样本权重对逻辑回归评分卡的影响探讨
风控业务背景
在统计学习建模分析中,样本非常重要,它是我们洞察世界的窗口。在建立逻辑回归评分卡时,我们也会考虑对样本赋予不同的权重weight,希望模型学习更有侧重点。
诚然,我们可以通过实际数据测试来检验赋权前后的差异,但我们更希望从理论上分析其合理性。毕竟理论可以指导实践。本文尝试探讨样本权重对逻辑回归评分卡的影响,以及从业务和技术角度分析样本权重调整的操作方法。
目录
Part 1. 样本加权对WOE的影响
Part 2. 采样对LR系数的影响
Part 3. 样本准备与权重指标
Part 4. 常见工具包的样本赋权
Part 5. 总结
致谢
版权声明
参考资料
Part 1. 样本加权对WOE的影响
在《WOE与IV指标的深入理解应用》一文中,我们介绍了WOE的概念和计算方法。在逻辑回归评分卡中,其具有重要意义。其公式定义如下:
现在,我们思考在计算WOE时,是否要考虑样本权重呢?
如图1所示的样本,我们希望对某些样本加强学习,因此对年龄在46岁以下的样本赋予权重1.5,而对46岁以上的样本赋予权重1.0,也就是加上权重列weight。此时再计算WOE值,我们发现数值发生变化。这是因为权重的改变,既影响了局部bucket中的 ,也影响了整体的
。
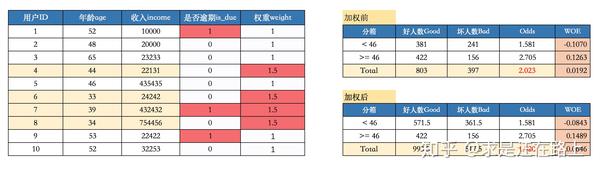 图 1 - 样本加权前后的Odds和WOE变化
图 1 - 样本加权前后的Odds和WOE变化
我们有2种对样本赋权后的模型训练方案,如图2所示。
- 方案1:WOE变换利用原训练集,LR模型训练时利用加权后的样本。
- 方案2: WOE变换和LR模型训练时,均使用加权后的样本。
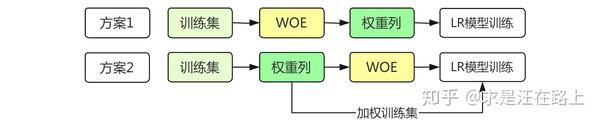 图 2 - 样本赋权后的两种模型训练方案
图 2 - 样本赋权后的两种模型训练方案
个人更倾向于第一种方案,原因在于:WOE变换侧重变量的可解释性,引入样本权重会引起不可解释的困扰。
Part 2. 采样对LR系数的影响
我们定义特征向量 。记
,那么逻辑回归的公式组成便是:
其中,第2行到第3行的变换是基于朴素贝叶斯假设,即自变量 之间相互独立。
是指总体(训练集)的
,指先验信息
是指自变量引起的
因此,随着观察信息的不断加入,对群体的好坏 判断将越来越趋于客观。
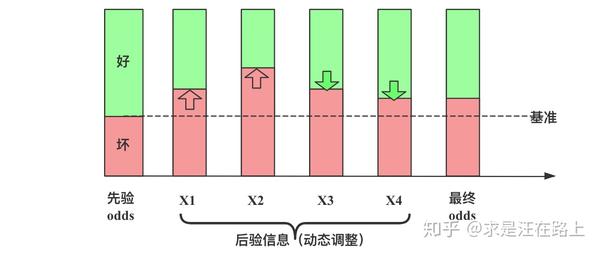 图 3 - 逻辑回归原理的贝叶斯图解
图 3 - 逻辑回归原理的贝叶斯图解
样本权重调整直接影响先验项,也就是截距。那对系数的影响呢?
接下来,我们以过采样(Oversampling)和欠采样(Undersampling)为例,分析采样对LR系数的影响。如图4所示,对于不平衡数据集,过采样是指对正样本简单复制很多份;欠采样是指对负样本随机抽样。最终,正负样本的比例将达到1:1平衡状态。
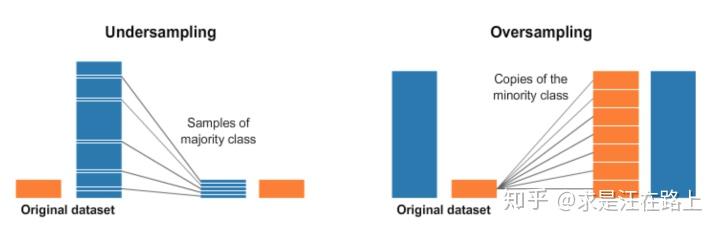 图 4 - 欠采样(左)和过采样(右)
图 4 - 欠采样(左)和过采样(右)
我们同样从贝叶斯角度进行解释:
假设采样处理后的训练集为 。记
和
分别表示正负样本数,那么显然:
由于 ,因此对应截距将发生变化。
无论是过采样,还是欠采样,处理后的新样本都和原样本服从同样的分布,即满足:
因此, ,即系数不发生变化。
Part 3. 样本准备与权重指标
风控建模的基本假设是未来样本和历史样本的分布是一致的。模型从历史样本中拟合 和
之间的关系,并根据未来样本的
进行预测。因此,我们总是在思考,如何选择能代表未来样本的训练样本。
如图5所示,不同时间段、不同批次的样本总是存在差异,即服从不同的总体分布。因此,我们需要从多个维度来衡量两个样本集之间的相似性。
从迁移学习的角度看,这是一个从源域(source domain)中学习模式,并应用到目标域(target domain)的过程。在这里,源域是训练集,目标域指测试集,或者未来样本。
这就会涉及到一些难点:
- 假设测试集OOT与未来总体分布样本基本一致,但未来样本是不可知且总是在发生变化。
- 面向测试集效果作为评估指标,会出现在测试集上过拟合现象。
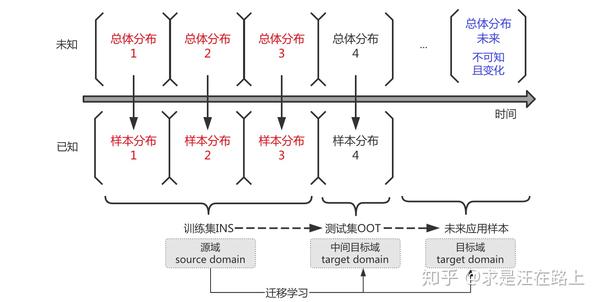 图 5 - 训练集样本与未来应用样本
图 5 - 训练集样本与未来应用样本
那么,建模中是否可以考虑建立一个权重指标体系,即综合多方面因素进行样本赋权?我们采取2种思路来分析如何开展。
业务角度:
- 按时间因素,对近期样本提高权重,较远样本降低权重。这是考虑近期样本与未来样本之间的“相似度”更高,希望模型学到更多近期样本的模式。
- 按贷款类型,不同额度、利率、期限的样本赋予不同权重,这需要结合业务未来的发展方向。例如,未来业务模式希望是小额、短期、低利率,那就提高这批样本的权重。
- 按样本分群,不同群体赋予不同权重。例如,按流量获客渠道,如果未来流量渠道主要来自平台A,那么就提高这批样本权重。
结合以上各维度,可得到总体采样权重的一种融合方式为:
这种业务角度的方案虽然解释性强,但实际拍定多大的权重显得非常主观,实践中往往需要不断尝试,缺少一些理论指导。
技术角度:
- 过采样、欠采样等,从样本组成上调整正负不平衡。
- 代价敏感学习,在损失函数对好坏样本加上不同的代价。比如,坏样本少,分错代价更高。
- 借鉴Adaboost的做法,对误判样本在下一轮训练时提高权重。
在机器学习中,有一个常见的现象——Covariate Shift,是指当训练集的样本分布和测试集的样本分布不一致的时候,训练得到的模型无法具有很好的泛化 (Generalization) 能力。
其中一种做法,既然是希望让训练集尽可能像测试集,那就让模型帮助我们做这件事。如图6所示,将测试集标记为1,训练集标记为0,训练一个LR模型,在训练集上预测,概率越高,说明这个样例属于测试集的可能性越大。以此达到样本权重调整的目的。
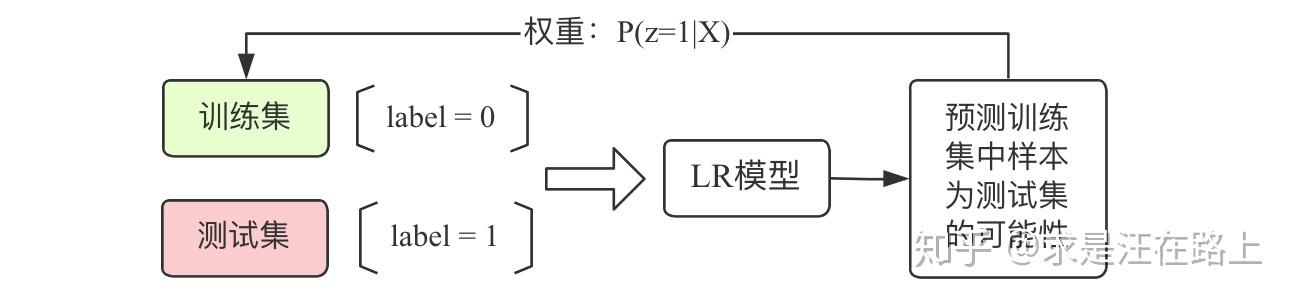 图 6 - 借助分类模型的样本权重调整
图 6 - 借助分类模型的样本权重调整
Part 4. 常见工具包的样本赋权
现有Logistic Regression模块主要来自sklearn和scipy两个包。很不幸,scipy包并不支持直接赋予权重列。这是为什么呢?有统计学家认为,尊重真实样本分布,人为主观引入样本权重,反而可能得出错误的结论。
 图 7 - 不支持样本赋权的观点(摘自网络)
图 7 - 不支持样本赋权的观点(摘自网络)
因此,我们只能选择用scikit-learn。样本权重是如何体现在模型训练过程呢?查看源码后,发现目前主要是体现在损失函数中,即代价敏感学习。
# Logistic loss is the negative of the log of the logistic function.
# 添加L2正则项的逻辑回归对数损失函数
out = -np.sum(sample_weight * log_logistic(yz)) + .5 * alpha * np.dot(w, w)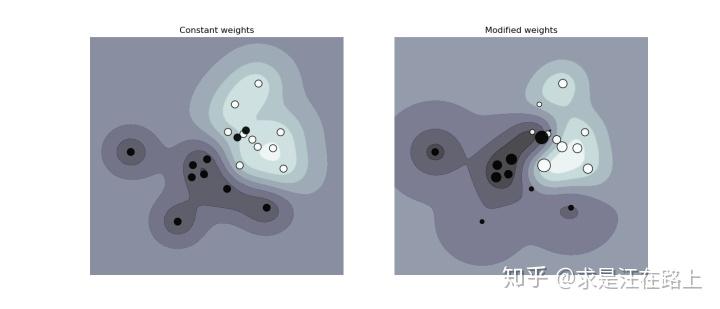 图 8 - 样本权重对决策分割面的影响
图 8 - 样本权重对决策分割面的影响
以下是scikit-learn包中的逻辑回归参数列表说明,可以发现调节样本权重的方法有两种:
- 在class_weight参数中使用balanced
- 在调用fit函数时,通过sample_weight调节每个样本权重。
如果同时设置上述2个参数,那么样本的真正权重是class_weight * sample_weight.
sklearn.linear_model.LogisticRegression - scikit-learn 0.22.2 documentation那么,在评估模型的指标时,是否需要考虑抽样权重,即还原真实场景下的模型评价指标?笔者认为,最终评估还是需要还原到真实场景下。例如,训练集正负比例被调节为1:1,但这并不是真实的 ,在预测时将会偏高。因此,仍需要进行模型校准。
Part 5. 总结
本文系统整理了样本权重的一些观点,但目前仍然没有统一的答案。据笔者所知,目前在实践中还是采取以下几种方案:
- 尊重原样本分布,不予处理,LR模型训练后即为真实概率估计。
- 结合权重指标综合确定权重,训练完毕模型后再进行校准,还原至真实概率估计。
值得指出的是,大环境总是在发生变化,造成样本分布总在偏移。因此,尽可能增强模型的鲁棒性,以及策略使用时根据实际情况灵活调整,两者相辅相成,可能是最佳的使用方法。
欢迎大家一起讨论业界的一些做法。
致谢
所有参考资料中的各位作者,感谢给我的启发。文中仍有理解不到位之处,在此抛砖引玉。
版权声明
欢迎转载分享,请在文章中注明作者和原文链接,感谢您对知识的尊重和对本文的肯定。
原文作者:求是汪在路上(知乎ID)
原文链接:https://zhuanlan.zhihu.com/p/110982479/
⚠️著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处,侵权转载将追究相关责任。