标检测(上) - 知乎 https://zhuanlan.zhihu.com/p/32564990 R-CNN的前世 梯度直方图(HOG,Histogram of Gradient) - jianguo_wang - 博客园 https://www.cnblogs.com/wjgaas/p/3597248.html Histogram of Oriented Gridients(HOG) 方向梯度直方图 - handspeaker - 博客园 https://www.cnblogs.com/hrlnw/archive/2013/08/06/2826651.html PHOG特征 - ChrisZZ - 博客园 https://www.cnblogs.com/zjutzz/p/5668107.html HoG 和PHoG (pyramid HoG) - Belial计算机视觉&机器视觉专栏 - CSDN博客 https://blog.csdn.net/kezunhai/article/details/9999545 利用Hog特征和SVM分类器进行行人检测 - Leo的博客 - CSDN博客 https://blog.csdn.net/qq_26898461/article/details/46786033 DPM(Deformable Part Model)原理详解(汇总) - aerkate - 博客园 https://www.cnblogs.com/aerkate/p/7648771.html DPM(Deformable Parts Model)--原理(一) - 塔上的樹 - 博客园 https://www.cnblogs.com/JZ-Ser/p/7503319.html 目标检测--Selective Search for Object Recognition(IJCV, 2013) - Zhao-Pace - 博客园 https://www.cnblogs.com/zhao441354231/p/5941190.html 深度学习中IU、IoU(Intersection over Union)的概念理解以及python程序实现 - OLDPAN的博客 - CSDN博客 https://blog.csdn.net/iamoldpan/article/details/78799857 边框回归(Bounding Box Regression)详解 - 南有乔木NTU的博客 - CSDN博客 https://blog.csdn.net/zijin0802034/article/details/77685438/ R-CNN 原图--》候选区域生成--》对每个候选区域利用深度学习网络进行特征提取--》特征送入每一类SVM分类器中判别--》回归器修正候选框位置
RCNN--目标检测 - 鹿往森处走 - 博客园 https://www.cnblogs.com/zyber/p/6672144.html 论文笔记-RCNN - 小ks强 - 博客园 https://www.cnblogs.com/kingstrong/p/4969472.html R-CNN论文翻译——用于精确物体定位和语义分割的丰富特征层次结构 – 邓范鑫——致力于变革未来的智能技术 http://www.dengfanxin.cn/?p=383 MR-CNN Overfeet OverFeat 个人总结 - LeeWanzhi的博客 - CSDN博客 https://blog.csdn.net/LeeWanzhi/article/details/79504165 对 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 一文的理解 - 殷大侠 - 博客园 https://www.cnblogs.com/yinheyi/p/6232152.html 目标检测——overfeat – 七年一辈子 http://dnntool.com/2017/03/31/overfeat/ 深度学习(二十)基于Overfeat的图片分类、定位、检测 - hjimce的专栏 - CSDN博客 https://blog.csdn.net/hjimce/article/details/50187881 SPPNet SPP-Net论文详解 - Cheese的博客 - CSDN博客 https://blog.csdn.net/v1_vivian/article/details/73275259 SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition - mengduanhonglou的专栏 - CSDN博客 https://blog.csdn.net/mengduanhonglou/article/details/78470682 Fast-RCNN
Fast RCNN算法详解 - AI之路 - CSDN博客 https://blog.csdn.net/u014380165/article/details/72851319 Fast R-CNN论文详解 - CSDN博客 - Coding_ML - 博客园 https://www.cnblogs.com/CodingML-1122/p/9043124.html ROI Pooling原理及实现 - Elag的专栏 - CSDN博客 https://blog.csdn.net/u011436429/article/details/80279536 RoIPooling、RoIAlign笔记 - 勇者归来 - 博客园 https://www.cnblogs.com/wangyong/p/8523814.html Fast-RCNN论文翻译 – 邓范鑫——致力于变革未来的智能技术 http://www.dengfanxin.cn/?p=423 Faster-RCNN
Faster R-CNN - 目标检测详解 - 长风破浪会有时,直挂云帆济沧海 - CSDN博客 https://blog.csdn.net/zziahgf/article/details/79311275 Faster RCNN中RPN理解 - 江南烟雨尘 - 博客园 https://www.cnblogs.com/jiangnanyanyuchen/p/9433791.html Faster R-CNN 中 RPN 的总结和疑惑解答 - 简书 https://www.jianshu.com/p/cbfaa305b887 Faster R-CNN论文翻译 – 邓范鑫——致力于变革未来的智能技术 http://www.dengfanxin.cn/?p=434 Faster R-CNN论文翻译——中英文对照 - SnailTyan - CSDN博客 https://blog.csdn.net/quincuntial/article/details/79132243 R-CNN、Fast-RCNN、Faster-RCNN 【RCNN系列】【超详细解析】 - Tiffany的博客 - CSDN博客 https://blog.csdn.net/amor_tila/article/details/78809791 faster-rcnn原理及相应概念解释 - 白鹭倾城 - 博客园 https://www.cnblogs.com/dudumiaomiao/p/6560841.html 推荐:RCNN系列总结(RCNN,SPPNET,Fast RCNN,Faster RCNN) - Mingjian_LI的博客 - CSDN博客 https://blog.csdn.net/hust_lmj/article/details/78974348 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN - Madcola - 博客园 https://www.cnblogs.com/skyfsm/p/6806246.html 【目标检测】R-CNN系列与SPP-Net总结 - 向前奔跑的少年 - 博客园 http://www.cnblogs.com/kk17/p/9748378.html R-FCN R-FCN详解 - WZZ18191171661的博客 - CSDN博客 https://blog.csdn.net/WZZ18191171661/article/details/79481135 |
|



变分自编码器(Variational Autoencoder, VAE)通俗教程安利一篇邓范鑫的关于变分自编码器VAE的讲解文,易读,读完觉得受益匪浅。码住,以后可以温故知新~ 1. 神秘变量与数据集
一言以蔽之:神秘变量代表了神秘力量的神秘组合关系。 这里我们澄清一下隶属空间,假设数据集DX是m个点,这m个点也应该隶属于一个空间,比如一维的情况,假如每个点是一个实数,那么他的隶属空间就是实数集,所以我们这里定义一个DX每个点都属于的空间称为XS,我们在后面提到的时候,你就不再感到陌生了。 神秘变量z可以肯定他们也有一个归属空间称为ZS。 下面我们就要形式化地构造X与Z的神秘关系了,这个关系就是我们前面说的神秘力量,直观上我们已经非常清楚,假设我们的数据集就是完全由这n个神秘变量全权操控的,那么对于X中每一个点都应该有一个n个神秘变量的神秘组合 zj来神秘决定。 接下来我们要将这个关系再简化一下,我们假设这n个神秘变量不是能够操控X的全部,还有一些其他的神秘力量,我们暂时不考虑,那么就可以用概率来弥补这个缺失,为什么呢?举个例子,假设我们制造了一个机器可以向一个固定的目标发射子弹,我们精确的计算好了打击的力量和角度,但由于某些难以控制的因素,比如空气的流动,地球的转动导致命中的目标无法达到精准的目的,而这些因素可能十分巨大和繁多,但是他们并不是形成DX的主因素,根据大数定理,这些所有因素产生的影响可以用高斯分布的概率密度函数来表示。它长这样: p(x|μ,σ2)=12πσe−(x−μ)22σ2
当μ=0时,就变成了这样: p(x|σ2)=12πσe−x22σ2
这是一维高斯分布的公式,那么多维的呢?比较复杂,推导过程见知乎,长这样: 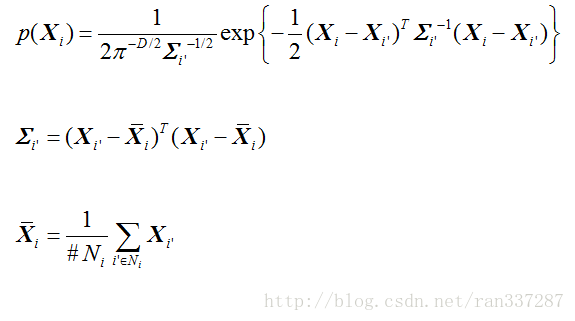
不管怎样,你只要记住我们现在没有能力关注全部的神秘变量,我们只关心若干个可能重要的因素,这些因素的分布状况可以有各种假设,我们回头再讨论他们的概率分布问题,我们现在假定我们对他们的具体分布情况也是一无所知,我们只是知道他们处于ZS空间内。 设一个数据集为DX,那么这个数据集存在的概率为Pt(DX),则根据贝叶斯公式有: Pt(DX)=∫Pxz(DX|z;θ)Pz(z)dz; (1) 好了,其实公式(1)就是我们的神秘力量与观察到的数据集之间的神秘关系,这个关系的意思我们直白的说就是:当隐秘变量按照某种规律存在时,就非常容易产生现在我们看到的这个数据集。那么,我们要做的工作就是当我们假定有n个神秘力量时,我们能够找到一个神奇的函数f,将神秘力量的变化转化成神奇的x的变化,这个x能够轻而易举地生成数据集DX。 接下来我们回到讨论Pxz(DX|z;θ)这个概率密度函数上来,我们前面说过,如果z是全部的神秘力量,那么它产生的变量x就一定固定的,即当z取值固定时,x取值固定,但是现实中还有很多其他的因素,因而x的取值还与他们有关,他们的影响力,最终反映成了高斯函数,所以我们大胆假定Pxz是一个高斯分布的概率密度函数,即Pxz(DX|z;θ)=N(DX|f(x;θ),σ2∗I) 假定我们知道z现在取某一个或几个特定值,那么我们就可以通过Gradient Descent来找到一个θ尽量满足z能够以极高的概率生成我们希望的数据集DX。再一推广,就变成了,z取值某一范围,但去几个特定值或某一取值范围是就面临z各种取值的概率问题,我们回头再讨论这个棘手的问题,你现在只要知道冥冥之中,我们似乎可以通过学习参数θ寻找最优解就行了。 OK,我们还要说一个关键问题,就是我们确信f是存在的,我们认为变量与神秘变量之间的关系一定可以用一个函数来表示。 2. 变分自编码器(VAE) 如果我们沿着这个思路进行下去,就会陷入泥潭,我们可以巧妙地避开这些问题,关键就在于让他们继续保持“神秘”! 我们不关心每一个维度代表什么含义,我们只假定存在这么一群相互独立的变量,维度我们也回到之前的讨论,我们虽然不知道有多少,我们可以假定有n个主要因素,n可以定的大一点,比如假设有4个主因素,而我们假定有10个,那么最后训练出来,可能有6个长期是0。最后的问题需要详细讨论一下,比较复杂,就是z的概率分布和取值问题。 既然z是什么都不知道,我们是不是可以寻找一组新的神秘变量w,让这个w服从标准正态分布N(0,I)。I是单位矩阵,然后这个w可以通过n个复杂函数,转换成z呢?有了神经网络这些也是可行的,假设这些复杂函数分别是h1,h2,…,hn,那么有z1=h1(w1),…,zn=hn(wn)。而z的具体分布是什么,取值范围是多少我们也不用关心了,反正由一个神经网络去算。回想一下P(DX|z;θ)=N(DX|f(z;θ),σ2×I),我们可以想象,如果f(z;θ)是一个多层神经网络,那么前几层就用来将标准正态分布的w变成真正的隐变量z,后面几层才是将z映射成x,但由于w和z是一一对应关系,所以w某种意义上说也是一股神秘力量。就演化成w和x的关系了,既然w也是神秘变量,我们就还是叫回z,把那个之前我们认为的神秘变量z忘掉吧。 好,更加波澜壮阔的历程要开始了,请坐好。 我们现在已经有了 Pz(z)=N(0,I), Pxz(DX|z;θ)=N(DX|f(x;θ),σ2∗I), Pt(DX)=∫Pxz(DX|z;θ)Pz(z)dz, 我们现在就可以专心攻击f了,由于f是一个神经网络,我们就可以梯度下降了。但是另一个关键点在于我们怎么知道这个f生成的样本,和DX更加像呢?如果这个问题解决不了,我们根本都不知道我们的目标函数是什么。 3. 设定目标函数 离散概率分布的KL公式 KL(p∥q)=∑p(x)logp(x)q(x)
连续概率分布的KL公式 KL(p∥q)=∫p(x)logp(x)q(x)dx
Pz(z|DX)和Q(z|DX)的KL散度为 D[Q(z|DX)∥Pz(z|DX)]=∫Q(z|DX)[logQ(z|DX)–logPz(z|DX)]
也可写成 D[Q(z|DX)∥Pz(z|DX)]=Ez∼Q[logQ(z|DX)–logPz(z|DX)]
通过贝叶斯公式 Pz(z|DX)=P(DX|z)P(z)P(DX)
这里不再给P起名,其实Pz(z)直接写成P(z)也是没有任何问题的,前面只是为了区分概念,括号中的内容已经足以表意。 D[Q(z|DX)∥Pz(z|DX)]=Ez∼Q[logQ(z|DX)–logP(DX|z)–logP(z)]+logP(DX)
因为logP(DX)与z变量无关,直接就可以提出来了,进而得到闪闪发光的公式(2): logP(DX)−D[Q(z|DX)∥Pz(z|DX)]=Ez∼Q[logP(DX|z)]–D[Q(z|DX)∥P(z)]
; (2) 公式(2)是VAE的核心公式,我们接下来分析一个这个公式。 公式的左边有我们的优化目标P(DX),同时携带了一个误差项,这个误差项反映了给定DX的情况下的真实分布Q与理想分布P的相对熵,当Q完全符合理想分布时,这个误差项就为0,而等式右边就是我们可以使用梯度下降进行优化的,这里面的Q(z|DX)特别像一个DX->z的编码器,P(DX|z)特别像z->DX的解码器,这就是VAE架构也被称为自编码器的原因。 由于DX早已不再有分歧,我们在这里把所有的DX都换成了X。 我们现在有公式(2)的拆分: logP(X)
– 左侧第二项:
D(Q(z|X∥P(z|X))
– 右边第一项:
Ez∼Q[logP(X|z)]
– 右边第二项:
D[Q(z|X)∥P(z)]
还有下面这些: – P(z)=N(0,I), – P(X|z)=N(X|f(z),σ2∗I), – Q(z|X)=N(z|μ(X),Σ(X)) 我们再明确一下每个概率的含义: – P(X)——当前这个数据集发生的概率,但是他的概率分布我们是不知道,比如,X的空间是一个一维有限空间,比如只能取值0-9的整数,而我们的 X = { 0, 1, 2, 3, 4 },那么当概率分布是均匀的时候,P(X)就是0.5,但是如果不是这个分布,就不好说是什么了,没准是0.1, 0.01,都有可能。P(X)是一个函数,就好像是一个人,当你问他X=某个值的时候,他能告诉发生的概率。 – P(z) —— 这个z是我们后来引入的那个w,还记得吗?他们都已经归顺了正态分布,如果z是一维的,那他就是标准正态分布N(0, I)。 – P(X|z) —— 这个函数的含义是如果z给定一个取值,那么就知道X取某个值的概率,还是举个例子,z是一个神奇的变量,可以控制在计算机屏幕上出现整个屏幕的红色并且控制其灰度,z服从N(0,1)分布,当z=0时代表纯正的红色,z越偏离0,屏幕的红色就越深,那么P(X|z)就表示z等于某个值时X=另一值的概率,由于计算机是精确控制的,没有额外的随机因素,所以如果z=0能够导致X取一个固定色值0xFF0000,那么P(X=0xFF0000|z=0)=1,P(x!=0xFF0000|z=0) = 0,但如果现实世界比较复杂附加其他的随机因素,那么就可能在z确定出来的X基础值之上做随机了。这就是我们之前讨论的,大数定理,P(X|z)=N(X|f(x),σ2∗I)。f(z)就是X与z直接关系的写照。 – P(z|X) —— 当X发生时,z的概率是多少呢?回到刚才计算机屏幕的例子,就非常简单了P(z=0|X=0xFF0000) = 1, P(z!=0|X=0xFF0000) = 0,但是由于概率的引入,X|z可以简化成高斯关系,相反,也可以简化高斯关系。这个解释对下面的Q同样适用。 – Q(z) —— 对于Q的分析和P的分析是一样的,只不过Q和P的不同时,我们假定P是那个理想中的分布,是真正决定X的最终构成的背后真实力量,而Q是我们的亲儿子,试着弄出来的赝品,并且希望在现实世界通过神经网络,让这个赝品能够尝试控制产生X。当这个Q真的行为和我们理想中的P一模一样的时候,Q就是上等的赝品了,甚至可以打出如假包换的招牌。我们的P已经简化成N(0,I),就意味着Q只能向N(0, I)靠拢。 – Q(z|X) —— 根据现实中X和Q的关系推导出的概率函数, 当X发生时,对应的z取值的概率分布情况。 – Q(X|z) —— 现实中z发生时,取值X的概率。 我们的目标是优化P(X),但是我们不知道他的分布,所以根本没法优化,这就是我们没有任何先验知识。所以有了公式(2),左边第二项是P(z|X)和Q(z|X)的相对熵,意味着X发生时现实的分布应该与我们理想的分布趋同才对,所以整个左边都是我们的优化目标,只要左边越大就越好,那么右边的目标就是越大越好。 右边第一项:Ez∼Q[logP(X|z)]就是针对面对真实的z的分布情况(依赖Q(z|X),由X->z的映射关系决定),算出来的X的分布,类似于根据z重建X的过程。 现在我们对这个公式的理解更加深入了。接下来,我们要进行实现的工作。 4. 实现 KL(N(μ,Σ)∥N(0,I))=12[−log[det(Σ)]−d+tr(Σ)+μTμ]
det是行列式,tr是算矩阵的秩,d是I的秩即d=tr(I)。 变成具体的神经网络和矩阵运算,还需要进一步变化该式: KL(N(μ,Σ)∥N(0,I))=12Σi[−log(Σi)+Σi+μi2−1]
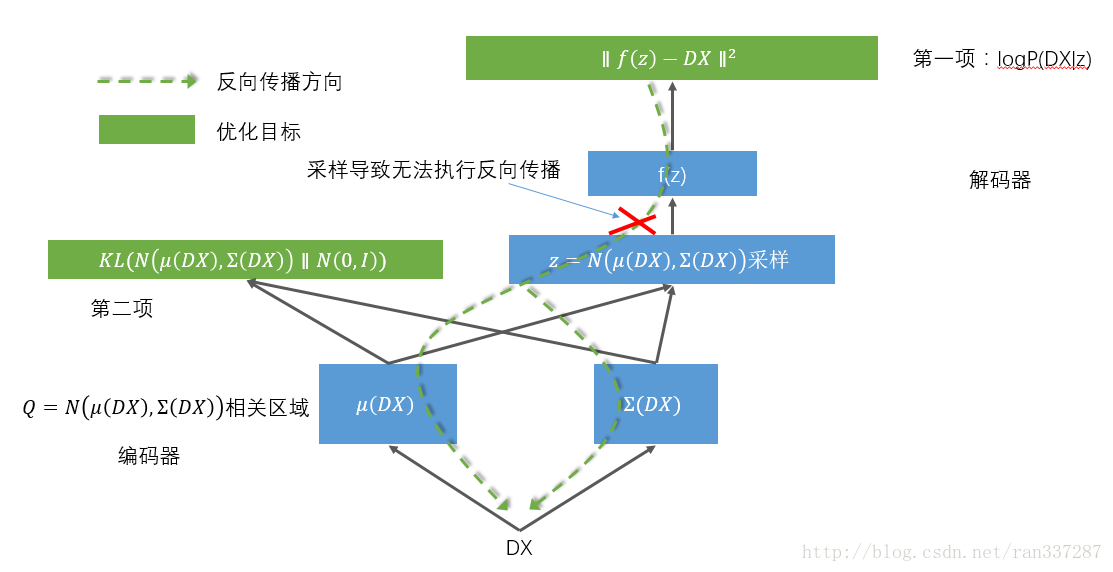
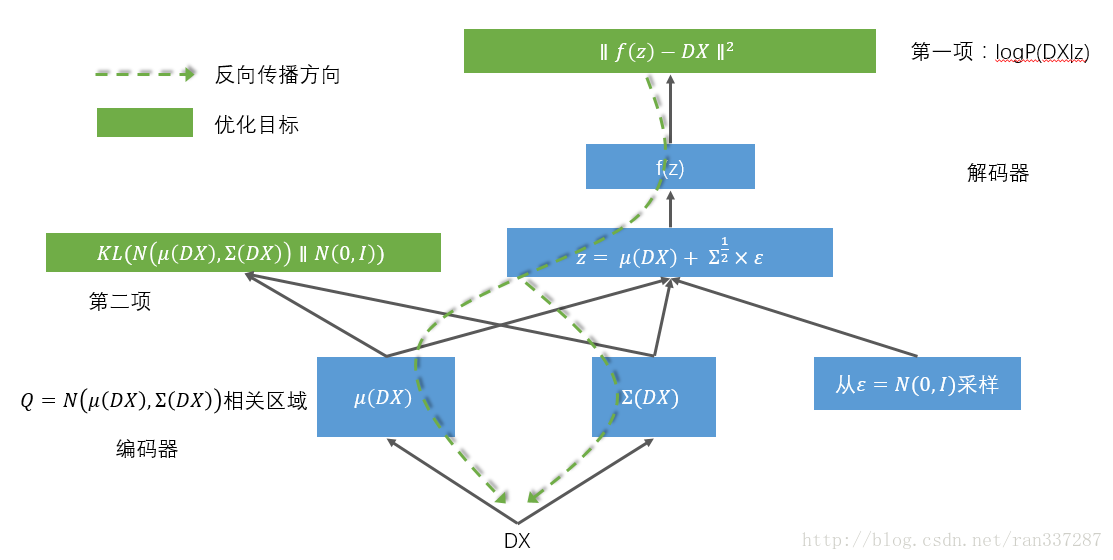
OK,这个KL我们也会计算了,还有一个事情就是编码器网络,μ(X)和Σ(X)都使用神经网络来编码就可以了。 第一项是Ez∼Q[logP(X|z)]代表依赖z重建出来的数据与X尽量地相同,z->X重建X构成了解码器部分,整个重建的关键就是f函数,对我们来说就是建立一个解码器神经网络。 到此,整个实现的细节就全都展现在下面这张图里了 由于这个网络传递结构的一个环节是随机采样,导致无法反向传播,所以聪明的前辈又将这个结构优化成了这样: 这样就可以对整个网络进行反向传播训练了。 具体的实现代码,我实现在了这里: 里面的每一步,都有配合本文章的对照解释。 5. 延伸思考 [1] http://stats.stackexchange.com/questions/60680/kl-divergence-between-two-multivariate-gaussians |
|
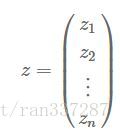 z也起个名字叫神秘组合。
z也起个名字叫神秘组合。