真正的无监督学习之二——Contrastive Multiview Coding
Deep cluster是过于naive的方法。从Contrastive Predictive Coding (CPC)出世后,self-supervised learning达到了新的高度。以本文为例,在完全无监督的情况下,用resnet101达到了60.1%的top1,并且提取的特征使用在其他任务,如分割,检测中,可以达到与使用预训练模型的方法非常接近的结果。然而,作者只开源了核心部分,由于ICCV没中,需要等一段时间才能开源全部技巧。
【github】https://github.com/HobbitLong/CMC/
Contrastive Multiview Coding
- 简介
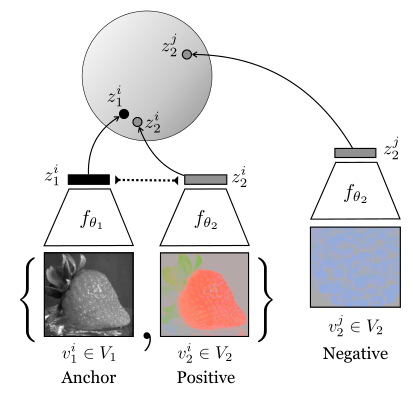
本文基于三个核心思想:contrastive learning,mutual information maximization和deep representation learning。简单来说,就是选取同一场景的不同views/不同场景的views来对比,最大化同一场景的交互信息(让同一场景views生成的embedding的invariance部分尽可能接近),基于抽取embedding的相似度来判断场景的相似度。
- Contrastive Multiview Coding
首先,解释一下如何获取多views。将RGB的图像空间映射到Lab空间,再将每张图片拆分成L(光照)和ab(色度),就得到了同一图片的两个不同views。这两个views互为正对,与其他图片的views为负对(这在后面的NCE中需要用到)
1、Predictive learning:

假设 代表光照,
代表色度,Predictive方法是从
-隐含变量-
。构建两个函数
和
,再使用loss,如L1或L2,来迫使
接近
。很自然的,该方法可以用在上色,风格转换,vision2sound等任务中。
然而,该方法有个最大的问题,就是优化目标只关注 和
的相似性,假定了
和
的像素和元素是独立的,即
,是一个个像素的预测的集合。因此,这种方法会丢失建模关联和复杂结构的能力。
2、Contrasting two views:
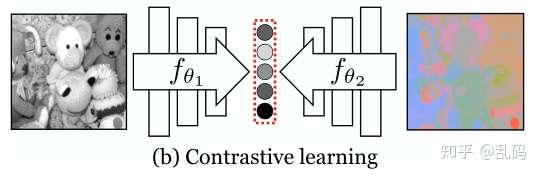
contrastive learning与Predictive learning又不同,将不同views统一映射到同一个特征空间,再利用这些embeddings进行对比学习。很直观的,丢失的细节更少,也更好进行比较。
contrastive的核心思想是分辨来自不同分布的样本。
作者将正样本对定义为来自joint distribution,定义为 。负样本对定义为来自the product of marginals,定义为
。随后,为了区分正负样本,需要训练一个函数
,对正样本打高分,对负样本打低分。作者训练该函数的方法是让函数从
,包含1个正样本,k个负样本的集合中找到那个证样本。目标函数形式化如下:
(1)
更具体的,固定一个vew,枚举其他view:
(2)
到此为止,都非常直观,只是一个标准的log-softmax。
随后,作者论证了最优解 正比于joint distribution和product of marginals的密度比:
(3)(应该是为了论证N越大,效果越好)
但是,在实际计算中,N可能是极度大的直接最小化等式(2)是不现实的。后文会提到作者是如何利用NCE来获得近似解。同时,针对两个views,很自然的将 拆分成两个编码器
和
,并抽取表征为
。额外引入一个参数
,
可以被形式化为:
或
(4)
等式2将 视为anchor, 并在
上枚举。对称的,可以通过将
视为anchor获得
。将两项加起来,获得two-view loss:
(5)
在contrastive learning阶段完成后,通过对不同views得到的表征进行综合,可以获得最终的representation。对于那些超过two-views的情况,如video,RGB-D,作者在下一节提出了新的充分利用多views信息的组合方式。
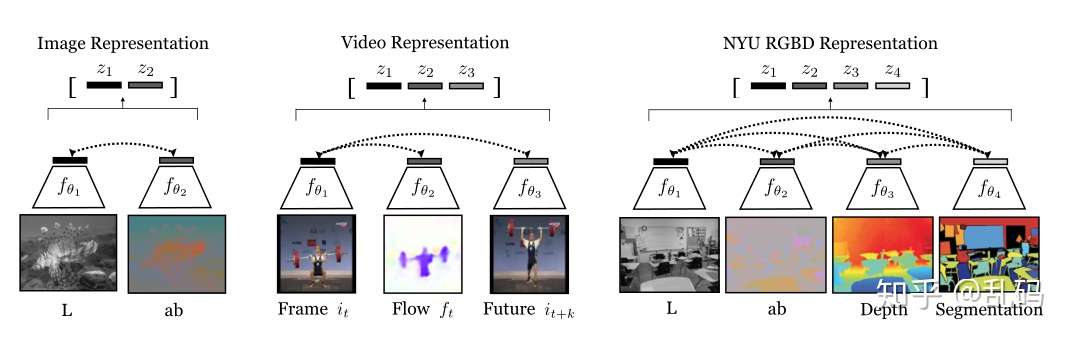
3、More than two views:
这个非常好理解。在多views的情况下,如何构建contrastive关系。第一种,core view,选取一种为anchor,枚举其他views。第二种,full graph,将多种views两两互相匹配。很明显的,full graph的交互信息更多,效果也更好,副作用是运算量也大很多。
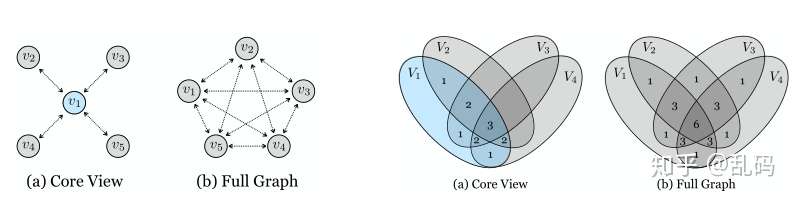
4、Connecting to Mutual Information:
重头戏来了。
其实这一系列基于contrastive learning范式的学习方法,都直接关系到对 和
的交互信息最大化。交互信息定义为:
(6)(类似于Eq.3,但是这是特征而不是样本的交互部分与不交互部分的密度比。不准确的来说,例如一个鸟的样本,那么交互信息就是证明该样本是鸟的那一部分invariance information)
直觉地,contrastive loss区分来自交互分布和边缘乘积的样本,也就能最大化它们的表征的分布的离散度(意思是这些样本编码后的特征也能被区分)。CPC证明了交互信息的边界:
(7)
其中k代表了样本集中负样本对的数量。根据Eq.3,可以得出,负样本越多,能获得更好的表征。优化目标 ,同样可以最大化交互信息的下界。不过,根据[D. McAllester and K. Statos. Formal limitations on the measurement of mutual information. arXiv reprint arXiv:1811.04251, 2018],该边界非常weak,仍然需要寻找更好的对交互信息的估计量。
5、近似估计Full Softmax:
这是所有利用基于contrastive learning和交互信息的方法都会出现的问题。Eq.2的计算量太大,尤其是在为了保证下界,负样本对数N要尽可能大的情况下。作者总结了两种tricks,分别是①使用NCE来近似模拟full softmax②使用Deep InfoMax的方法,使用子块而不是完整图像来增加每个batch的负样本数量。
5.1、leveraging NCE(leverage应该翻译成什么好啊,充分利用?)
回顾一下我们的log-softmax的优化目标,即我们要优化的概率—— 对应的
是最佳匹配的概率:
(8)
其中
当 是正样本时,要通过log-softmax优化让p最大,此时的意义就是拉近正样本对之间的距离。然而,对于大N,计算压力很大。这时候就可以用NCE。
NCE是一种有效模拟unnormalized统计模型的方法。NCE训练一个密度模型p来匹配数据分布 ,通过使用训练一个binary分类器来从噪声样本分布
中区分
的方法。(data sample:正样本;noise sample:负样本)。为了学到
,作者使用一个binary classifier,将
视为给定的
的数据样本。噪声分布
是一个对所有
元素的uniform分布,即
。如果我们对每个数据样本取样m个噪声样本,那么给定
来自数据分布的后验概率是:
(9)
通过使用模型分布 来替代
,最小化正确label D的负对数后验概率,得到NCE估计的概率函数:
(10)
为了降低运算量,作者引入了memory bank,可以从中有效检索m个噪声样本而不需要重新计算。一个针对NCE的简化方法是使用(m+1)路softmax分类器,这也是CPC和Deep InfoMax使用的。
5.2、Contrasting Sub-patches
除了使用最后一层输出的特征进行对比,还可以用中间层与最后一层的进行对比,这也是Deep InfoMax使用的方法。在这种情况下,作者使用了简单的(m+1)路softmax loss方法,不需要计算NCE,也不需要使用memory bank(直接使用一个batch中的中间变量即可)。然而,基于patch的方法对比起基于NCE的方法通常是次优的。
- 实验结果
 ImageNet上的结果
ImageNet上的结果 使用resnet在ImageNet上的结果
使用resnet在ImageNet上的结果
文章被以下专栏收录
推荐阅读
真正的无监督学习之一——Contrastive Predictive Coding
Contrastive self-supervised learning
Contrastive self-supervised learning techniques are a promising class of methods that build representations by learning to encode what makes two things similar or different.主…
一文详解最近异常火热的self-supervised learning
本文经授权转载自公众号:深度学习技术前沿 作者:Sherlock知乎链接:https://zhuanlan.zhihu.com/p/108625273【导读】最近 self-supervised learning 变得非常火,首先是 kaiming 的 MoCo …
15 条评论
所以其他图片的负对也可能是同一个class 的?
请教,不是很懂这种self suprvise的所指。难道说是学representation时是self supervise 的,然后再最后free encoder 接linear classifier 时候再supervise?如是这样,那其实比的就是所谓feature 提取能力?
请教作者:之前做过一个实验,先用tripletloss 训练一个特征提取器 然后固定特征提取器 接卷积+全连接层分类 softmax训练 但是效果是不如 直接分类的。。。
文章的意思 是不是和我这个思路一致 啊。。
遇到了类似的问题,请问最后有分析出原因吗?
从数学角度思考方法,能预知某些理论上的不work!
初接触,想问一下我这样理解对吗?:先用一个任务(这里是正负样本对比,学习样本特征),得到网络的参数(如resnet、alexnet等),然后将这个网络用到具体任务之中。如果是的话,对于CMC的预训练网络是ResNetV2还是resnet(即是l和c两部分的网络之和的encoder还是单一的l_to_ab或者ab_to_l)?