https://github.com/topics/convlstm
https://github.com/giserh/ConvLSTM-2
convlstmHere are 20 public repositories matching this topic...
pytorch implemention of trajGRU.
Using the Pytorch to build an image temporal prediction model of the encoder-forecaster structure, ConvGRU kernel & ConvLSTM kernel
雷达回波外推,ConvLSTM,训练模型并外推。
ConvLSTM/ConvGRU (Encoder-Decoder) with PyTorch on Moving-MNIST
Video Predicting using ConvLSTM and pytorch
deep-learningpytorchvideo-prediction-modelsframe-predictionconvlstmvideo-predictionpytorch-lightning
A Soccer Ball Detector using Fully Convolutional Neural Networks and ConvLSTM
Pytorch implementations of ConvLSTM and ConvGRU modules with examples
Application of LSTM network for Structural Health Monitoring & Non-Destructive Testing
computer-visiontimeseriesstructurekerascnnwaveslstmsupervised-learningclassificationdeeplearninglabelingshmultrasonic-sensorndtstructural-engineeringstructuralstructural-analysisconvlstmlambwavespzt
A repository for my pytorch models
Example Recurrent Neural Networks + LSTM (ConvLstm) for Sentiment Analysis in PyTorch
GAN based ConvLSTM in precipitation prediction (Trial Version)
Performed various Deep Learning techniques to detect Human Activity using Sequential Data detect human activities generated by sensor-based wearable devices
Next Sequence Prediction of Satellite Images using Neural Networks
Bayesian Optimization of Neural Architectures for Human Activity Recognition
Robust Lane Detection in hazy/foggy environment using Encoder Decoder CNN & LSTM and Dark Channel Prior to tackle with hazy environemnt
neural-networksimage-segmentationsegnetdark-channel-priorencoder-decoderimage-transformationsdcnnconvlstmgoogle-colabtusimple-dataset
Demonstrate time saving with GPU using tensorflow against MNIST & UCSD data
|
|
【时空序列预测第二篇】时空序列预测模型之ConvLSTM
文章首发于我的个人博客
【时空序列预测第二篇】Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting喜欢手机观看的朋友也可以在我的个人公号:AI蜗牛车 中获取,也可加微信交流。
废话不多说直接上干货
只上干货,走起来。
前言
这应该是我要写的第一篇时空序列的文章,接下来我也会一直写。 我本人对时空序列和时间序列都有极强的兴趣。
施行建博士提出的ConvLSTM应该算是非常easy或者说非常基础的模型了。 当然时空序列模型普遍没用实现很好的代码,我也在不停的修改,准备复现这些模型,共勉。
一、Address
这是nips2015年的一篇paper: https://arxiv.org/pdf/1506.04214.pdf

二、Preliminaries
2.1 降水预报问题的阐述
在这一章节,作者主要在讲这个问题到底本质上是什么问题,或者说这个问题属于什么大类?常见的对于图片来说有识别、分类、检测等等,拿降水预报问题算什么问题呢? 在真正的应用中主要是利用雷达回波图去进行降水预报,问题大多是 用以前观察得到的雷达回波图去预测将来一段时间内的雷达回波图。一般来说雷达回波图都是6min一张或者12min,(我个人接触是这样的),之后预测1-6小时固定时间的图像序列。这个实际上就是一个时空序列预测的问题。

这里肯定有朋友要问为什么要有个P,这个P的维度是干嘛的?对于雷达回波图来说每一个图片的对应像素点通过一定的变换其实是可以直接得到这个点的一些物理量的,所以这个P实际作者想说的就是这个物理量的维度。

作者在这里也对我的这个解释做了一个巩固。
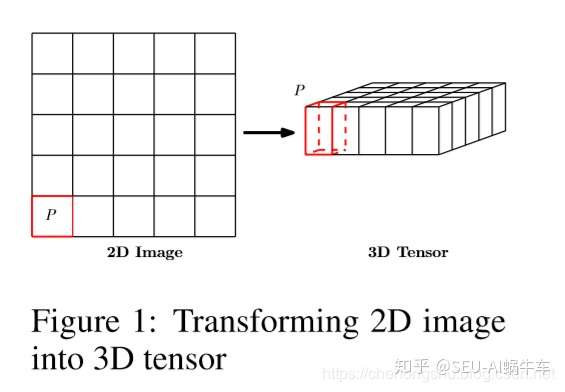
这个图形象的说明了这个问题。 这也更说明为什么利用图片直接进行时空序列预测的问题能够最终预测一个区域的降水量。

这个算是对于时空序列问题来说,比较标准的表达式了。
我发现我身边的朋友很多都以为时间序列和时空序列问题是一个问题,实则有很大的区别,作者在paper中也有提到

时空序列问题比较大的一个因素就在于数据量,直接对应的就是GPU的显存和计算力。
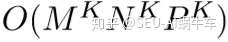
这个是他的复杂度,所以模型也在轻量级并且使整个预测问题更加简单的道路上研究着
2.2 Long Short-Term Memory for Sequence Modeling(LSTM)
首先LSTM是基础我这里默认大家都看过了,如果没看过,可以看我的其他文章补一下: 【Deep Learning】详细解读LSTM与GRU单元的各个公式和区别 【TensorFlow实战笔记】通俗详述RNN理论,LSTM理论,以及LSTM对于PTB数据集进行实战
paper中还特意说出了lstm的一个很大的优势就是在于对于序列问题来说,它很有效的避免了梯度消失问题。 以下是lstm cell的示意图。


对于FC-lstm的input为1D 数据, stacking和concatenating的结构主要是双向,多层等等LSTM的结构。
三、 the Model

我个人感觉这篇paper的最大亮点之一就是这个encoding-forecasting结构。 ConvLstm和FC-Lstm的区别主要在于 input-to-state, state-to-state的普通相乘改为卷积运算。 常用的端到端模型不过于常用于时间序列预测和NLP的seq2seq了里面采用的是encoding-decoding结构,这篇paper中而是采用 encoding-forcasting结构。
3.1 Convolutional LSTM
FC-lstm 相当于在input-to-state and state-to-state 传递的时候都用的全连接,而现在采用卷积操作,全连接意味着相当于对于整体的图像信息直接全部相乘等于一个值,这样无法对时空信息做一个提取特征的作用,而改为卷积操作即可,并且对于卷积而言,如果卷积核大,捕捉到的偏向于更快的动作,如果卷积核偏小,捕捉到的偏向于更慢的动作。

公式其实就是把input-to-state, state-to-state 的正常乘积运算,用术语叫做hadamard乘积,改为卷积运算。 对比来看更为直观
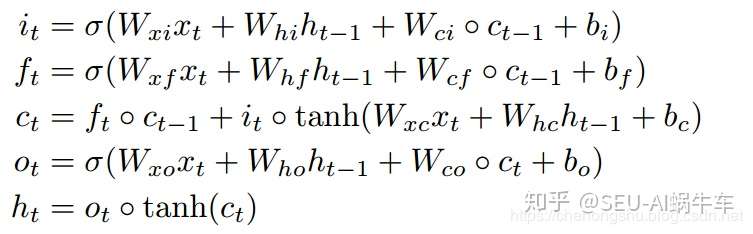
所谓文中一直提到的input-to-state 和 state-to-state主要指的是红色和紫色部分
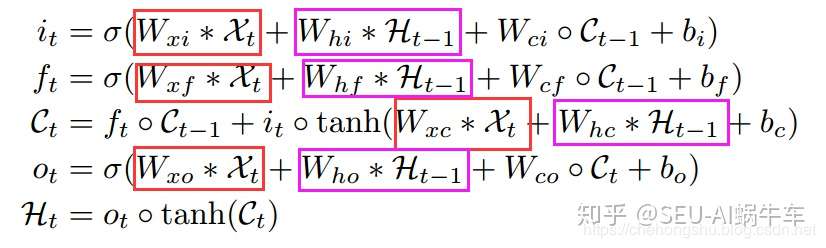
FC-LSTM其实可以看作是ConvLstm的输入和输出state以及状态h都为3D而最后两维为1而已,还有就是也可以看作是输入的全部特征全部归结于一个cell上。
下面这个结构说实话我第一次看的时候不知道他画了个什么东西。 这幅图我个人觉得这么理解是最好的理解,输入X和C(cell output)还有H(hidden state)都是三维的数据tensor。 图中 九宫格和曲线,指的是利用卷积运算通过过去一个时刻的输入和C还有H 得到新的或者说目标时刻的C和H值。

对于卷积来说为了保证输出的C和H 与 input X 保持一样的维度,需要做卷积中的padding操作,paper中对于这块有一种很奇妙的思维来说明:

文中的意思大概是 padding之后 边缘上的点可以看作是外面的点,也就是和这个事情没啥关系的点。对于zero-padding来说可以在某些时候来帮助我们一些判断,我们可以对于因为padding的点都为0,来确定边界,对于这个边界有的时候是有效的,比如我们有个墙周围的球,他肯定会来回碰撞之后来回滚,但是我们拍图片的时候序列是没有这个墙的,但是通过zero-padding相当于我们可以假设周围的边缘点就是那个墙。(其实这里就是作者来解释为啥用zero padding,他这个解释确实可以让人信服,场景找的极其恰当。)
3.2 Encoding-Forecasting Structure
首先看一下 seq2seq的encoding-decoding结构
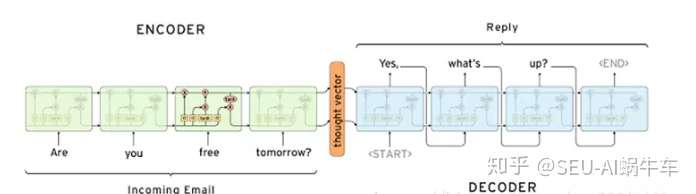
再看下这个 encoding-forcasting结构
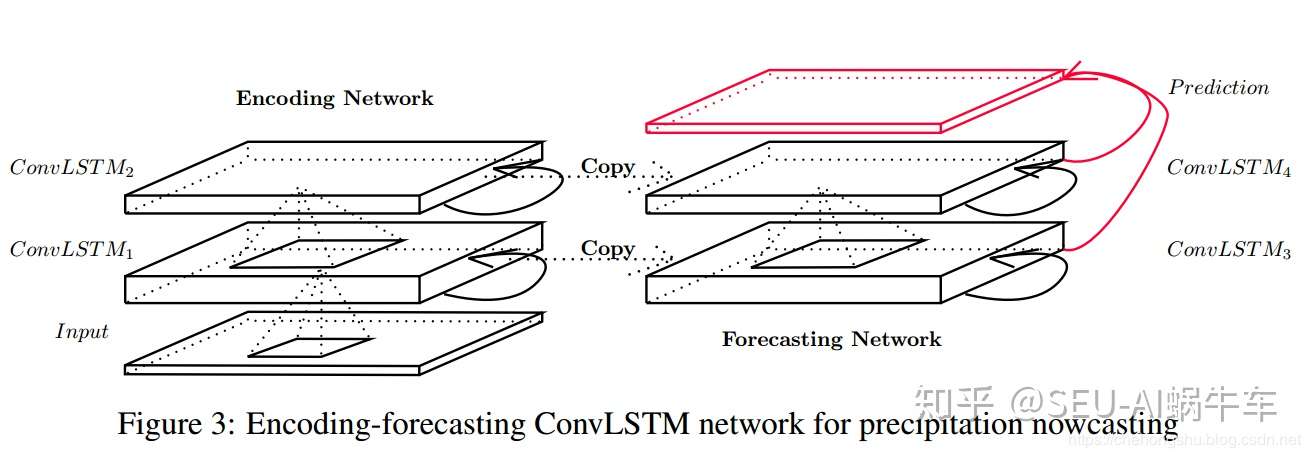
paper中着重这个结构做了一些说明:

对于encoding的输入的初始化的state为0,那decoding结构的呢?paper中很明确的说,forcasting network 的初始 cell output和hidden state 为encoding的最终的state 复制而来。 并且也说明了最后的prediction不是像 seq2seq那样decoding的每个序列的cell的输出为最终的输出,这边相当于又多做了一个把所有的输出state进行一个1乘1的卷积最终生成和输入一样维度的输出预测值。 数学表达式:从之前的标准表达式改过来的。

四、 Experiments
- 作者用当前的模型用在Mnist-Moving数据集上,并且尝试不同的stacking的层数,kernel的大小以及前面说到的out-of-domain(也就是zero-padding),来查看模型的效果
- 为了说明所提出的模型在比较难的问题上有一定的提升作用,文中主要提到的是降水预测这个方面,相当于做了一个baseline的工作,并且与降水预测的传统算法做了个对比。(采用的是前面所说的雷达回波图的数据集)

最后得到以上的结论:
- convlstm比fc-lstm在空间上处理更好。
- state-to-state上的kernel大小要大于1对于提取时空的特征是必要的
- 更深的stacking模型会更好,这个对于数据量大的数据来说普遍如此
- convlstm比传统的降水预测的方法ROVER要好
4.1 Moving-MNIST Dataset http://www.cs.toronto.edu/~nitish/unsupervised_video/
数据集为图中 有两个数字的时空序列的移动。 大小为64乘以64, 整个序列为20,前十个为输入数据,后十个为预测数据。 也就是前十个为前十个时刻的数据,后十个为后十个时刻的数据。 具体见下面的说明,很清楚,不多赘述了。

之后作者开始做了对比 所有的模型的均采用cross-entropy交叉熵作为损失函数,用的optimizer为RMSProp, 学习率为0.001并且有0.9的延迟率,并且我们在validation set上采用了 early-stopping整个操作,整体说实话训练的方式是非常传统并且正常的。 这里还有个很骚的操作,作者设置一个patchsize,把64乘64的矩阵转换为16乘16乘16的tensor,这个操作我在很多代码中看到了,算是一个时空序列训练的一个小trick把,为什么要这么做,目前我还不是从机理上能够很清楚的明白。

接下来是训练的结果表格

每个模型不管是多少层的,input-to-state的kernel size都为一致的,只有每层的state-to-state的kernel size在变,以及 hidden state的大小在变。

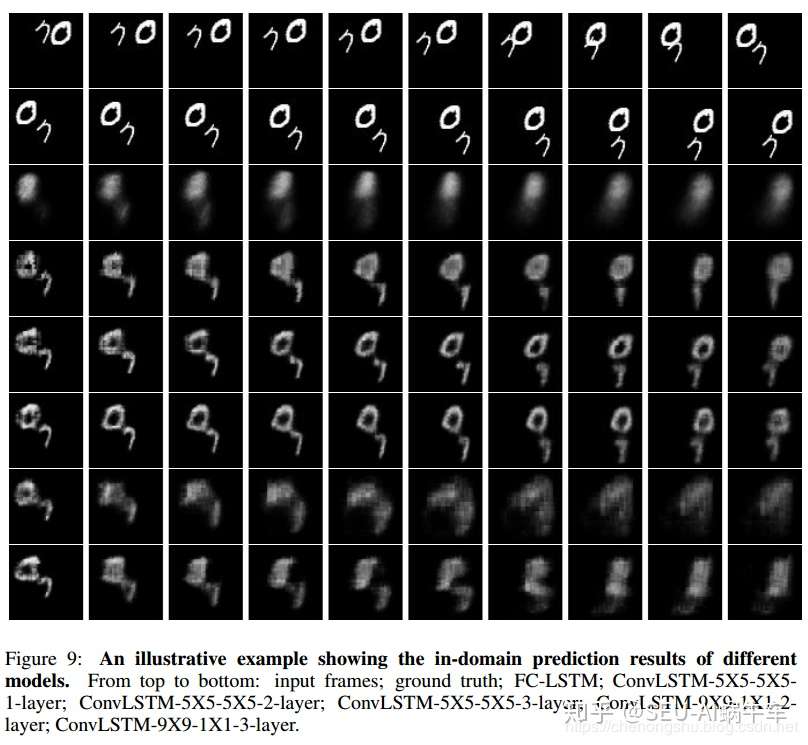
但是效果可以看到还是依然很差的,说实话这个想做好确实难度很高,因为数字在图中极度的非线性运动,很难全部学到运动的规则,就算是学到了,单个字的空间信息可能也会丢失,所以越往后效果越差。

上面这幅图不是作者做的一个附加的实验,这个图主要是针对前面所说的out-of-domain来说的,就是说作者用两个数字的数据集去训练模型,最后来预测图片中带有三个数字的图片序列,来测试模型的泛化性,我觉得写的恰到好处。
通过这个实验图,实验中主要得出以下几个结论:
- Convlstm的效果比fc-lstm的效果好
- 更深的网络会更好,但是两层和三层差的不多
- 1乘1的state-to-state kernel size很难抓住时空移动的特征,所以效果差很多,所以更大的size更能够获取时空的联系
4.2 Radar Echo Dataset
这才是这篇paper的最大亮点,用在雷达回波图上,做一个降水预测的应用。 选的数据集为三年的HK的回波图,因为降水问题很特殊,不是每天降水,如果一起使用会出现啥问题呢?? 就是说可能百分之90都是无雨的情况,最后会出现无雨的全是黑的图片为主要的图片,那模型训练起来会出现把降水当作噪声或者负样本的情况,或者说主要的样本严重失调,很难训练出一个正常的模型,所以作者采用降水量最高的97天作为训练数据。

首先做了个预处理,其实就是 归一化,之后扣了330乘330的图,最后resize为100乘100。 之后作者利用kmeans对图片的每月平均像素做了一下聚类,把噪声区域的像素值也去掉了,相当于去噪操作。 雷达回波图一般都是6min或者12min一次,如果6min一次的话,一天240帧。 此时此刻240乘97数据量依然很少怎么办,因为我们是序列问题,所以采用滑窗的方法来增强序列次数,paper中用窗口大小为20的方法来获得不重叠的序列block,我们把每天的序列分成40个不重叠的block,随机分配四个block作为训练集,一个为测试集,一个为验证集。全部的block都是20的长度,5个为输入,15个为预测。
最后做了个对比实验,和最传统的光流法进行对比,也对比了FC-LSTM。
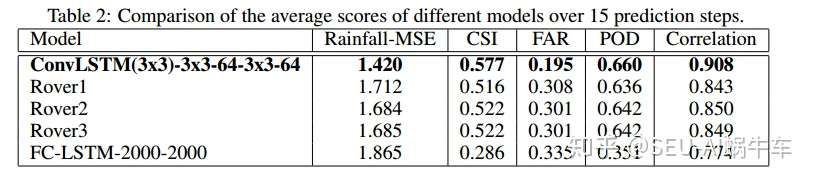
后面的CSI FAR POD Correlation等都是对于天气中的一些重要指标或者说常用指标。

这几个指标和ROC那几个指标基本上一个意思,只是不同的领域不一样而已。 这几个具体怎么算呢? 方法是,首先把像素点转换为雷达回波图的雷达反射率的值,之后通过ZR变换,转换为降水量,之后通过阈值把整个降水量的矩阵转换为0-1矩阵,之后与label的0-1矩阵进行比较来计算这些值,推荐看paper中的详细说明更为具体,我只是说了一下框架。

table2的训练指标图
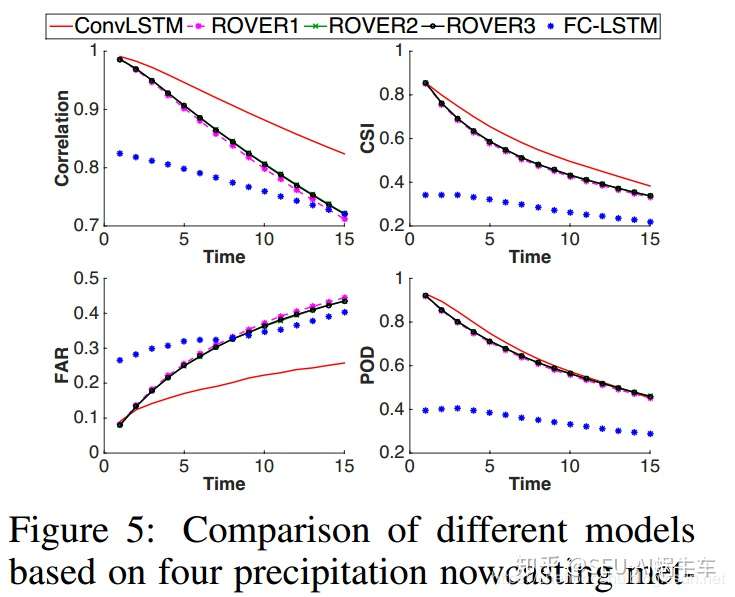
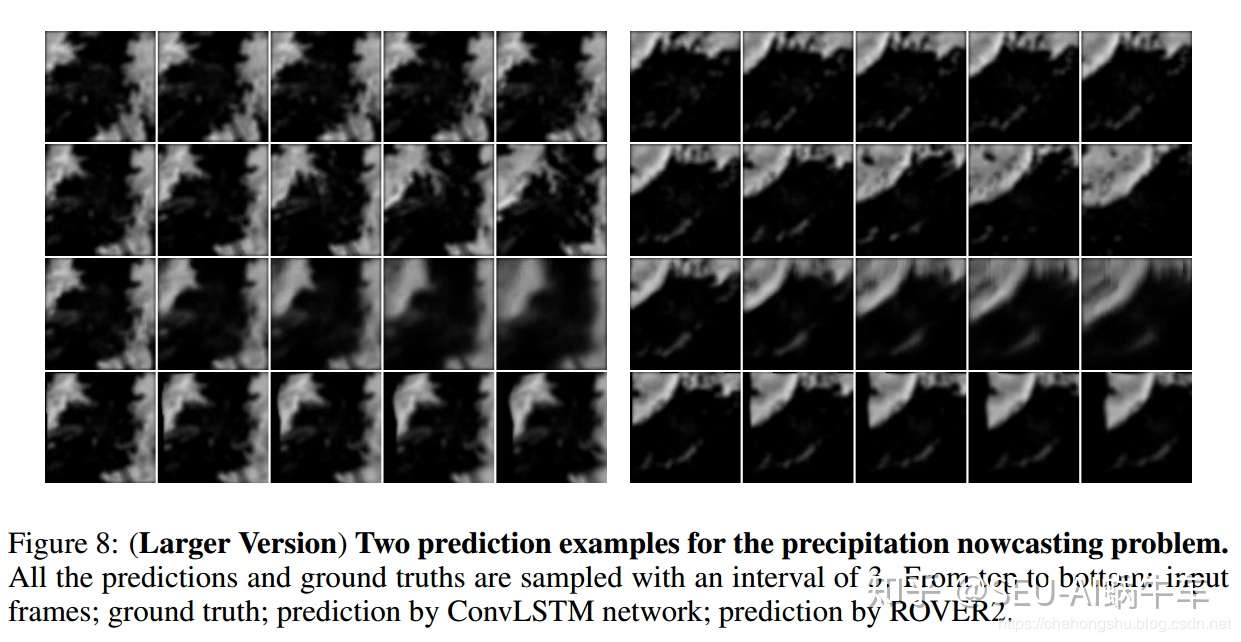
ROVER2与ConvLSTM的对比预测图。 最后作者总结了一下这个实验室的结论: 1. FC-LSTM效果还是很差,没有ConvLSTM好 2. convlstm比传统的光流法optical flow要好,主要是两个原因:一个为convlstm能够更好的处理边缘,也就是上面所说的out-of-domain的能力,更泛化,对于降水的场景,会在边缘突然出现有雨等等,另外convlstm的encoding-forcasting为端到端的结构,更为便于使用
五、 Conclusion and Future Work

多余不赘述了。就是感觉他这里讲的这个idea还蛮有趣的。
六 、个人总结
以上都为 本作者的理解,如有疑问和其他看法欢迎加我的微信和我交流,互相学习。
这篇paper看似简单,最主要的几个点:
- 提出了convLSTM
- 提出了encoding-forcasting
- 提出了把深度学习这些模型应用到降水预测中, 并且相当于给予了一些思路和baseline
- 强调了out-of-domain这个方面以及整个方面在实际应用中的重要性
字码完了,温故而知新,也希望您学到东西。