StackGAN
未经授权,严禁任何形式转载!
能力有限,欢迎指正批评!
参考
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networkshanzhanggit/StackGAN-Pytorchgithub.com
引入
行业现状
根据文字描述,人工生成高质量图片的任务是计算机视觉领域一个挑战,并且有很多应用场景。现有的文字转图像方式很难表现文字的含义,并且细节部分缺失严重,不够生动具体。
现有的模型(如 Vanilla GAN)只是简单的添加 upsampling 层来生成高分辨率的图,这会导致训练不稳定,且生成无用的图片,如图一 (c) 所示。
 图 1 :StackGAN 与 Vanilla GAN 的输出对比
图 1 :StackGAN 与 Vanilla GAN 的输出对比
GAN 生成高维图片的主要问题在于,自然图像分布与模型分布在高维空间上几乎不交叠。当要生成的图像分辨率增大时,该问题更加明显。(这里参考 令人拍案叫绝的Wasserstein GAN)
本文工作
提出 StackGAN 分段式结构
本文提出了 Stacked Generative Adversarial Networks (StackGAN) 结构,用于根据文字描述,生成对应的 256 * 256 的真实图像(首次这么高的分辨率)。我们将该问题分解为可处理的子问题。
首先是 Stage-I,根据给定的文字描述,勾勒初始的形状和色彩,生成低分辨率的图像,如图一 (a) 所示。
然后 Stage-II 根据 Stage-I 生成的低分辨率图像以及原始文字描述,生成具有更多细节的高分辨率图像。这个阶段可以重新捕获被 Stage-I 忽略的文字描述细节,修正 Stage-I 的的结果的缺陷,并添加改良的细节,如图一 (b) 所示。
从低分辨率图像生成的模型分布与自然图像分布相交叠的概率更好。这就是 Stage-II 能够生成高分辨率图像的根本原因。
提出 Conditioning Augmentation 技术
对于 text-to-image 生成任务,text-image 训练数据对(image + text)数量有限,这将导致文本条件多样性的稀疏性(sparsity in the text conditioning manifold),而这种稀疏性使得 GAN 很难训练。
因此,我们提出了一种新颖的条件增强技术(Conditioning Augmentation technique) 来改善生成图像的多样性,并稳定 conditional-GAN 的训练过程,这使得隐含条件分布更加平滑 (encourages smoothness in the latent conditioning manifold)。
大量实验
在基准数据集上,与一些先进的模型进行比对,结果表明,性能提升很大。
模型解析
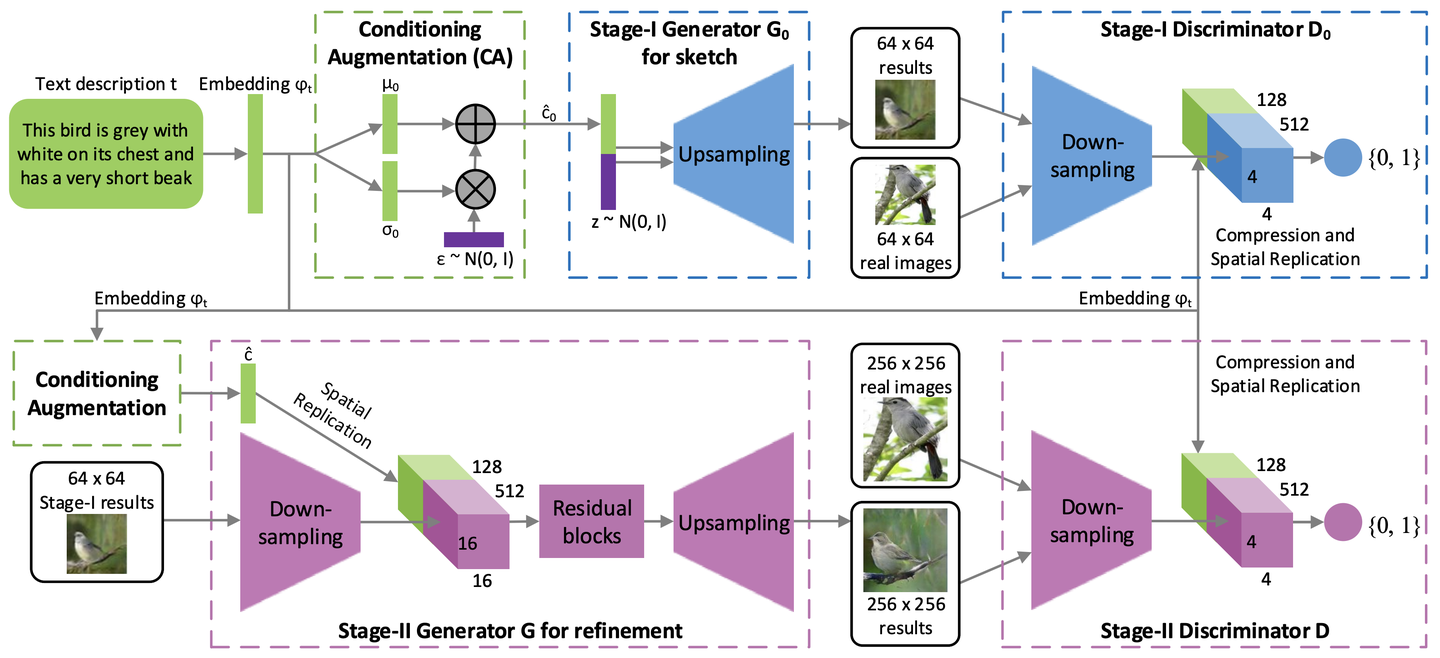
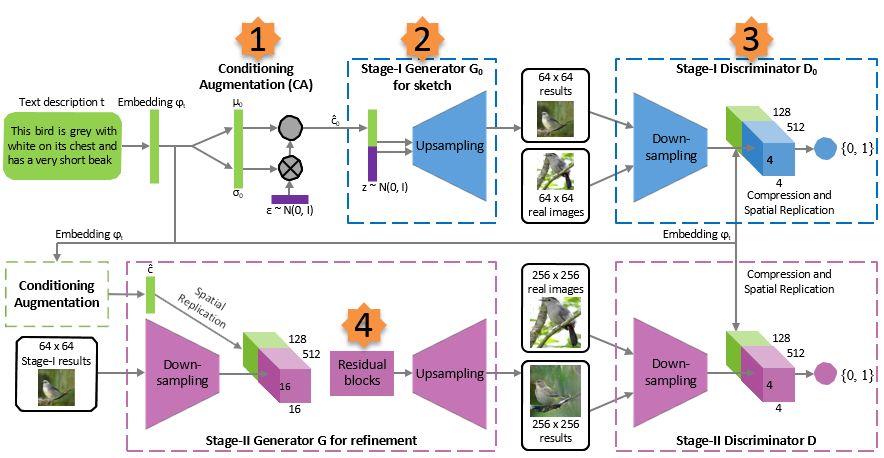
StackGAN 的模型结构如下图所示:
 图 2 :StackGAN 的模型结构
图 2 :StackGAN 的模型结构
Conditioning Augmentation
如图 2 所示,描述文字首先被预训练好的编码器编码为词嵌入向量 。
在前人的研究中,词嵌入向量被非线性的转换为生成条件隐含变量,并作为生成器的输入。然而,词嵌入的隐含空间维度维度一般很高(> 100)。当输入数据量很少的时候,通常会导致隐含变量分布空间不连续(大部分值为 0,太过稀疏),这对生成器的训练不利。
因此,我们引入条件增强 (Conditioning Augmentation) 来产生额外的条件变量 。我们不是选定固定的
,而是从独立高斯分布
中随机采样。其中,均值
和对角方差矩阵
是关于词嵌入向量
的函数(全连接层子网络)。
上面一段话,换言之就是,将原始词向量分布映射到一个高斯分布中,均值和方差不变。
给定较少的 text-image 对,通过该手段,也能够生成更多的训练样本,并且对于条件空间的微小扰动,其稳健型也更好。为了进一步增强条件分布的平滑性,以及避免过拟合(引入噪声相当于数据增强),我们使用 KL 散度对其正则化:
上面的即标准高斯分布与条件高斯分布之间的 KL 散度(Kullback-Leibler divergence)。条件增强过程中引入的随机性有助于 text-image 转换,因为同样的文字描述可能对应着不同的目标姿势,外观等等,这种随机性有助于增加多样性。
Stage-I GAN
理论基础
Stage-I 阶段主要用于生成粗略的形状和颜色等。先从 中随机采样出
,并随机采样的高斯噪声
z,将它们进行 concatenate ,然后作为 Stage-I 的输入,来训练判别器 和
,分别对应如下目标函数:
其中,真实图像 和文本描述 t 源自于实际数据分布
。
z 表示从高斯分布分布 中随机提取的噪声向量。
为正则化参数,用于平衡公式
(3) 中的两项。
我们的实验中,设置为 。其中,
是与网络剩余部分一起学习。
模型结构
Conditioning Augmentation
对于生成器 ,为了获取文本条件变量
,词嵌入向量
首先通过全连接层来生成高斯分布
中的
。
然后,从中随机采样出 。其中,
表示对应元素相乘,且
。
随后将获取的 与
维噪声向量进行拼接(
concatenate),作为 的输入,通过一组上采样
up-sampling 生成 的图像。
对于判别器 ,首先用全连接层将词向量
压缩到
,随后进行空间性重复,得到
。同时,将图像输入到一系列下采样
down-sampling ,从而得到 尺寸的
tensor。
随后,将文本 tensor 和图像 tensor 进行拼接,然后输入到一个 的卷积层,从而同时综合文本和图像的信息。最后,用一个只有一个节点的全连接层来生成置信度得分。
Stage-II GAN
理论基础
Stage-I 阶段生成的低分辨率图像通常缺乏鲜明的目标特征,并且可能包含一些变形。同时,文本描述中的部分信息可能也未体现出来。所以,通过 Stage-II 可以在 Stage-I 生成的低分辨率图像和文本描述的基础上,生成高分辨率图片,其修正了 Stage-I的缺陷,并完善了被忽略的文本信息细节。
Stage-II 以高斯隐含变量 以及 `Stage-I` 的生成器的输出
为输入,来训练生成器
G 和判别器 D,其目标函数分别为:
模型结构
Conditioning Augmentation
首先就是通过词向量 来获取
,其过程与
Stage-I 一样。
G
首先 通过空间重复,变成
的
tensor(这里的空间上重复使之,将原来的 在
的维度上,进行重复,得到
)。
同时,将 Stage-I 的输出通过下采样网络,变成尺寸为 的
tensor,并与上面的文本 的
tensor 在通道的维度上进行拼接。
接着,将上面的 tensor 送入一系列的残差块,从而习得综合文本描述和图像信息的特征。
最后,用上采样网络进行处理,从而生成 的图像。
D
判别器部分与 Stage-I 别无二致,除了输入尺寸的变化导致的下采样层不同。
此外,在训练阶段,判别器的输入中,正类样本为真实图像及其对应的文本描述;而负类样本包含两种,分别为:真实图像和不匹配的文本描述,以及生成的图像和其对应的文本描述。
实现细节(网络实现,参数和训练)
上采样网络由 nearest-neighbor 上采样组成(如下图所示)。上采样后,接一个 ,步长为
1 的卷积层。除了最后一层卷积层之外,其余各卷积层后面均接上 batch normalization 层以及 ReLU 层激活函数。
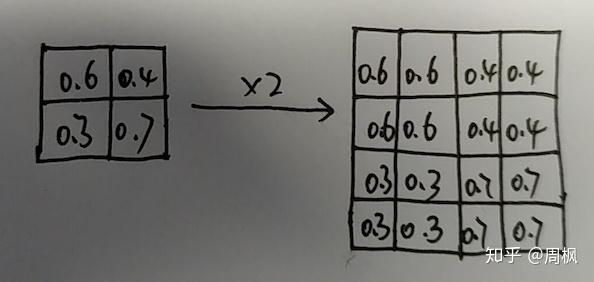 nearest-neighbor
nearest-neighbor
残差块由尺寸为 ,步长为
1 的卷积层,以及 BN 层和 ReLU 层构成。对于 的模型,需要
2 个残差块;对于 的模型,需要
4 个残差块。
下采样网络由尺寸为 ,步长为
2 的卷积层,以及 BN 和 LeakyReLU 组成,除了第一层外,没有加 BN。
默认情况下, 。
训练过程如下:首先固定 Stage-II,训练 Stage-I 的 和
600 个 epoch。然后固定 Stage-I,再训练 Stage-II 的 D 和 G 600 个 epoch。
所有的网络用 Adam 优化器,batch size 为 64,初始的学习速率为 0.0002,且每 100 个 epoch,学习速率减小为之前的 。
实验结果
Datasets and evaluation metrics
CUB 数据集包含 200 种鸟类,共 11788 张图片。其中,80% 的图片目标尺寸只占据图像的面积不到 0.5。所以,需要进行 crop 预处理,使之大于 0.75。
Oxford-102 包含 8189 张图片,共 102 类花。同时为了保证泛化性能,还尝试了 MS COCO 数据集,其包含多目标以及不同背景。MS COCO 有 40K 的图像。其中,每张图片对应 5 个描述信息。而 CUB 和 Oxford-102 数据集每张图片对应 10 个信息。
Evaluation metrics
用如下公式进行算法评估:
其中,x 表示生成的样本,y 表示模型预测的标签。其表示,好的模型应该生成多样但是有意义的图像。因此,边缘分布 (marginal distribution) 和条件分布
(conditional distribution) 之间的
KL 散度应该较大。
在我们的实现中,直接使用 COCO 数据集对 Inception 进行预训练,然后分别用 CUB 和 Oxford-102 进行 fine-tune(得到两个模型)。
尽管 Inception 得分一定程度上表征生成图像的质量,但是不能表征是否按照文字描述生成的图像。因此,对于 CUB 和 Oxford-102 测试集,随机选择 50 个文本描述;而对于 COCO 数据集,随机选取 4K 个文本描述来进行验证。对于每条描述,生成 5 张图像。对于每个给定的文字描述,选 10 名用户来评判不同模型的结果,分别取均值作为各模型的结果。
Quantitative and qualitative results
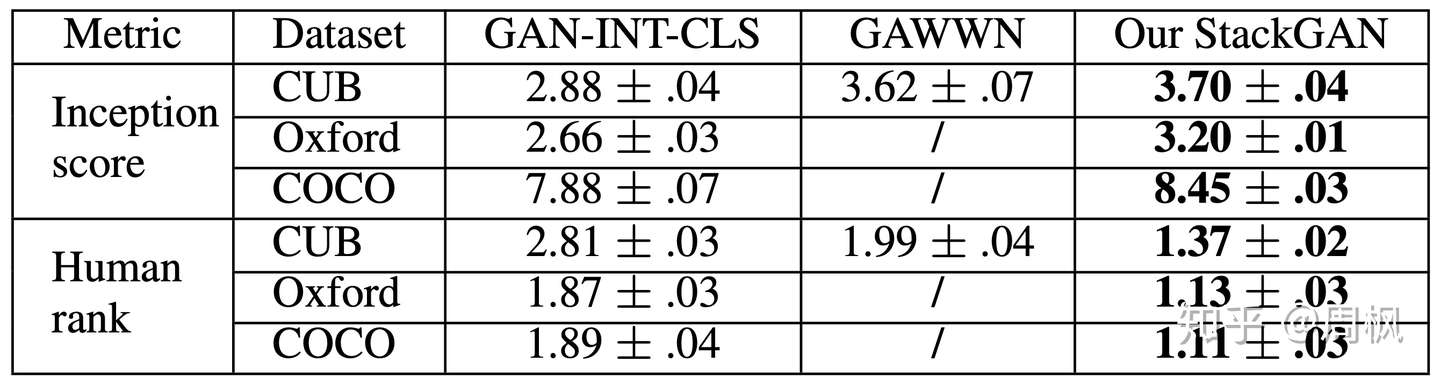 表 1:Inception scores and average human ranks
表 1:Inception scores and average human ranks 图 3:不同 GAN 模型在 CUB 上的生成结果
图 3:不同 GAN 模型在 CUB 上的生成结果 图 4:Oxford-102 数据集上的 GANs 生成结果
图 4:Oxford-102 数据集上的 GANs 生成结果
Component analysis
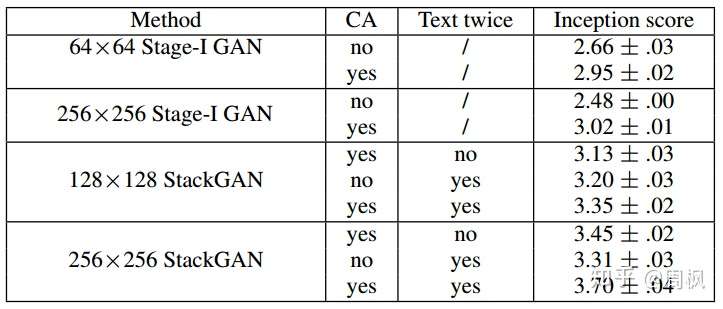 表 2:不同基准下的 StackGAN 生成的 Inception score
表 2:不同基准下的 StackGAN 生成的 Inception score
The design of StackGAN
如表 2 第一行所示,如果不使用 CA (Conditioning Augmentation),则 inception score 明显下降。这表明, CA 是有必要的。如图 5 所示,第一行没有用 CA,生成结果并不理想,且形式单一(mode collapse)。而用 CA 之后,生成结果较好,且具备多样性。
 表 2:不同基准下的 StackGAN 生成的 Inception score
表 2:不同基准下的 StackGAN 生成的 Inception score
此外,将输出从 减小到
,
inception score 会从 3.7 降到 3.35。所有的图像在计算 inception score 之前会首先缩放到 。
而如果仅增加图像尺寸,而不添加更多信息,则 inception score 不会随着输出分辨率而改变。所以 的输出会包含更多信息。
对于 的
StakeGAN,如果文本信息( )只在一个阶段添加,而在
Stage-II 中不添加,则得分会从 3.7 将为 3.45。这表明,Stage-II 会根据文本信息,改善 Stage-I 的结果。
【代码】StackGAN
Paper:StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN
TensorFLow code:hanzhanggit/StackGAN
论文笔记:【论文阅读】StackGAN: Text to Photo-realistic Image Synthesis with Stacked GAN
这篇学习代码↓↓↓
 按照图片序号顺序分析代码
按照图片序号顺序分析代码
1.![[公式]](https://www.zhihu.com/equation?tex=%5Cvarphi+_%7Bt%7D) 的处理
的处理
stackGAN 没有直接将 embedding 作为 condition ,而是用 embedding 接了一个 FC 层从得到的独立的高斯分布中随机采样得到隐含变量(
,
)。其中
和
是关于
的函数。之所以这样做的原因是,embedding 通常比较高维,而相对这个维度来说, text 的数量其实很少,如果将 embedding 直接作为 condition,那么这个 latent variable 在 latent space 里就比较稀疏,这对训练不利。
StageI/model.py
def generate_condition(self, c_var):
conditions =
(pt.wrap(c_var).
flatten().
custom_fully_connected(self.ef_dim * 2).
apply(leaky_rectify, leakiness=0.2))
mean = conditions[:, :self.ef_dim]
log_sigma = conditions[:, self.ef_dim:]
return [mean, log_sigma]StageI/train.py
def sample_encoded_context(self, embeddings):
'''Helper function for init_opt'''
c_mean_logsigma = self.model.generate_condition(embeddings)
mean = c_mean_logsigma[0]
if cfg.TRAIN.COND_AUGMENTATION:
# epsilon = tf.random_normal(tf.shape(mean))
epsilon = tf.truncated_normal(tf.shape(mean))
stddev = tf.exp(c_mean_logsigma[1])
c = mean + stddev * epsilon
kl_loss = KL_loss(c_mean_logsigma[0], c_mean_logsigma[1])
else:
c = mean
kl_loss = 0
return c, cfg.TRAIN.COEFF.KL * kl_loss上述代码出现了KL损失,目的是正则化:为了防止过拟合或者方差太大的情况,generator 的 loss 里面加入了对这个分布的正则化: 。
StageI/model.py
# reduce_mean normalize also the dimension of the embeddings
def KL_loss(mu, log_sigma):
with tf.name_scope("KL_divergence"):
loss = -log_sigma + .5 * (-1 + tf.exp(2. * log_sigma) + tf.square(mu))
loss = tf.reduce_mean(loss)
return loss2.生成器 ![[公式]](https://www.zhihu.com/equation?tex=G_0)
StageI/model.py
def generator(self, z_var):
node1_0 =
(pt.wrap(z_var).
flatten().
custom_fully_connected(self.s16 * self.s16 * self.gf_dim * 8).
fc_batch_norm().
reshape([-1, self.s16, self.s16, self.gf_dim * 8]))
node1_1 =
(node1_0.
custom_conv2d(self.gf_dim * 2, k_h=1, k_w=1, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 2, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm().
apply(tf.nn.relu).
custom_conv2d(self.gf_dim * 8, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
node1 =
(node1_0.
apply(tf.add, node1_1).
apply(tf.nn.relu))
node2_0 =
(node1.
# custom_deconv2d([0, self.s8, self.s8, self.gf_dim * 4], k_h=4, k_w=4).
apply(tf.image.resize_nearest_neighbor, [self.s8, self.s8]).
custom_conv2d(self.gf_dim * 4, k_h=3, k_w=3, d_h=1, d_w=1).
conv_batch_norm())
node2_1 =