Pointer-Generator-Network
写在前面
这篇是sequence2sequence中比较优秀的模型,发于2017 ACL。随着NLP的大热,各种技术日新月异,即使近两年前的模型也已经OUT,但是对于初学者还是很有裨益的。本篇阅读笔记仅仅从模型的实现的角度,关注模型框架的架构,对于实验结果不在讨论,有兴趣可以翻看原文。
0 文章来源
《Get To The Point: Summarization with Pointer-Generator Networks》
下载地址:https://arxiv.org/pdf/1704.04368.pdf
发表机构:ACL 2017
1 原文概述
指针生成网络其实是PointerNetwork的延续,应用于摘要生成任务中。该网络使用generator保留了其生成能力的同时,用pointer从原文中Copy那些OOV词来保证信息正确的重复。原文更为重要的创新点是应用了coverage mechanism来解决了seq2seq的通病--repitition,这个机制可以避免在同一位置重复,也因此避免重复生成文本。下面是模型结构。
2 Baseline sequence-to-sequence
首先是基准seq2seq+attention的模型结构,原文的Pointer-Generator Networks也是在此基础上构建的,框架如图1所示:
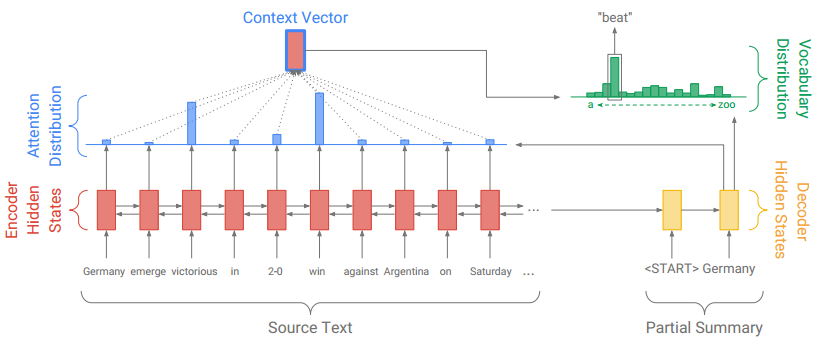 图1 Baseline Seq2Seq
图1 Baseline Seq2Seq
正常来讲,Seq2Seq的模型结构就是两部分--编码器和解码器。正常思路是先用编码器将原文本编码成一个中间层的隐藏状态,然后用解码器来将该隐藏状态解码成为另一个文本。Baseline Seq2Seq在编码器端是一个双向的LSTM,这个双向的LSTM可以捕捉原文本的长距离依赖关系以及位置信息。编码时词嵌入经过双向LSTM后得到编码状态 。在解码器端,解码器是一个单向的LSTM,训练阶段时参考摘要词依次输入(测试阶段时是上一步的生成词),在时间步
得到解码状态
。使用
和
得到该时间步原文第
个词注意力权重:
得到的注意力权重和 加权求和得到重要的上下文向量
(context vector):
可以看成是该时间步通读了原文的固定尺寸的表征。然后将
和
经过两层线性层得到单词表分布
:
其中 是拼接。这样就得到了一个sofmax的概率分布,就可以预测需要生成的词:
在训练阶段,时间步 时的损失为:
,那么原输入序列的整体损失为:
3 Pointer-Generator Networks
原文中的Pointer-Generator Networks是一个混合了 Baseline seq2seq和PointerNetwork的网络,它具有Baseline seq2seq的生成能力和PointerNetwork的Copy能力。如何权衡一个词应该是生成的还是复制的?原文中引入了一个权重 。图2是该网络的模型结构:
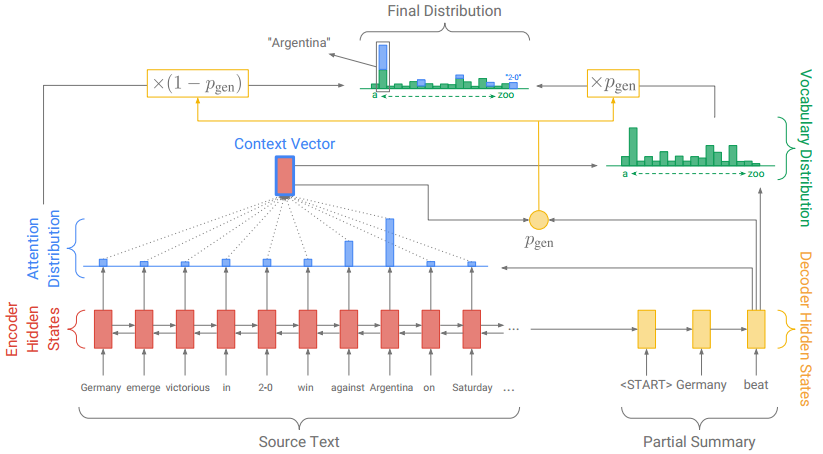 图2 Pointer-Generator Networks
图2 Pointer-Generator Networks
从Baseline seq2seq的模型结构中得到了 和
,和解码器输入
一起来计算
:
这时,会扩充单词表形成一个更大的单词表--扩充单词表(将原文当中的单词也加入到其中),该时间步的预测词概率为:
其中 表示的是原文档中的词。我们可以看到解码器一个词的输出概率有其是否拷贝是否生成的概率和决定。当一个词不出现在常规的单词表上时
为0,当该词不出现在文档中时
为0。
4 Coverage Mechanism
原文中最大的亮点就是运用了Coverage Mechanism来解决重复生成文本的问题,图3反映了前两个模型与添加了Coverage Mechanism生成摘要的结果:
 图3 生成摘要结果比较
图3 生成摘要结果比较
蓝色的字体表示的是参考摘要,三个模型的生成摘要的结果差别挺大。红色字体表明了不准确的摘要细节生成(UNK未登录词,无法解决OOV问题),绿色的字体表明了模型生成了重复文本。为了解决此问题--Repitition,原文使用了在机器翻译中解决“过翻译”和“漏翻译”的机制--Coverage Mechanism(具体参考(邮递员小王:《Modeling Coverage for Neural Machine Translation》阅读笔记)。
具体实现上,就是将先前时间步的注意力权重加到一起得到所谓的覆盖向量 (coverage vector),用先前的注意力权重决策来影响当前注意力权重的决策,这样就避免在同一位置重复,从而避免重复生成文本。计算上,先计算coverage vector
:
然后添加到注意力权重的计算过程中,用来计算
:
同时,为coverage vector添加损失是必要的,coverage loss计算方式为:
这样coverage loss是一个有界的量 。因此最终的LOSS为:
5 实验数据集下载
CNN/Daily Mail数据集的参照及下载地址:DMQA、CNN&Dailymail:Teaching Machines to Read and Comprehend。
文章被以下专栏收录
推荐阅读

BiDAF:机器理解之双向注意力流

文本分类_DPCNN

DIM:通过最大化互信息来学习深度表征
还没有评论