如何利用CAM(类激活图)动态可视化模型的学习过程
这几天研究了下 CNN 进行图像识别过程中的类激活图(CAM, Class Activation Map),然后发现这个东东真的是相当好玩!因为它能够以几乎拟人的方式,生动形象的呈现模型在训练过程中是如何从一无所知的瞎猜小白逐步进化为阅片无数的老司机的。
- 训练过程动图GIF 1

- 训练过程动图GIF 2

下面就把学习过程分享给大家。
1. 背景知识
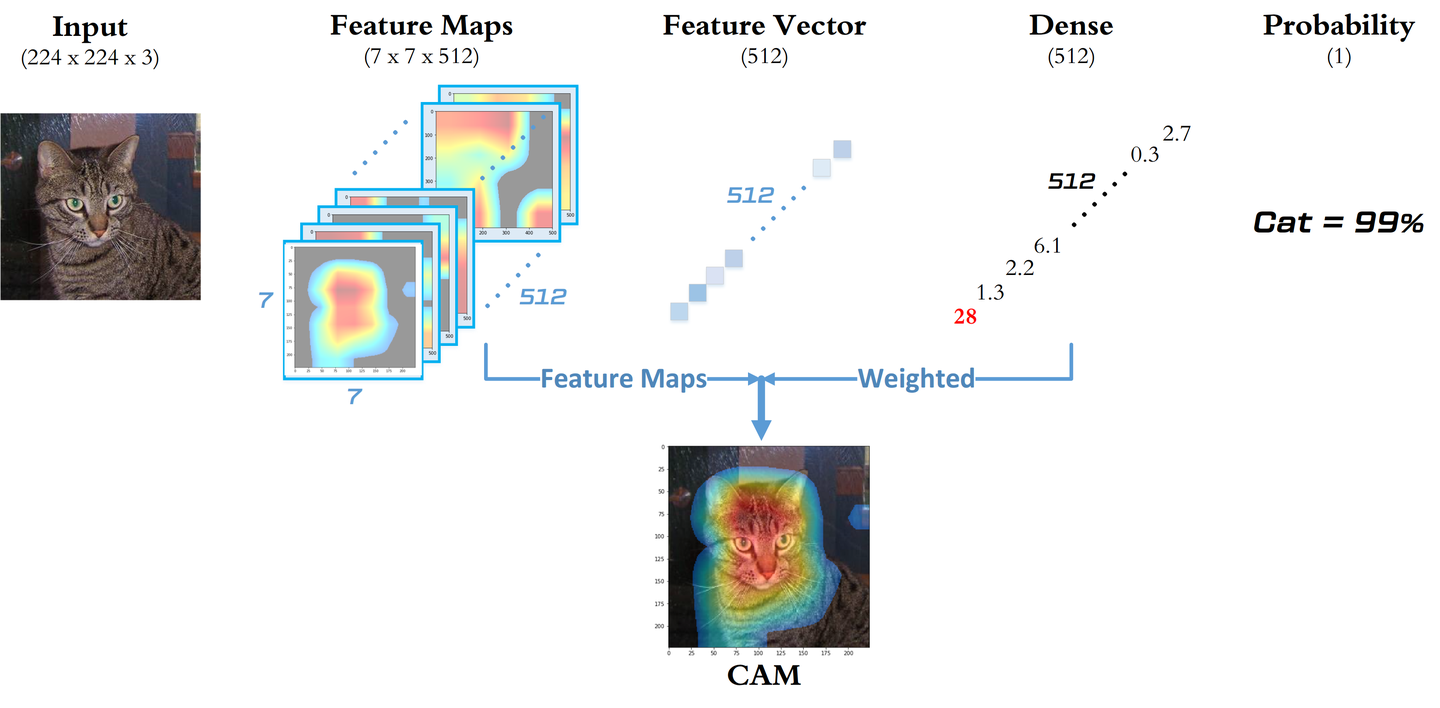
以预训练 VGG16 + 自训练分类器为例,处理图像二分类问题。采用迁移学习策略,将卷积层的参数全部冻结,只训练分类器的权重矩阵 ,可以将模型抽象为以下流程图:
可以看到,
- 模型的输入是训练集图片本身,每张图片尺寸为 [224, 224, 3]
- VGG16 预训练模型卷积层部分的最后一层具有 512 个卷积核,因此输出为 [7, 7, 512]
- 经过全局平均池化(GAP)后,512张特征图被精简浓缩为一个长度为512的特征向量
- 最后,特征向量与权重矩阵
点积,再经过 Sigmoid 函数压缩为 [0, 1] 区间内的概率
2. 什么是CAM
CAM 指的是 经过
由于采用迁移学习策略,因而整个模型在训练时,会发生变化的参数只有分类器的权重矩阵 ,因此对于同一张图片,卷积层输出的特征图集始终不变,但分类概率会随着
的变化而不断改变。这也就是模型学习的过程,即:到底哪些特征图对于提高分类准确率最有帮助?
可以看到,模型做出分类决策的依据来源于 矩阵。那么如何进行可视化呢?
矩阵本身只是一堆大小不一的权值而已,并不直观。不过我们可以注意到,
矩阵对图像的理解基于对特征向量的加权,而特征向量背后是一个个特征图,因此可以跳过特征向量,直接将这些特征图用
加权,再重叠合成为一张特征图,就可以很直观的看到到底模型是通过看哪片区域来做出判断的。
以猫狗大战数据集为例,假设对于一张猫咪的图片,刚开始训练时,由于 的值刚刚初始化,此时模型听信
矩阵,选择了第10/20/30号特征图作为判断依据,判断图像 84% 是狗。由于这么预测的Loss很大,因此在后续反向传播的时候不断更新
矩阵,开始逐渐以第99/100/101号等特征图作为判断依据,直到能够判断图像 100% 是猫的时候,模型基本上就学会了如何判断猫狗。
代码实现
完整代码实现Notebook请见我的Github: Class Activation Map Visualizations 数据集来自 Kaggle 的猫狗大战: Dogs VS Cat
1. 创建模型
- 基模型直接使用只含卷积层部分的预训练 VGG16 模型
- 在基模型的基础上追加GAP、Dropout、Dense,即分类器部分
- 采用 Transfer Learning 策略:锁定 base_model 所有层的参数,仅允许训练分类器部分的参数(只有512+1=513个参数)
base_model = VGG16(include_top=False, weights='imagenet')
for layers in base_model.layers:
layers.trainable = False
y = GlobalAveragePooling2D()(base_model.output)
y = Dropout(0.25)(y)
y = Dense(1, activation='sigmoid')(y)
model = Model(inputs=base_model.input, outputs=y)
model.compile(optimizer='adadelta',
loss='binary_crossentropy',
metrics=['accuracy'])
2. 训练模型
- 想要看到模型 "成长的过程",就需要了解模型在每个Batch后权重更新的状态。具体在这里,由于模型的卷积层参数已经冻结,并不会对模型的成长有任何贡献,因此实际上模型的进化过程完全由输出层的这513个权重参数决定。
- 具体实现上,我们需要定义一个Lambda Callback,用来备份在每个batch结束时最后一层的权重数值。
- 模型仅经过一代训练就可以达到 94.5% 的验证集准确率,我们应该能在稍后的处理之后欣赏到模型从50%上升到94.5%的完整心路历程。
from keras.callbacks import LambdaCallback
weights_history = []
get_weights_cb = LambdaCallback(on_batch_end=lambda batch,
logs: weights_history.append(model.layers[-1].get_weights()[0]))
history = model.fit(x=X_train, y=y_train,
batch_size=16,
epochs=1,
validation_data=(X_val, y_val),
callbacks=[get_weights_cb])
3. 权重处理
- 从卷积层的输出到最后预测的概率值还要先经过全局平均池化、乘以权重、经过Sigmoid这三步才能得到,需要用下面的函数手动实现下。
# 根据卷积层输出特征图集和模型某一参数状态计算预测概率(为了简单省略了bias计算)
def predict_on_weights(out_base, weights):
gap = np.average(out_base, axis=(0, 1))
logit = np.dot(gap, np.squeeze(weights))
return 1 / (1 + np.e ** (-logit))
predict_on_weights(out_base, weights_history[42])
4. CAM计算
- CAM本身计算很简单,只需要(predict - 0.5) * np.matmul(out_base, weights) 就可以了
- 为了将原本尺寸为 7 x 7 的CAM矩阵以热图的方式呈现出来,需要进行一些处理,包括归一化和格式化等等。
- 通过 Seaborn 画出的色带如下,可以看到数值 - 颜色的映射关系,方便选择门限值(这里我选的是100),对热图中小于门限值的区域进行置0,即透明化。

- 然后将源图像与热图合成,添加文字标注,这样导出视频后可以看到预测的变化过程。
def getCAM(weights, display=False):
predict = predict_on_weights(out_base, weights)
# Weighted Feature Map
cam = (predict - 0.5) * np.matmul(out_base, weights)
# Normalize
cam = (cam - cam.min()) / (cam.max() - cam.min())
# Resize as image size
cam_resize = cv2.resize(cam, (224, 224))
# Format as CV_8UC1 (as applyColorMap required)
cam_resize = 255 * cam_resize
cam_resize = cam_resize.astype(np.uint8)
# Get Heatmap
heatmap = cv2.applyColorMap(cam_resize, cv2.COLORMAP_JET)
# Zero out
heatmap[np.where(cam_resize <= 100)] = 0
out = cv2.addWeighted(src1=target, alpha=0.8, src2=heatmap, beta=0.4, gamma=0)
out = cv2.resize(out, dsize=(500, 500))
if predict < 0.5:
text = 'cat %.2f%%' % (100 - predict * 100)
else:
text = 'dog %.2f%%' % (predict * 100)
cv2.putText(out, text, (290, 50), fontFace=cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.9,
color=(123,222,238), thickness=2, lineType=cv2.LINE_AA)
if display:
plt.imshow(out[:, :, ::-1])
plt.show()
return out
5. 导出为视频
- 视频本质上就是一个快速播放的图片幻灯片,所以不断调用getCAM并写入VideoWriter就可以了。
- 使用VideoWriter生成视频,为了方便在iOS上播放,这里使用的是MP4V的编码格式。
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
out = cv2.VideoWriter('output4.mp4',fourcc, 20.0, (400, 400))
for weight in weights_history:
img = getCAM(weight)
out.write(img)
cv2.imshow('frame', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
out.release()
cv2.destroyAllWindows()
6. 总结

通过上面的动图可以看到一些有趣的现象:
- 每次从头训练看到的模型学习过程都不太一样,比如有的时候一开始识别为狗,有的时候一上来就蒙对了。这应该与
- 模型在一开始主要关注的区域(红色)比较靠上,包括了耳朵和额头,但是随着模型看到的各式猫狗图片越来越多,模型的注意力慢慢的开始向下移动,耳朵的重要性慢慢下降,同时也开始涉猎胡子区域。下面是一些无责任的无脑猜测:也许是模型发现耳朵并不是一个区分猫狗的很好依据,毕竟有些品种的猫狗耳朵十分类似。还有就是关于胡子变得重要起来的原因,可能是因为猫的胡子比狗要长一些,而且猫的胡子具有实际的功能:猫的胡子可以过的地方,猫身体就可以通过等等。
- 另外需要注意的是,由于模型对于不同图片的特征图是不同的,因此模型看不同图片的区域也是不同的。读者可以自行尝试在其他图片上模型的训练过程。
总之,CAM可视化能够让模型不再仅仅是程序,而是具有了拟人的性格,看上去的效果有点类似于跟踪人眼在看其他物体时眼神的跳跃过程一样,很有意思。
附录
- 动态可视化CAM的代码:mtyylx/Class Activation Map Visualizations
- 培神的Github,对学习做猫狗大战很有启发:ypwhs/dogs_vs_cats